
《Social Diversity and Social Preferences in Mixed-Motive Reinforcement Learning》 2020-AAMAS
混合动机强化学习中的社会多样性与社会偏好
总结:
本质是在研究当智能体群体中的个体具有独特性质时在困境强化学习中对结果的影响。提出了一个社会价值偏向取向的概念来使得群体中的智能体异质之后进行对比实验,实质上还是对奖励函数的更改,但是奖励函数具有多种形式,不是具体的。
环境:
- Harvest Patch:每一轮初始都有随机出现的Apple Patch代表一个局部区域,里面的再生苹果也不会超出这个区域,区域内所有苹果被收集完就不可逆(再生率取决于半径内的苹果数量,没有苹果则不会再生)。困境在于,如果还剩下最后一个苹果,是否会有人为了眼前的利益直接获取还是放在那等他重生,这样群体就会有更大的收益。智能体具有惩罚能力,惩罚代价-1,被惩罚者-50。
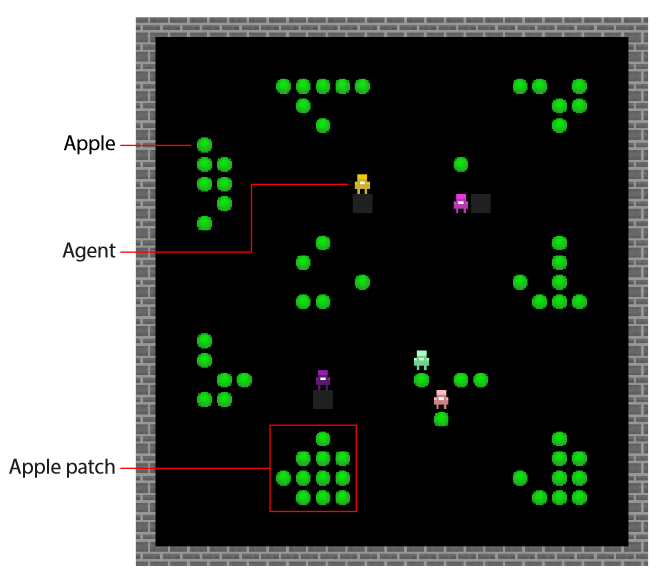
- cleanup环境
具体实现:
- 同质性和异质性:
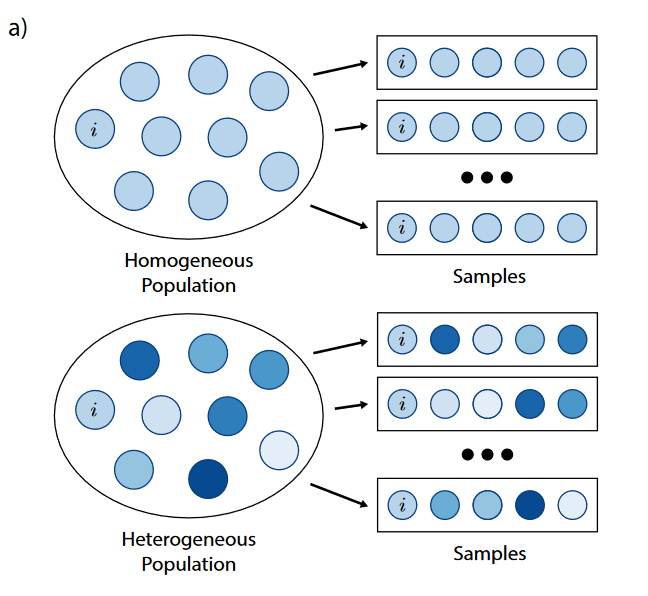
群体同质性和异质性导致给定个体i的培训经历不同。在同质情形下,代理人政策要么相同,要么非常相似。在异质环境中,给定的智能体i随着时间的推移会遇到一系列的群体组成。政策的多变性可能源于不同分布或不同动机下的代理人培训。 - 社会多样性,个体的不同:合作偏向性的个体和竞争偏向性的个体
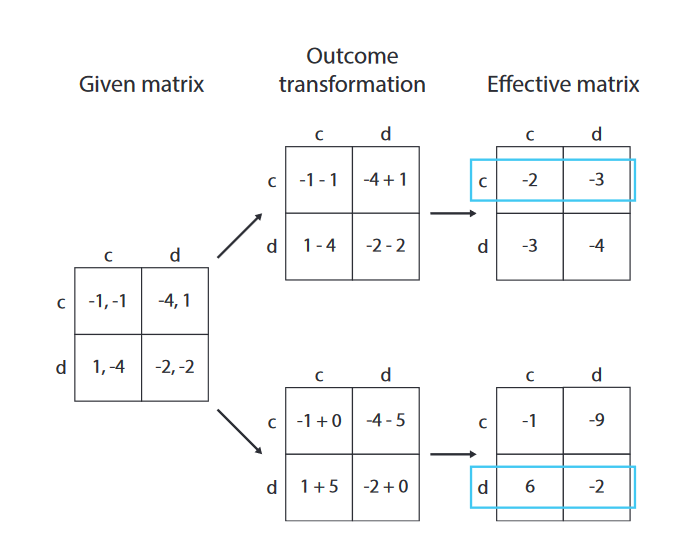
上面是合作的变形,考虑了他人的奖励,下面是竞争个体奖励变形,则是考虑了与他人之间的奖励距离 - Social Value Orientation
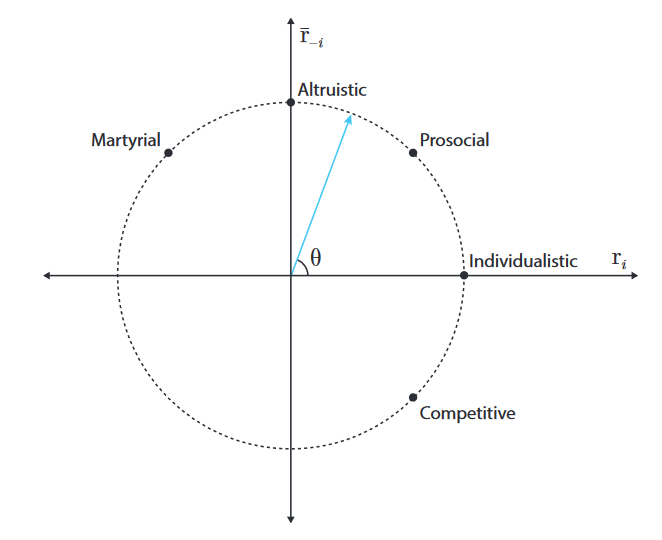
初始的角度θ会影响后续代理的奖励效用值,实际上就是决定代理的偏好问题 - 奖励结构:
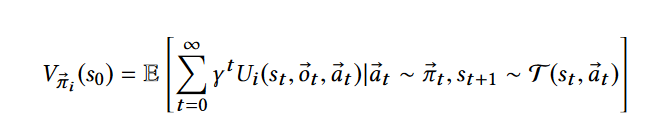
状态价值函数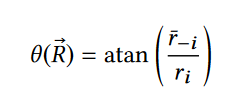
训练过程得到的价值取向的角度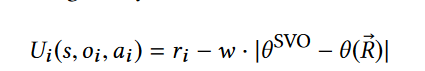
效用值计算,最终使用A2C算法训练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号