
《Emergent Cooperation from Mutual Acknowledgment Exchange》 2022-AAMAS
从相互交换确认中产生合作
总结:
-
为了改进传统的激励其他代理人机制,其存在隐私侵犯的问题,文中提出一种两阶段的请求和回应机制,即即使想要激励其他人送出的东西还需要得到接收方的回馈,接收方通过一个判断函数决定是否接收,接收则回馈同等奖励,不接受则回馈等绝对值得负面奖励。通过这样一个通信机制解决信息暴露问题以及之前激励机制的扩展局限性。
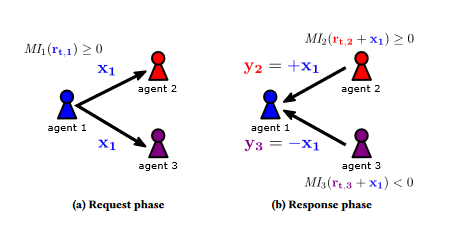
-
存在改进点:本篇中的奖励是固定值,作者提到需要更多关注于这个机制本身,但是奖励的多少实际上还是会对结果产生影响的,自适应奖励是一个改进点。
环境:
- Harvest、重复囚徒困境
- 寻找硬币游戏
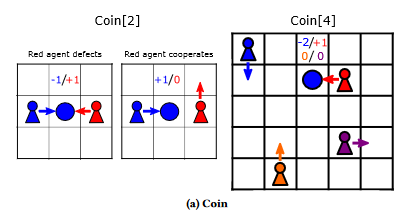
随机位置,硬币随机颜色随机位置,获取自身相同颜色硬币奖励+1,获取与他人颜色相同硬币对应颜色的人获得-2奖励,下一个时间步硬币重置
具体实现:
- 一些参数:
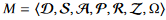
分别代表智能体合集、状态集、动作集、转移函数、奖励集、局部观察信息、观察子集
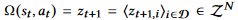
执行动作后的经验元组:
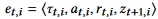
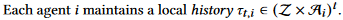
- 算法一伪代码:

初始化策略和状态价值函数,之后每个智能体选择动作并更新经验元组用于后续的策略和价值函数更新(试错过程)实际上就是一个强化学习的探索更新过程;过程中有一个奖励的更新机制,采用了请求回馈机制进行更新,在后续的算法2中 - 单调提升(概念):一个判断机制,判断当前智能体的收益是否处于一个稳步向好的状态,用于通信过程的决断,大于0代表在提升可以继续鼓励其他智能体,等于0代表当前的状态处于稳定的合作状态需要保持不向背叛靠拢,小于0则代表要惩罚其他智能体通过通信机制的负反馈
- 局部可靠性度量

其中第一项是一个任意量,可以是初始的奖励r或者是一个特定的值

上面是两种形式的度量,都仅仅取决于局部信息,不用像传统激励机制那样需要知道全局信息 - 奖励随着通信机制更新:
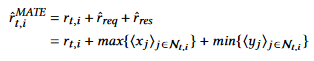
分别取收到请求的最大值和收到的反馈的最小值(之所以这样作者说是类似比赛里面取最高分和最低分排除不公平性)
算法如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号