
《Learning Reciprocity in Complex Sequential Social Dilemmas》 2019-arxiv(未收录)
在复杂序贯社会困境中学习互惠
总结
- 这篇论文主要是提出了一个在线学习的模型展示如何在序贯困境中学习互惠行为,模型包括创新者和模仿者两种代理。
- 相比于传统的Tit-for-Tat的互惠模型,其优点在于不再是简单的模仿二元动作合作和背叛,可以扩展到多人困境中不局限与二人囚徒困境
实验环境
- Harvest、Cleanup
- Coins game
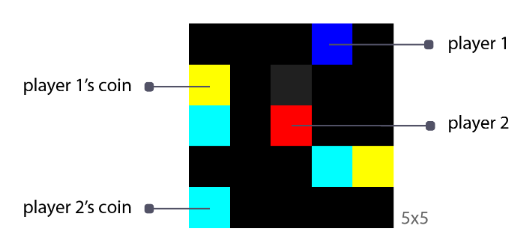
收集到自己对应颜色的硬币或者奖励1,收集到另一个玩家的硬币,则另一个玩家获得-2奖励
研究方法
- innovator:创新者,在社会中对应领导者,一般在困境中仅存在一个,其仅采用Actor-Critic算法用观察到的环境奖励进行训练
- imitator:模仿者,算法与架构与创新者相同,通过计算与创新者之间的好感度进行匹配模仿或者通过指定的衡量指标(手工控制,失一般性)因此分为两种变体:度量匹配以及好感度网络
- 额外有内在奖励,定义为:
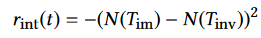
其中T代表轨迹,r表示创新者在某个时间步的影响力
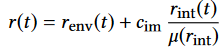
进行归一化处理,c代表超参数,μ代表某个批次的影响力总和 - Metric matching变体与Niceness network变体主要区别在于N(·)函数的不同,前者通过手工指定具有稳定性,后者通过训练更具有一般性
- Niceness network具体的实现方式为估计创新者执行某个动作对模仿者地影响力来定义N(·)函数

V(t)定义为某个时刻模仿者模仿创新者得到的收益
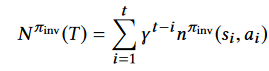
一条轨迹的N函数则定义如上
- 额外有内在奖励,定义为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号