
《Consequentialist Conditional Cooperation in Social Dilemmas with Imperfect Information (Short Workshop Version)》2018-ICLR
环境:
- Fishery:湖两岸有两个钓鱼人互相观察不到对方的动作,湖里有幼鱼和成熟鱼奖励分别为1和2,鱼游到对岸变成成熟鱼。合作方案即将幼鱼放给对岸,背叛即被诱惑吊幼鱼。
- Pong Player's Dilemma(PPD):乒乓球比赛,赢者得一分,输者扣两分。合作行为即不进行比赛。
- PPD升级版:输者以概率p失去2/p分
- 游戏都是假设成可遍历的,并且部分可观察环境
创新点:
- 根据过去的奖励调节代理动作构建策略(结果条件依赖的社会困境)
- 使用深度强化学习,卷积神经网络,输入状态输出动作概率分布,下面是两个代理情况下的模型定义:
- 输入观察到的状态输出动作概率分布
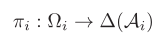
- 代理的期望收益,给定初始状态和策略对
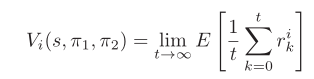
- 最优策略定义:
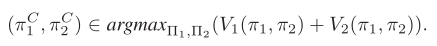
- 根据初始状态使用策略梯度方法学习出两种策略,一种是πc代表合作策略(这边采用了类似Prosocial训练方法,考虑其他人奖励),一种πD代表背叛策略即自私的,只考虑自身奖励
- 计算每个批次的奖励阈值
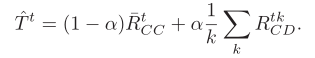
高于阈值选择合作策略,低于阈值选择背叛策略,RCC代表合作收益而RCD代表一个合作者一个背叛者收益即策略的不同,k代表迭代次数,t代表时间帧 - 算法伪代码:

- 输入观察到的状态输出动作概率分布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号