
《Learning to Incentivize Other Learning Agents》2020-NIPS
学会激励其他学习智能体
总结:
- 为了促进在一般和马尔可夫游戏中的多智能体之间的合作,为每个智能体配置一个奖励函数用来直接向其他智能体提供奖励,并明确解释接受该奖励者自身行为会受到的影响。该奖励函数会根据提供的奖励对其他智能体的产生的影响以及后续其他智能体对自己获取的环境奖励的影响来不断学习。使用该机制来刺激合作达到较高的群体收益。
- 创新点:保持分散式训练解决大规模问题的同时保证了合作高收益,奖励函数自适应学习而非事先制定
- 代理人学习包括两部分:
- 学习一个使其获得的外在奖励和激励总量达到最优的策略(强化学习)
- 学习一个改变其他代理人行为从而使自身外在目标达到最优的激励函数(外在目标奖励的梯度上升方法)
环境:
- 理想化模型,即每个智能体拥有其他智能体的参数和梯度
- Escape Room game:(N,M)共有N名玩家,至少有M名玩家合作拉杆才能开门离开密室,拉杆的玩家会获得-1的奖励,如果没有达到M则所有玩家获得-1奖励;成功打开门则没有参与拉杆的玩家获得+10奖励。
- 重复囚徒困境
- cleanup环境
具体实现:
- 奖励函数
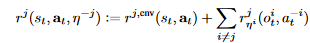
包含环境奖励和其他代理给予的激励奖励,-i代表除了i以外的其他下标 - 价值函数
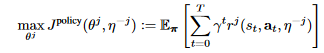
最终目标是最大化价值函数 - 更新参数
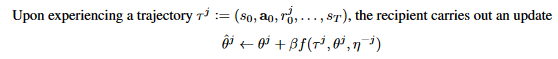
由上面价值函数学到的策略得到一条轨迹,用来更新策略网络的参数
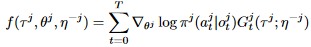
之后得到新的策略网络,同时有一条新的轨迹用来更新激励函数的参数
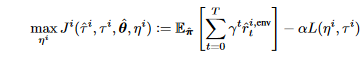
后面一项代表奖励别人所付出的代价
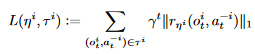
由上面两个过程不断迭代至收敛 - 算法伪代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号