

转载自 http://download.csdn.net/source/858994
源地址下是 Word 文档,这里转换成HTML 格式
3.3.6 Term向量文件
Term向量(vector)的支持是field基本组成中对一个field来说的可选项,它包含如下4种文件:
1. 文档索引或.tvx文件:对每个文档来说,它把偏移(offset)存储进文档数据(.tvd)文件和域field数据(.tvf)文件
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TVXVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
|
DocumentPosition |
NumDocs |
UInt64 |
在.tvd文件中的偏移 |
|
|
FieldPosition |
NumDocs |
UInt64 |
在.tvf文件中的偏移 |
结构如下图所示:
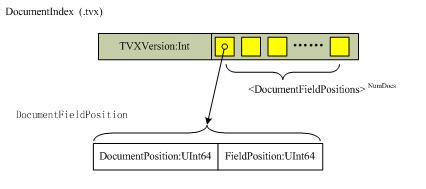
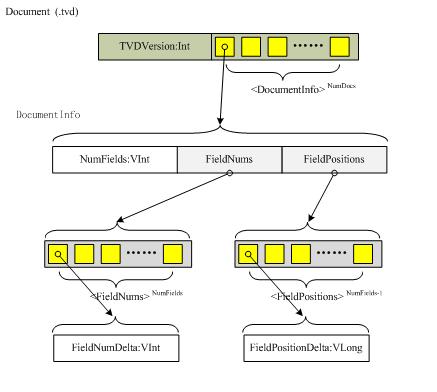
2. 文档或.tvd文件:对每个文档来说,它包含fields的数目,有term向量的fields的列表,还有指向term向量域文件(.tvf)中的域信息的指针列表。该文件用于映射(map out)出那些存储了term向量的fields,以及这些field信息在.tvf文件中的位置。
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TVDVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
|
NumFields |
NumDocs |
VInt |
|
|
|
FieldNums |
NumDocs |
FieldNums |
|
|
|
|
FieldNums->FieldNumDelta |
NumFields |
VInt |
|
|
|
FieldPositions |
NumDocs |
FieldPositions |
|
|
|
FieldPositions->FieldPositionDelta |
NumField-1 |
VLong |
|
结构如下图所示:
3. 域field或.tvf文件:对每个存储了term向量的field来说,该文件包含了一个term的列表,及它们的频率,还有可选的位置和偏移信息。
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TVFVersion |
1 |
Int |
在Lucene 2.4中为3 (TermVectorsReader.FORMAT_VERSION2) |
|
NumTerms |
NumFields |
VInt |
|
|
|
Position/Offset |
NumFields |
Byte |
|
|
|
TermFreqs |
NumFields |
TermFreqs |
|
|
|
TermFreqs->TermText |
NumTerms |
TermText |
|
|
|
TermText->PrefixLength |
NumTerms |
VInt |
|
|
|
TermText->Suffix |
NumTerms |
String |
|
|
|
TermFreqs->TermFreq |
NumTerms |
VInt |
|
|
|
TermFreqs->Positions? |
NumTerms |
Positions |
|
|
|
Positions->Position |
TermFreq |
VInt |
|
|
|
TermFreqs->Offsets? |
NumTerms |
Offsets |
|
|
|
Offsets->StartOffset |
TermFreq |
VInt |
|
|
|
Offsets->EndOffset |
TermFreq |
VInt |
|
结构如下图所示:

备注:
l Positions/Offsets 字节存储的条件是当该term向量含有存储的位置或偏移信息时。
l Term Text prefixes文本前缀是共享的,表示根据前一个term的文本来初始化的字符串前缀长度,前一个term必须已经预设成后缀文本以便构成该term的文本。比如,如果前一个term为“bone”,而当前term为“boy”,则该PrefixLength值为2,suffix值为“y”。
l Positions存储为Delta编码的VInts,意思是我们只能存储当前位置与最后位置的差值。
l Offsets存储为Delta编码的VInts,第一个VInt是startOffset,第二个VInt是endOffset。
3.3.7 删除的文档 (.del)
删除的文档(.del)文件是可选的,而且仅当一个segment存在有被删除的文档时才存在。即使对每一单个segment,它也是维护复合segment的外部数据(exterior)。
对Lucene 2.1及以前版本,它的格式为:Deletions (.del) –> ByteCount,BitCount,Bits
对2.2及以上版本,格式如下:
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
2.2之后版本 |
[Format] |
1 |
UInt32 |
可选,-1表示为DGaps,非负数(negative)值表示为Bit,并且此时不存储Format |
|
ByteCount |
1 |
UInt32 |
代表Bit里的字节数目,而且一般值为(SegSize/8)+1 |
|
|
BitCount |
1 |
UInt32 |
表示Bit里当前设置的字节数目 |
|
|
Bit|DGaps |
1 |
|
Bit还是DGaps取决于Format。Bits中对每一个索引的文档均包含一个字节,当一个bit对应的一个文档编号被设置时,表示该文档被删除。Bit从最低(least)到最重要(significant)的文档排序。所以Bits包含两个字节,0×00和0×02,则文档9被标记为删除。DGaps表示松散(sparse)的bit-vector向量比Bits更有效率(efficiently)。DGaps由索引中非0的Bits位生成,以及非0的字节数据本身。Bits中非0字节数目(NonzeroBytesCoun)不会存储。 |
|
|
Bit->Byte |
ByteCount |
Byte |
|
|
|
DGaps->DGap |
NonzeroBytesCount |
VInt |
|
|
|
DGaps-> NonzeroBytes |
NonzeroBytesCount |
Byte |
|
结构如下图所示:

举例来说,如果有8000 bits,并且只有bits 10, 12, 32 被设置,DGaps将会存储如下数据:
(VInt) 1 , (byte) 20 , (VInt) 3 , (Byte) 1
3.3.8 局限性(Limitations)
有几个地方这些文件格式会让terms和文档的最大数目受限于32-bit的大小,大约最大40亿。这在今天不是一个问题,长远来看(in the long term)可能会成为个问题。因此它们应该替换为UInt64类型或者更好的类型,如VInt则没有大小限制。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· [AI/GPT/综述] AI Agent的设计模式综述