
《Towards Cooperation in Sequential Prisoner’s Dilemmas: a Deep Multiagent Reinforcement Learning Approach》 2018-arxiv(未收录)
致力于序贯囚徒困境中的合作:一种多智能体深度强化学习的方法
总结
- 主要是针对复杂的序贯囚徒困境的合作提出的方法,目的是为了提高合作程度最终达到提高社会总收益的。该方法主要包括两阶段,第一阶段是离线生成策略阶段,运用普通的强化学习算法先单独计算每个智能体的策略之后整合,其中智能体的策略不是简单的非合作即背叛而是通过参数将二者合成;第二阶段是在线阶段,通过预测对手的策略,自适应选择最合适的策略。最后通过几个实验验证提出方法的优越性。
- 创新点:相对于传统方法能够更好的适应复杂的困境更符合现实;具有一定的鲁棒性能够在适当时候选择背叛而避免被利用;提高了合作的程度增加了收益。
实验环境
- 水果收集游戏(Harvest)
- 苹果梨游戏(Apple-Pear)

蓝色代理偏好苹果,红色剂偏好梨。每个智能体有4个动作:右移、左移、后移、前移,每移动一步需要花费0.01的成本。当代理踏在与其相同的正方形上时收集果实。获取对应的果实奖励1,不是对应的则奖励0.5.背叛是当奖励大于移动消耗时,同时收集两种水果;互相分享一个水果会获得奖励的一半;完全合作是互相采摘自己对应的水果最大化社会收益。
研究的方法
- 首先是各自训练不同合作程度的基线策略
- 训练不同合作程度的策略采用调整收益成分
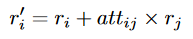
attitude代表i对j的态度,范围为0-1,值越大训练得到的i的策略合作程度越高:理由是考虑了其他人的奖励,比重越大就会越偏向合作使得考虑的其他人奖励大一点 - 由于独自训练的效率较低,提出了JAC(joint-Actor-Critic)的方法即联合训练,共享底层网络参数提高效率
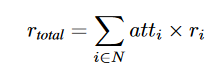
attitude参数代表自己在团队的重要程度,值越小学习到的策略合作程度越高,因为整体合作程度越高收益才会越高 - 由于不同合作程度的策略在某种程度来说是无限多的,计算量十分庞大,因此只计算单纯的合作和背叛其他用这两个基础策略合成
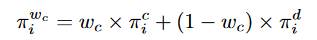
参数代表代理i的合作度
- 训练不同合作程度的策略采用调整收益成分
- 为了检测对手的合作程度,提出了基于LSTM的合作度检测网络:具体来说使用前述生成的各种不同合作程度的策略的动作集作为数据集来训练这个检测网络
-
在每个时间步t,智能体i用智能体j的前n-1步动作预测到其合作程度,并进行平滑处理防止随机产生的误差
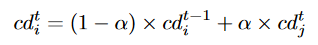
-
最终智能体i基于上述得到的当前时间步t的合作程度加上一个自身互惠水平(任意正值)得到一个当前合作度,要大于对手j并用于前面的策略更新过程
-
- 算法流程如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号