
《Adaptive Incentive Design with Multi-Agent Meta-Gradient Reinforcement Learning》 2022-AAMAS
多智能体元梯度强化学习的自适应激励设计
总结:
提出了一种基于元梯度的多智能体强化学习自适应奖励机制,解决了较为复杂的多智能体强化学习下的奖励机制问题,最终证明该方法可以收敛至已知的全局最优解。
环境:
- Escape room、Cleanup
具体实现过程:
- 本质上是解决双层优化问题
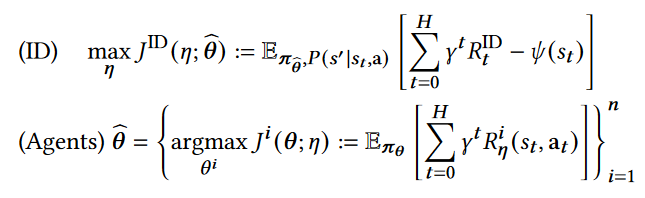
在理想情况下一般处理过程是先固定激励函数的参数,然后先求解策略参数,最后用更新后的策略得到的样本来更新激励函数参数,但是这样的过程对样本数量要求较高,效率低。于是提出了元梯度方法,主要是基于在线交叉验证,不等智能体完全收敛而是直接使用过程轨迹更新激励函数的参数 - 策略参数更新
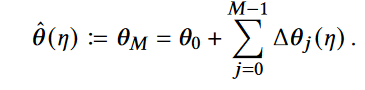
- 算法伪代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号