
《Prosocial learning agents solve generalized Stag Hunts better than selfish ones》 2018-AAMAS
环境:
- 猎鹿博弈(即代理人要么选择有风险的合作政策,单独代理人选择会导致低收益;要么选择一个安全的合作政策,无论怎么样都会有安全收益)存在多个纳什均衡的环境

h > c >=m > g
创新点:
- 目标:最终收敛到狩猎均衡获得更高收益,而不是低收益的均衡
- 采用亲社会代理人机制,代理人考虑伙伴的奖励采取动作
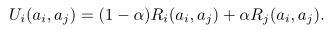
其中参数代表代理人的亲社会水平,当参数超过临界值后可以逐渐增加收敛后的社会总收益(定理) - 设计出发点:假设每个代理人都有一个信念值p代表期待伙伴选择狩猎的概率,代理人之间会对这种信念值做出回应,如果伙伴选择了狩猎,那么p值就会上升。
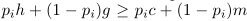
由此可以找到p的临界值

- 适用环境有限,如果不是类似猎鹿博弈的环境中,可能会收敛到次优解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号