
《PROMOTING COOPERATION IN MULTI-AGENT REINFORCEMENT LEARNING VIA MUTUAL HELP》 2023-IEEE
通过互相帮助促进多智能体强化学习中的合作
总结
- 该篇文章主要是提出了一个新的多智能体强化学习算法,目的是为了提高合作程度和总社会奖励。具体实现基于传统Actor-Critic模型,添加了一个预测动作模块让智能体基于预测其他智能体的动作来进行下一步动作,达到不损害自身利益的前提下有选择的互相帮助促进合作。
实验环境
- Flocking Navigation Enviroment(FNE):集群导航环境,智能体需要导航到目标区域,同时保持个体之间无碰撞,这是一个需要高度合作的任务,因此智能体需要精确控制它们之间的距离避免碰撞和破坏群集
具体实现
-
MADDPG算法:该算法是基于DDPG算法对应于多智能体协作环境的版本。其中每个智能体都有一个Actor和一个集中训练的Critic神经网络,用于学习动作策略和价值函数。算法在计算Critic网络的目标值时会考虑其他智能体动作对当前智能体的影响。
- Actor网络接收当前状态作为输入,输出当前智能体的动作
- Critic网络接收所有智能体的状态和动作作为输入,输出所有智能体的价值函数估计值
- 对于每个智能体,训练过程中从经验池中取一部分数据,Actor网络的目标是最大化Critic网络输出的价值函数值,同时Critic网络的目标是最小化预测值和真实值之间的误差
-
MH-MADDPG:将其他智能体动作作为输入,达到接收其他智能体行动影响的效果。具体来说每个智能体需要维护一个期望动作模块来生成期望的其他智能体的动作
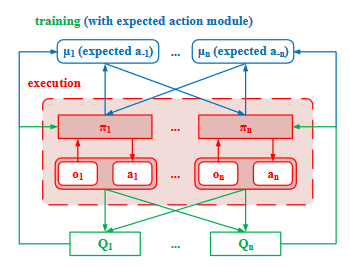
- 不断从经验池中获取数据训练Q函数,这样随着Q值不断向最佳靠近那么期望动作函数也会越来越精确
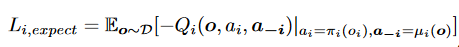
- 利用生成的预期行动促进合作:例如智能体i想要去帮助智能体j那么智能体i就要模仿智能体j生成的期望其他智能体采取的动作:
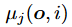
- 但是不设限的进行模仿(通过最小化自身动作和预期动作之间的差异来实现)可能会损害自身的利益,因此要求在不对自身利益有大影响的情况下进行模仿,这就要求最小化以下函数
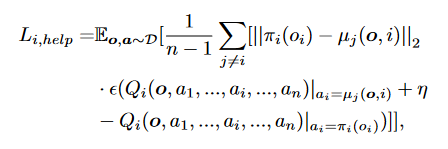
即在模仿的同时最小化价值差异,同时用到一个比较函数,如果模仿后自身Q值变小则不进行模仿:
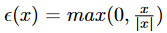
- 最后合成总得损失函数
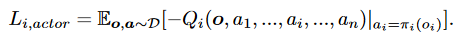
- 不断从经验池中获取数据训练Q函数,这样随着Q值不断向最佳靠近那么期望动作函数也会越来越精确
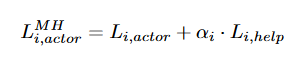
即要做到最大化自身收益的同时尽最大可能帮助其他人。(混合参数的作用是将两个损失函数调整到同一量级)
- 算法伪代码如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号