
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning(2019-ICML)
背景及相关问题:
- 多代理的学习中,通过奖励代理对其他代理产生的影响,可以增进多代理在强化学习中的合作和沟通。之前在MARL环境中关于紧急通信的方式无法以分散的方式学习各种策略,而使代理能够通过深度神经网络学习其他代理状况的模型可以用离散的方式计算所有代理的影响力奖励。(强化学习的内在动机问题)
- 之前的促进代理之间合作的方法包括使用紧急通讯协议,但是想要得到一个紧急通讯协议是十分麻烦的
创新点:
- 通过强化学习的方式学习观察其他代理的状态可以减少依赖环境、访问其他代理或者一些难以实现的初始设置,也使得跨环境的多智能体代理训练成为可能
- 对代理观察到的其他代理由于自己产生的影响力导致的动作变化赋权(给予奖励),这样就不需要一些特定的通讯协议,相当于多代理之间的互动
- 具体实现:
- 每个时间步长,代理模拟其可进行的一个行动,并评估该行为对其他代理产生的行为变化的影响力,产生较大影响力的行为赋予奖励(反事实推理)
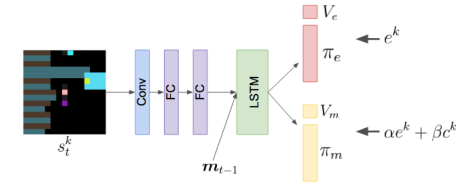
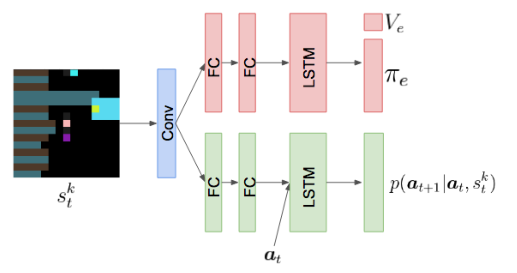
- 每个代理可以独立训练,配备一个内部神经网络观察其他代理(MOA),用来预测其他代理行为以及模拟该行为预测其会对其他代理产生怎么样影响,最后计算自身的内在影响奖励
- 采用了Cleanup以及Harvest环境进行测试,每个智能体都可以选择合作或者背叛,背叛的智能体获得了更高的个人收益,但是更多合作的智能体得到了更高的集体收益,因此总得集体收益可以反馈出合作的情况。从而每个智能体必须合理协调自身行为获得高的影响力回报并且学会合作。
核心工作:
- 通过实验验证影响力的设置对实现代理之间的协调合作至关重要
- 实验设置:采用A3C独立训练每个智能体的策略;神经网络组成:卷积层、全连接层、长短期记忆循环层、线性层
- 奖励不同,设为环境奖励和影响奖励加权和

- 衡量影响力采用了KL散度(j的边际策略,和给定k的策略对j的条件策略之间的差距)(可以其他的散度度量,影响力奖励这一指标具有鲁棒性)
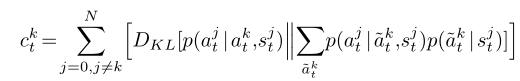
- 奖励不同,设为环境奖励和影响奖励加权和
- Results
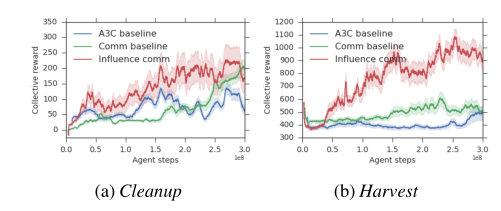
- 对比影响力奖励训练,标准A3C训练以及没有影响力奖励训练的回报

可以看到具有影响力奖励训练的曲线最终的回报是相对较高的,证明了该方法是有助于社会合作的 - 在有影响力奖励设置的实验中增加一个沟通因子mt,在以往没有设置影响力奖励的实验表明自私的代理人不会理会来自这种没有根据的沟通渠道的信息
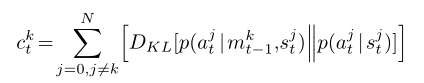
最终训练结果的曲线如下(其中common baseline仅用环境奖励进行训练):
再次印证了影响力奖励的重要性,即使是在具有通信渠道的学习中。 - 通过自身的moa网络计算影响力奖励,设置一个lstm(前面采用的是集中训练的方式得出的采取行动的概率)该模型在学习策略的同时,预测其他代理的行为并且只在可视范围内起作用(考虑到人类的互相影响行为是有范围效应的)
最终结果如下:
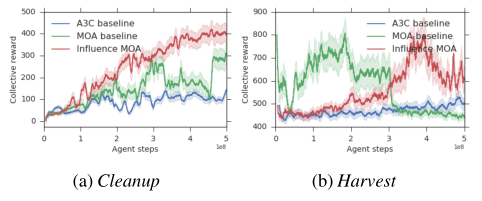
可以看到在cleanup环境中获得奖励相对于之前的方法奖励提升了,之前的方法主要依赖可以查看其他人的奖励。在harvest中不适用,我认为可能是该环境中动作比较单一,不是很依赖动作预测。
- 对比影响力奖励训练,标准A3C训练以及没有影响力奖励训练的回报
结论:
- 所有实验都表明了设置影响力奖励的重要性,促进了智能体合作获得了更高的集体奖励,并且突破了以往的局限性不需要了解其他智能体的现有奖励

 浙公网安备 33010602011771号
浙公网安备 33010602011771号