
Improving Zero-Shot Coordination Performance Based on Policy Similarity 2023-ICAPS
基于策略相似度的零样本协调表现改进
总结:
- 这篇论文本质上是研究智能体的泛化性能,文中涉及的问题是在一个常规多智能体系统中的智能体如果要与新加入的或者说没有交互过的智能体一起训练的协调能力比较差,从而导致合作程度不够影响收益。文章针对这个问题先是研究了影响智能体协调能力的参数之后利用该参数采取特殊的具有鲁棒性的训练方法来解决上述问题。
实验环境:
- Hanabi:一个纸牌游戏,简单来说有五种颜色的牌,每个颜色的牌有1-5五张,初始每个人五张牌,游戏目标需要按特定顺序出牌获取高分。每个人都可以看到任何一个人的牌,存在特定指令的牌,打出去特定的队友就需要出特定的牌从而得分,出错则得到惩罚。在这样的情境下,如果是熟悉的队友则可以采取一些暗号,陌生的新队友则不行这就是所谓的协调能力。
具体研究内容:
- 先是对影响因素进行研究:
- 定义与常规伙伴训练的价值函数
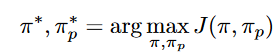
- 定义与陌生智能体的价值函数
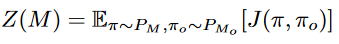
其中M是训练框架,带标识的是陌生框架 - 定义Conditional Policy Similarity(策略相似度),文中进行猜想如果一个智能体遇到的陌生智能体和原先伙伴智能体的策略相近那么协调性能也会很好,因此提出该衡量尺度
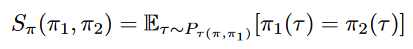
具体实现采用蒙特卡洛方法对两条训练轨迹进行估计
- 定义与常规伙伴训练的价值函数
- 之后针对上述提出的CPS参数进行实验,验证其与交叉训练最后得分的关系
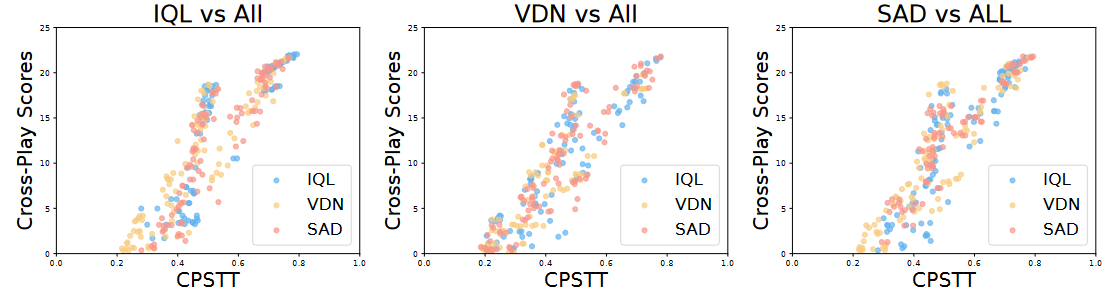
发现得分与相似性呈线性关系 - 基于上述结果可知,想要提高最后的分数,较好的方案是提高策略相似性,但是对于未知的智能体显然是无法实现的,因此将采用固定策略相似性进行以提高游戏分数的训练,这就是本文提出的解决方法。
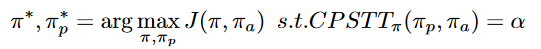

 浙公网安备 33010602011771号
浙公网安备 33010602011771号