
netty
五种网络IO模型
阻塞IO模型
![image-20240107204805738]()
- 从发起recvfrom-》数据拷贝完,都阻塞
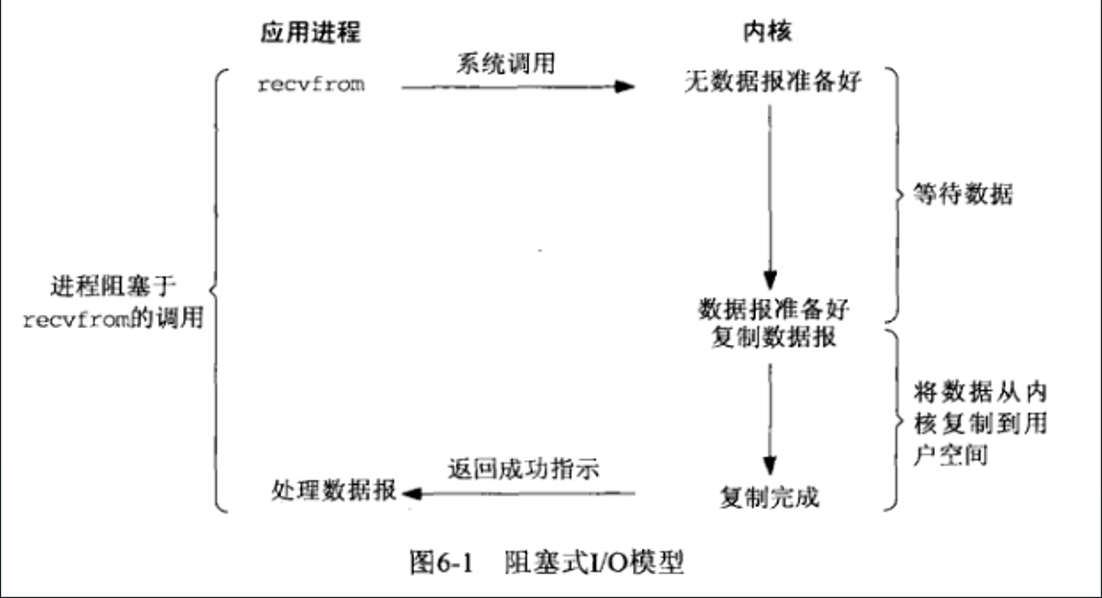
非阻塞IO模型
![image-20240107204835141]()
- 当内核数据报没有准备好时,用java的NIO来说,当配置了ServerSocketChannel.configureBlocking(false);或SocketChannel..configureBlocking(false)时,我们调用ServerSocketChannel.accept()的null或SocketChannel.read(buffer)不会阻塞的,如果没有新连接接入或者内核中没有数据准备好,此时会立即返回NULL或0【即EWOULDBLOCK错误】
- 当内核数据准备好时,此时recvfrom系统调用,用户进程(线程)还是会阻塞,直到内核中的数据报已经拷贝到了用户空间,此时用户进程(线程)才会被唤醒来处理接收的数据报。
- 非阻塞IO在用户数据报还没准备好的时候,recvfrom系统调用不会阻塞
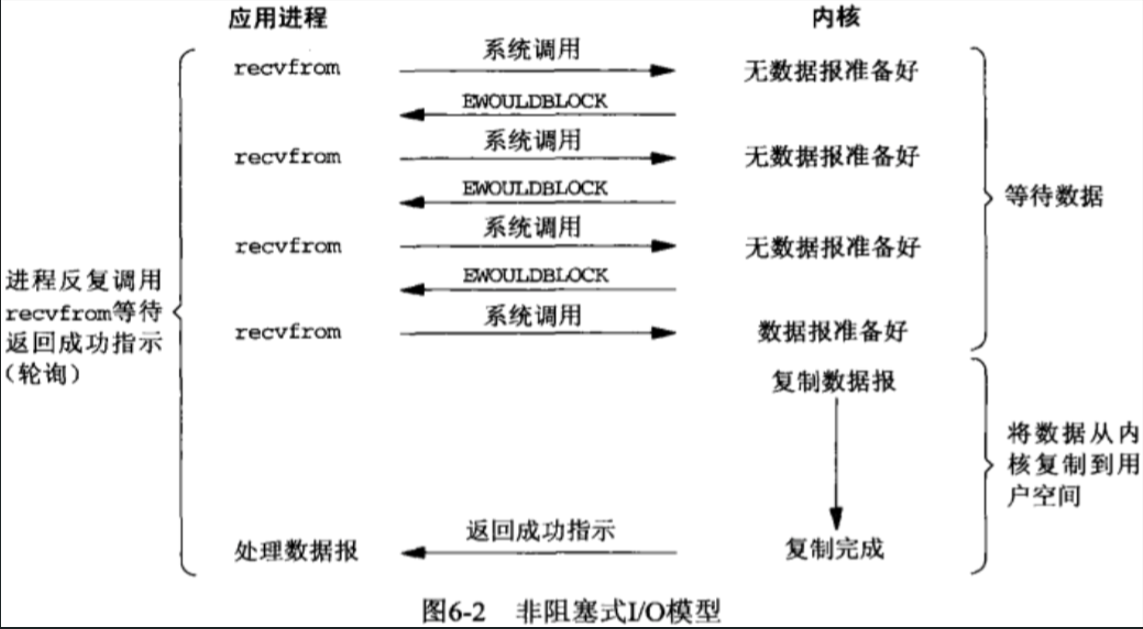
IO多路复用
![image-20240107205322775]()
- 实IO复用模型真正占优势的地方在于select操作,这个select操作可以选择多个文件描述符,分别对应Java NIO中的OP_CONNECT,OP_ACCEPT,OP_READ和OP_WRITE就绪事件。正是基于一次recvfrom系统调用中一个线程的select操作可以选择多个文件描述符这个功能,我们现在用一个用户线程就能监听不同channel的OP_CONNECT,OP_ACCEPT,OP_READ和OP_WRITE这些就绪事件,然后根据某个就绪事件拿到相应的channel来做对应的操作。而不用像阻塞IO模型或非阻塞IO模型那样,一次recvfrom系统调用中一个线程就只能选择一个文件描述符,这样就严重限制了伸缩性
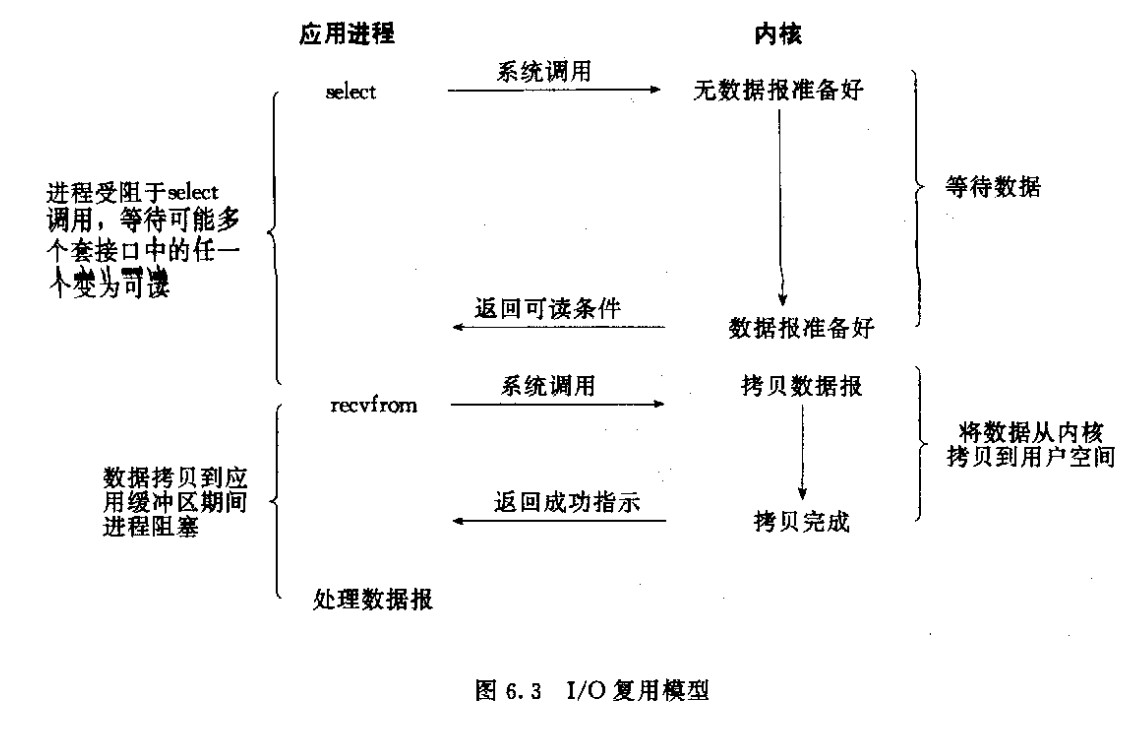
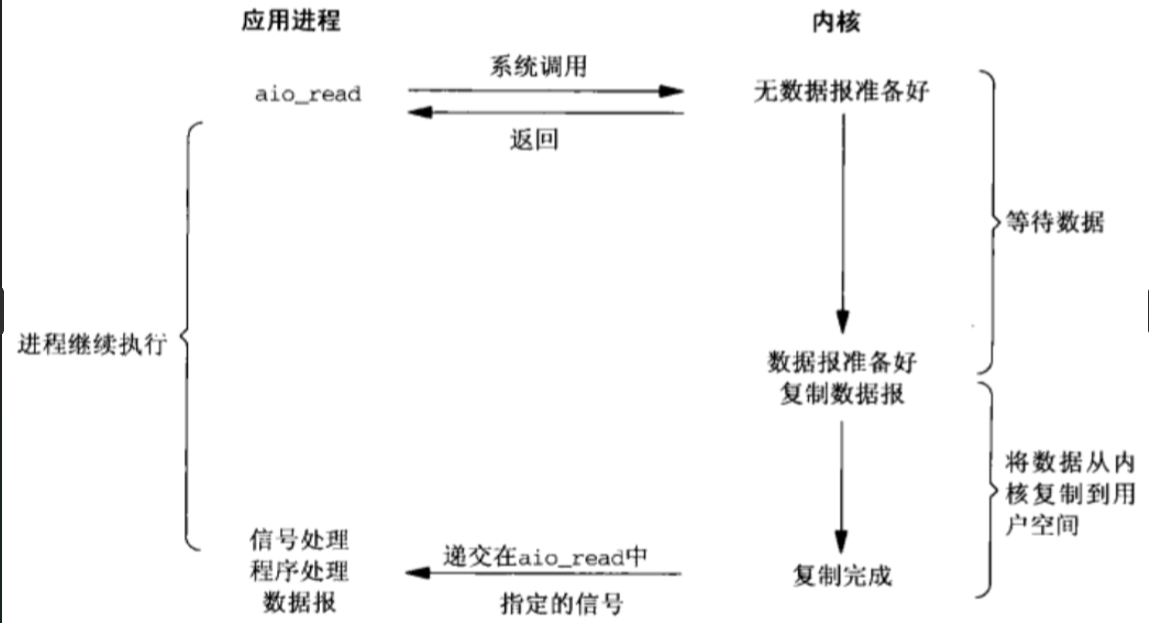
信号驱动IO模型
![image-20240107205342855]()
- 可见,信号驱动IO模型在等待数据报期间是不会阻塞的,即用户进程(线程)发送一个sigaction系统调用后,此时立刻返回,并不会阻塞,然后用户进程(线程)继续执行;当数据报准备好时,此时内核就为该进程(线程)产生一个SIGIO信号,此时该进程(线程)就发生一次recvfrom系统调用将数据报从内核复制到用户空间,注意,这个阶段是阻塞的。
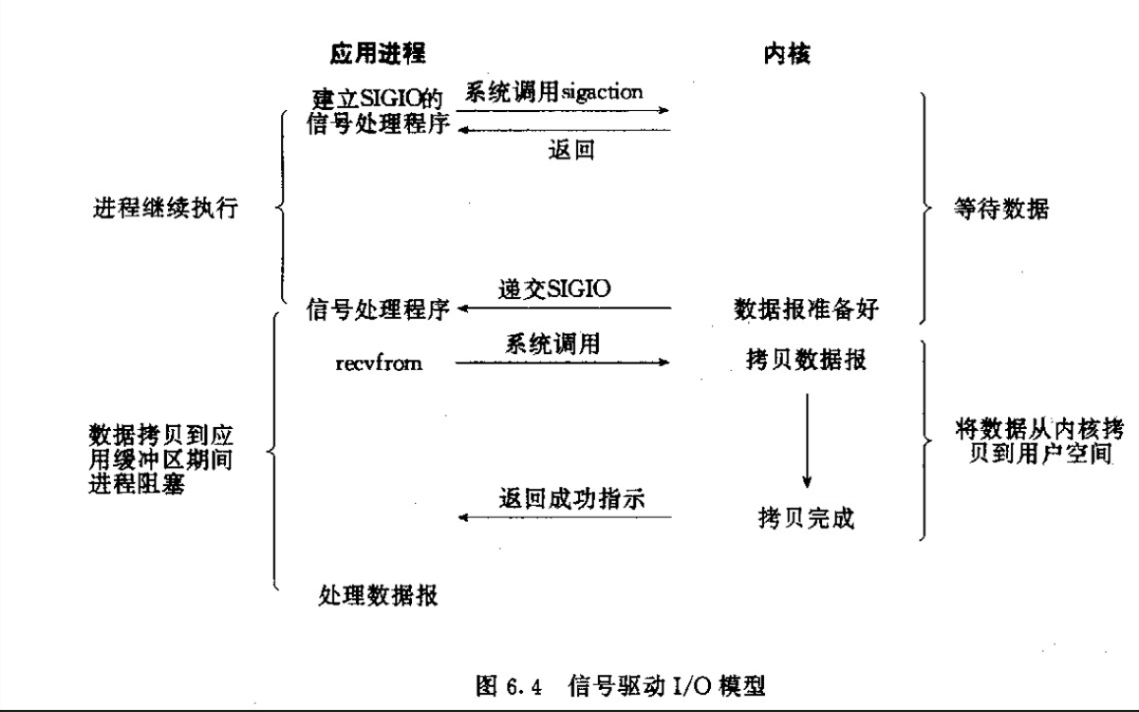
异步IO模型
![image-20240107205523722]()
- 异步IO模型也很好理解,即用户进程(线程)在等待数据报和数据报从内核拷贝到用户空间这两阶段都是非阻塞的,即用户进程(线程)发生一次系统调用后,立即返回,然后该用户进程(线程)继续往下执行。当内核把接收到数据报并把数据报拷贝到了用户空间后,此时再通知用户进程(线程)来处理用户空间的数据报。也就是说,这一些列IO操作都交给了内核去处理了,用户进程无须同步阻塞,因此是异步非阻塞的。
Netty常用概念介绍
select、poll、epoll的区别
Select
- 基本原理
- 监视文件3类描述符:writefds、readfds、exceptfds
- 调用后select会阻塞,等有数据 可读、可写、出异常或者超时就会返回
- select函数正常返回后,通过遍历fdset整个数组才能发现哪些句柄发生了事件,来找到就绪的描述符fd,然后进行对应的IO操作
- 几乎在所有平台都支持,跨平台支持好
- 缺点
- select采用轮训的方式扫描文件描述符,全部扫描,随着文件描述符FD数量增多而性能下降
- 每次调用select,需要把FD集合从用户态拷贝到内核态
- 最大的缺陷是单个进程打开的FD有限制,默认是1024(可修改宏定义)
poll
- 基本流程
- select和poll系统调用大体一致,处理多个描述符也是采用轮训的方式,根据描述符的状态进行处理,一样需要把FD集合从用户态拷贝到内核态,并进行遍历
- 最大的区别:poll没有最大文件描述符限制(使用链表的方式存储FD)
epoll
- 基本原理
- 在2.6内核中提出,对比select和poll,epoll更加灵活,没有描述符限制,用户态拷贝到内核态只需要一次事件通知,通过epoll_ctl注册FD,一旦该FD就绪,内核就会采用callback的回调机制来激活对应的FD
- 优点
- 没fd限制,所支持的FD上线是操作系统的最大文件句柄数,1g内存大概支持10万句柄
- 效率提高,使用回调通知而不是轮训的方式,不会随着FD数量增加效率下降
- 通过callback机制通知,内核和用户控件mmap同一块内存实现
- linux内核核心函数
- epoll_create() 在Linux内核申请一个文件系统,B+树
- epoll_ctl() 操作epoll对象
- epoll_wait()
Netty线程模型和Reactor模式
设计模式-Reactor模式(反应器设计模式),基于事件驱动
优点
- 响应快,不会因单个同步阻塞,虽然Reactor本身依然是同步的
- 编程相对简单,最大程度的避免复杂的多线程及同步问题,并且避免了多线程、进程的切换开销
- 可扩展性,可以方便的通过增加Reactor实例个数来充分利用cpu资源
缺点
- 需要系统底层的支持。
EventLoop和EventLoopGroup线程模型
- 高性能RPC框架的三要素:IO模型、数据协议(http/protobuff/thrift)、线程模型
- EventLoop好比一个线程,一个EventLoop可以服务多个Channel,一个Channel只有一个EventLoop 可以创建多个EventLoop来优化资源的利用,也就是EventLoopGroup
- EventLoopGroup 负责分配 EventLoop 到新创建的Channel,里面包含多个EventLoop
EventLoopGroup -> 多个 EventLoopt
EventLoop -> 维护一个Selector
相关资料 - 默认线程数= 核数 * 2
ServerBootstrap相关属性介绍
-
group 设置线程组魔性,Reactor线程模型对比EventLoopGroup
-
1.单线程
-
2.多线程【boss线程组依然是单线程】
-
3.主从多线程模型【boss线程组和work线程组都是多线程】
boss线程组主要负责,建立连接,io事件监听/读写以及事件分发
-
-
channel 设置channel通道类型NioServerSocketChannel、OioServerSocketChannel【阻塞的】
-
option 作用于每个新建立的channel,设置TCP连接中的一些参数,如下
-
ChannelOption.SO_BACKLOG:存放已完成三次握手的请求的等待队列的最大长度;
-
Linux服务器TCP连接底层知识:
syn queue 半连接队列,洪水攻击, tcp_max_syn_backlog 【TCP第一次建立连接时,服务端存储的队列】
accept queue 全连接队列, net.core.somaxconn 【TCP三次握手成功后,服务端存储的队列】
相关资料 -
系统默认的somaxconn[netty中获取:io.netty.util.NetUtil#SOMAXCONN]参数要足够大,如果backlog比somaxconn大,则会优先用后者
-
ChannelOption.TCP_NODELAY:为了解决Nagle的算法问题,默认是false,要求高实用性,有数据时立马发送,就将该选项设置为true关闭Nagle算法;如果要减少发送次数,就设置为false,会累积一定大小再发送;
-
-
childOption 作用于被accept之后的连接
-
childHandler 用户对每个通道里面的数据处理
Channel模块讲解
概念
- Channel 客户端和服务端建立的一个连接通道
- ChannelHanlder 负责Channel的逻辑处理
- ChannelPipline 负责管理ChannelHandler的有序容器
一个Channel包含ChannelPipeline,所有的ChannelHandler都会顺序加入到ChannelPipeline中,关联永久性,创建时自带
Channel当状态发生变化,就会出发对应事件
Channel状态
- channelRegistered channel 注册到一个EventLoop
- channelUnregistered channel已经创建,但是未注册到一个EventLoop里面,也没有和Selctor绑定
- channelActive 变为活跃状态(连接到了远程主机),可以接受和发送数据
- channelInactive channel处于非活跃状态,没有连接到远程主机
实例
一次注册后的正常状态变更1-3->4->2
ChannelHandler和ChannelPipeline
-
方法
- handlerAdded 当 ChannelHandler 添加到 ChannelPipeline 调用
- handlerRemoved 当 ChannelHandler 从 ChannelPipeline 移除时调用
- excepionCaught 执行抛出异常时调用
-
ChannelHandler下主要两个字接口
-
ChannelInboundHandler 处理输入数据
处理输入数据和Channel状态类型改变
适配器 ChannelInboundHandlerAdapter
常用的 SimpleChannelInboundHandler -
ChannelOutboundHandler 处理输出数据
适配器 ChannelOutboundHandlerAdapter
-
-
ChannelPipeline
好比厂里的流水线一样,可以在上面添加多个ChannelHandler,也可以看成是一串 ChannelHandler实例,拦截穿过Channel的输入输出 event,ChannelPipeline 实现了拦截器的一种高级形式,使得用户可以对事件的处理以及ChannelHandler之间交互获得完全的控制权
chanelHandler处理顺序
InboundHandler顺序执行,OutboundHanlder逆序执行
InboundHandler之间数据传递,通过ctx.fireChannelRead(msg)
InboundHandler通过ctx.write(msg),传递到outboundHandlerCox.write(msg)传递消息,Inbound需要放在结尾,在outbound之后,不然outboundHandler不会执行
ChannelPipeLine、Channel的writeAndFlush和ChannelHandlerContext的writeAndFlush有什么区别
参考:https://juejin.cn/post/7066035880934244359
ChannelFuture讲解
。。。
Netty编解码
为什么要实用netty开发的编解码?
- 无法跨语言
- 序列化后的码留太大
- 序列化和反序列化性能比较差
Netty里面提供默认的编解码器,也支持自定义编解码器
- Encoder
- Decoder
- Codec:编解码器
Decoder讲解
方法
- decode
- decodeLast:用户处理最后几个字节,也就是channel关闭的时候,产生的最后一个消息
抽象解码器
-
ByteToMessageDecoder 用户将字节转为消息,需要检查缓冲区是否有足够的字节
-
ReplayingDecoder 【继承ByteToMessageDecoder,不需要检查缓冲区是否有足够多的数据,速度略慢】 项目复杂度高则使用这个,否则使用ByteToMessageDecoder
-
MessageToMessageDecoder
解码器具体的实现,用的比较多的是
| 常用解码器 | 作用 |
|---|---|
| DelimiterBasedFrameDecoder | 指定消息分割符的解码器 xxxxx&&bbbb |
| LineBasedFrameDecoder | 以换行符为结束标志的解码器 |
| FixedLengthFrameDecoder | 固定长度的解码器 |
| LengthFieldBasedFrameDecoder | message=header + body,基于长度解码的通用解码器 |
| StringDecoder | 文本解码,将接受到的消息转为字符串,一般会与上面的集中进行组合 |
Encoder讲解
-
MessageToByteEncoder
消息转为字节数组
-
MessageToMessageEncoder
用户从一种消息编码为另一种消息
Codec
- ByteToMessageCodec
- MessageToMessageCode
网络传输TCP粘包拆包
TCP拆包:一个完整的包可能会被TCP拆分为多个包进行发宋
TCP粘包:把多个小的包封装成一个大的数据包发送,client发送的若干数据包,Server接受时粘成一个包
发送方:TCP默认会使用Nagle算法
接受方:TCP接受到数据放置缓存中,应用程序从缓存中读取
Netty自带解决TCP半包读写解决方案
DelimiterBasedFrameDecoder : 指定消息分割符的解码器
LineBasedFrameDecoder : 以换行符结束标志的解码器
FixedLengthFrameDecoder : 固定长度解码器
LengthFieldBasedFrameDecoder : message = header + body,基于长度解码的通用解码器
自定义长度半包读写器
maxFrameLength 数据包的最大长度
lengthFieldOffset 长度字段的偏移位
lengthFieldLength 长度字段占的字节数
lengthAdjustment 添加到长度字段的补偿值,如果为负数,开发人员认为这个header的长度字段是整个消息包的长度
initialBytesToStrip 从解码帧中第一次去除的字节数
failFast
Netty基础数据传输
ByteBuf
JDK ByteBuffer
公共读写索引,每次读写操作都需要Flip()
Netty ByteBuf
读写使用不同的索引,所有操作更便捷
ByteBuf创建方法
-
ByteBufAllocator
池化(Netty4.x版本后默认使用 PooledByteBufAllocator 提高性能并且最大程度减少内存碎片
非池化 UnPooledByteBufAllocator : 每次返回新的实例
-
Upooled 提供静态方法创建未池化的ByteBuf,可以创建堆内存和直接内存缓冲区
ByteBuf使用模式
堆缓存区HEAP BUFFER:
优点:存储在JVM的堆空间中,可以快速的分配和释放
缺点:每次使用前会考呗到直接缓存区(也叫堆外内存)
直接缓存区 DIRECT BUFFER
优点:存储在堆外内存上,堆外分配的直接内存,不会占用堆空间
缺点:内存的分配和释放,比在堆缓冲区更复杂
复合缓冲区 COMPOSITE BUFFER
可以创建多个ByteBuf,然后放在一起,但只是一个视图
推荐书籍:《Head First设计模式》
搭建单机百万连接的服务器实例
1.网络IO模型
2.Linux文件描述符 fd
单进程文件描述符,默认1024,每个进程都有最大的文件描述符
全局文件句柄书,也有默认值,不同系统版本会不一样
3.如果确定TCP唯一性
TCP四元组:源ip,源端口,目标ip,目标端口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号