
elasticsearch笔记一
安装
官网链接:[Installation and Upgrade Guide 7.2] | Elastic =》 Installing the Elastic Stack
https://www.elastic.co/guide/en/elastic-stack/7.2/installing-elastic-stack.html
系统支持:支持一览表 | Elastic
启动:sh /usr/local/elasticsearch/bin/elasticsearch -d -p pid
目录结构
| 类型 | 描述 | 默认位置 | 设置 |
|---|---|---|---|
| bin | ⼆进制脚本包含启动节点的elasticsearch | {path.home}/bin | |
| conf | 配置⽂件包含elasticsearch.yml | {path.home}/config | path.conf |
| data | 在节点上申请的每个index/shard的数据⽂件的位置。 可容纳多个位置 | {path.home}/data | path.data |
| logs | ⽇志⽂件位置 | {path.home}/logs | path.logs |
| plugins | 插件⽂件位置。每个插件将包含在⼀个⼦⽬录中。 | {path.home}/plugins | path.plugins |
核心概念
- 索引(index)
- ⼀个索引可以理解成⼀个关系型数据库。
- 类型(type)
- ⼀种type就像⼀类表,⽐如user表,order表。 注意: ES 5.x中⼀个index可以有多种type。 ES 6.x中⼀个index只能有⼀种type。 ES 7.x以后已经移除type这个概念。
- 映射(mapping)
- mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
- ⽂档(document)
- ⼀个document相当于关系型数据库中的⼀⾏记录。
- 字段(field)
- 相当于关系型数据库表的字段
- 集群(cluster)
- 集群由⼀个或多个节点组成,⼀个集群有⼀个默认名称"elasticsearch"。
- 节点(node)
- 集群的节点,⼀台机器或者⼀个进程 分⽚和副本(shard) 副本是分⽚的副本。分⽚有主分⽚(primary Shard)和副本分⽚(replica Shard)之分。 ⼀个Index数据在物理上被分布在多个主分⽚中,每个主分⽚只存放部分数据。 每个主分⽚可以有多个副本,叫副本分⽚,是主分⽚的复制。
使用
配置
curl -X GET "http://localhost:9200/_cluster/settings?pretty"
curl -X PUT "http://localhost:9200/_cluster/settings" -H 'Content-Type:application/json' -d '
{
"persistent": {
"action.auto_create_index": "false"
}
}
'
#当索引不存在并且auto_create_index为true的时候,新增⽂档时会⾃动创建索引,否则会报错。
索引的使用
#获取es的状态
curl -X GET "localhost:9200?pretty" [-v]
#新增
curl -X PUT "localhost:9200/nba?pretty"
#获取
curl -X GET "localhost:9200/nba?pretty"
#新增一个文档
curl -X PUT "localhost:9200/dzy/_doc/1?pretty" -H 'Content-Type:application/json' -d '
{
"user" : "louis",
"message" : "louis is good"
}'
curl -X GET "localhost:9200/dzy/_doc/1?pretty"
#删除一个文档
curl -X DELETE "localhost:9200/dzy/_doc/1?pretty"
#批量请求
curl -x GET "localhost:9200/nba,cba?pretty"
#获取所有
curl -X GET "localhost:9200/_all"
curl -X GET "localhost:9200/_cat/indices?v"
#存在
curl -I "localhost:9200/nba"
#关闭
curl -X POST "localhost:9200/nba/_close"
#打开
curl -X POST "localhost:9200/nba/_open"
mapping
#新增mapping【同修改】
curl -X PUT "localhost:9200/nba/_mapping" -H 'Content-Type:application/json' -d '
{
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "keyword"
},
"play_year": {
"type": "keyword"
},
"jerse_no": {
"type": "keyword"
},
"country": {
"type": "keyword"
}
}
}
'
#获取mapping
curl -X GET "localhost:9200/nba/_mapping?pretty"
#批量获取
curl -X GET "localhost:9200/nba,cba/mapping"
#获取所有
curl -X GET "localhost:9200/_mapping"
curl -X GET "localhost:9200/_all/_mapping"
文档【document】
#新增文档【指定ID】
curl -X PUT "localhost:9200/dzy/_doc/1?pretty" -H 'Content-Type:application/json' -d '
{
"user" : "louis",
"message" : "louis is good"
}'
#新增文档【不指定ID】
curl -X POST "localhost:9200/dzy/_doc?pretty" -H 'Content-Type:application/json' -d '
{
"user" : "louis",
"message" : "louis is good"
}'
#查询指定文档
curl -X GET "localhost:9200/dzy/_doc/P4Oun4sBWV7jQDu0U9du?pretty"
#指定操作类型
curl -X PUT "localhost:9200/nba/_doc/1?op_type=create" -d '{xxx}' 这样如果文档存在就会报错
#查看多个文档
curl -X GET "localhost:9200/_mget" -H 'Content-Type:application/json' -d '
{
"docs": [
{
"_index": "dzy",
"_type": "_doc",
"_id": "1"
},
{
"_index": "dzy",
"_type": "_doc",
"_id": "P4Oun4sBWV7jQDu0U9du"
}
]
}'
curl -X GET "localhost:9200/dzy/_mget?pretty" -H 'Content-Type:application/json' -d '
{
"docs": [
{
"_type": "_doc",
"_id": "1"
},
{
"_type": "_doc",
"_id": "P4Oun4sBWV7jQDu0U9du"
}
]
}'
#修改文档
curl -X POST "localhost:9200/nba/_update/1" -H 'Content-Type:application/json' -d '
{
"doc": {
"name": "哈登",
"team_name": "⽕箭",
"position": "双能卫",
"play_year": "10",
"jerse_no": "13"
}
}'
#向_source字段,增加一个字段
curl -X POST "localhost:9200/nba/_update/1" -H 'Content-Type:application/json' -d '
{
"script": "ctx._source.age = 18"
}'
#向_source字段,删除一个字段
curl -X POST "localhost:9200/nba/_update/1" -H 'Content-Type:application/json' -d '
{
"script": "ctx._source.remove(\"age\")"
}'
curl -X POST "localhost:9200/nba/_update/1" -H 'Content-Type:application/json' -d '
{
"script": {
"source": "ctx._source.age += params.age",
"params": {
"age": 4
}
}
}'
测试见图1-1:
curl -X POST "localhost:9200/dzy/_update/P4Oun4sBWV7jQDu0U9du" -H 'Content-Type:application/json' -d '
{
"script": {
"source": "ctx._source.message = params.message",
"params": {
"message": "renew message"
}
}
}'
curl -X DELETE "localhost:9200/nba/_doc/1"
#注意!!! upsert 当指定的⽂档不存在时,upsert参数包含的内容将会被插⼊到索引中,作为⼀个新⽂档;如果指定的⽂档存在,ElasticSearch引擎将会执⾏指定的更新逻辑。
图1-1:
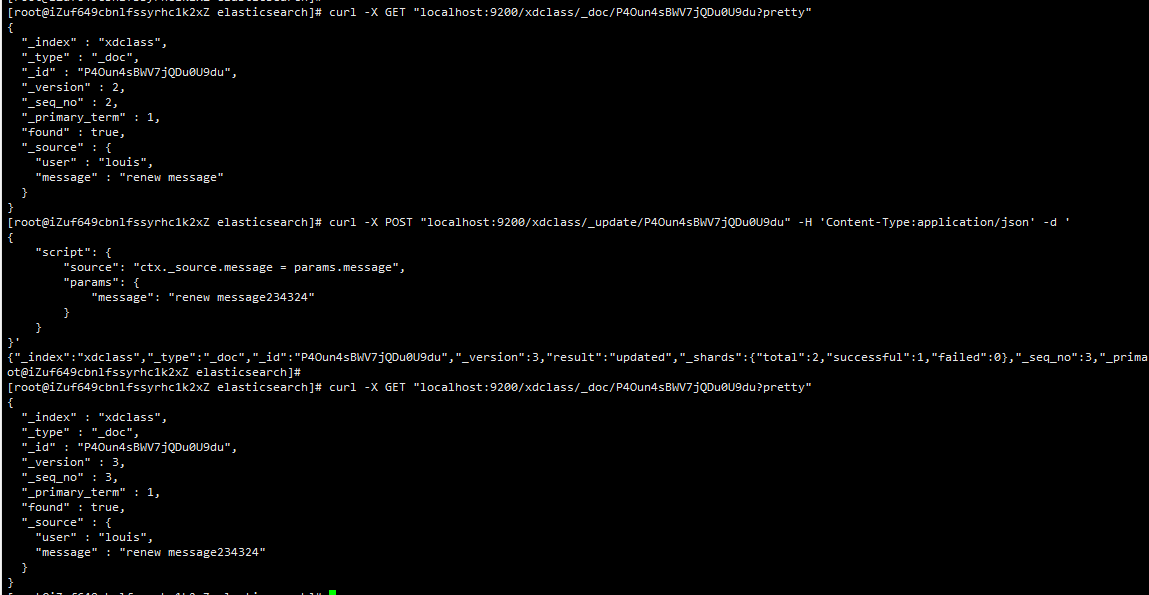
搜索
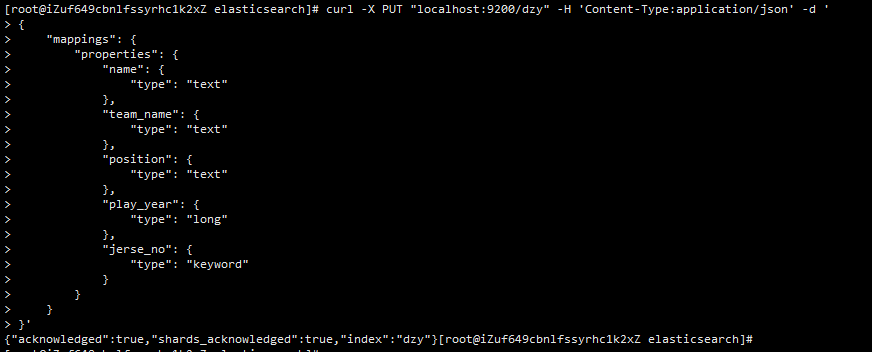
新建索引,并指定mapping
curl -X PUT "localhost:9200/dzy" -H 'Content-Type:application/json' -d '
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "text"
},
"play_year": {
"type": "long"
},
"jerse_no": {
"type": "keyword"
}
}
}
}'
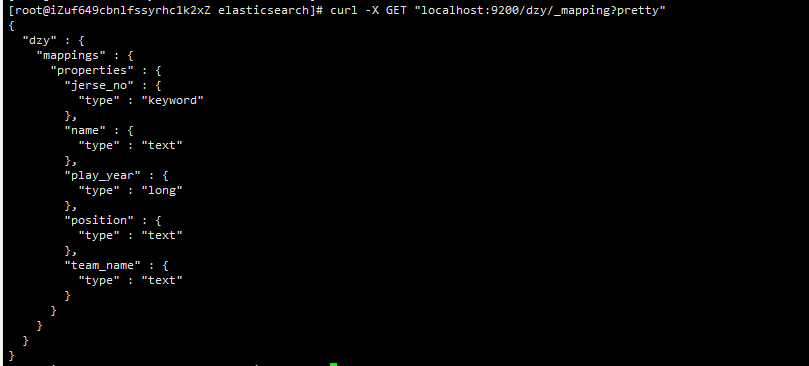
查询索引
curl -X GET "localhost:9200/dzy/_mapping?pretty"
新增文档
curl -X PUT "localhost:9200/dzy/_doc/1?pretty" -H 'Content-Type:application/json' -d '
{
"name": "哈登",
"team_name": "⽕箭",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "13"
}'
curl -X PUT "localhost:9200/dzy/_doc/2?pretty" -H 'Content-Type:application/json' -d '
{
"name": "库⾥",
"team_name": "勇⼠",
"position": "控球后卫",
"play_year": 10,
"jerse_no": "30"
}'
curl -X PUT "localhost:9200/dzy/_doc/3?pretty" -H 'Content-Type:application/json' -d '
{
"name": "詹姆斯",
"team_name": "湖⼈",
"position": "⼩前锋",
"play_year": 15,
"jerse_no": "23"
}'
-
term(词条)查询和full text(全⽂)查询
- 词条查询:词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜 索。
- 全⽂查询:ElasticSearch引擎会先分析查询字符串,将其拆分成多个分词,只要已分析的字 段中包含词条的任意⼀个,或全部包含,就匹配查询条件,返回该⽂档;如果不包含任意⼀ 个分词,表示没有任何⽂档匹配查询条件
-
单条term查询
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "term": { "jerse_no": "23" } } }' -
多条term查询
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "terms": { "jerse_no": [ "23", "13" ] } } }' -
match_all
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "match_all": {} }, "from": 0, "size": 10 } ' -
match
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "match": { "name":"库" } } } ' -
multi_match
curl -X POST "localhost:9200/dzy/_update/2" -H 'Content-Type:application/json' -d ' { "doc": { "name": "库⾥", "team_name": "勇⼠", "position": "控球后卫", "play_year": 10, "jerse_no": "30", "title": "the best shooter" } }' curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "multi_match": { "query": "shooter", "fields": [ "title", "name" ] } } } ' -
match_phrase [类似term]
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "match_phrase ": { "title": "the best" } } } ' -
match_phrase_prefix
curl -X POST "localhost:9200/dzy/_search?pretty" -H 'Content-Type:application/json' -d ' { "query": { "match_phrase_prefix": { "title": "the b" } } } '
分词器
-
什么是分词器
- 将⽤户输⼊的⼀段⽂本,按照⼀定逻辑,分析成多个词语的⼀种⼯具
- example: The best 3-points shooter is Curry!
-
常⽤的内置分词器
- standard analyzer
- simple analyzer
- whitespace analyzer
- stop analyzer
- language analyzer
- pattern analyzer
-
standard analyzer
-
标准分析器是默认分词器,如果未指定,则使⽤该分词器。
-
POST localhost:9200/_analyze
{ "analyzer": "standard", "text": "The best 3-points shooter is Curry!" } curl -X POST "localhost:9200/_analyze?pretty" -H 'Content-Type:application/json' -d ' { "analyzer": "standard", "text": "The best 3-points shooter is Curry!" }'
-
-
simple analyzer
-
simple 分析器当它遇到只要不是字⺟的字符,就将文本解析成term,而且所有的term都是小写的。
-
POST localhost:9200/_analyze
{ "analyzer": "simple", "text": "The best 3-points shooter is Curry!" }
-
-
whitespace analyzer
-
whitespace 分析器,当它遇到空⽩字符时,就将⽂本解析成terms
-
POST localhost:9200/_analyze
{ "analyzer": "whitespace", "text": "The best 3-points shooter is Curry!" }
-
-
stop analyzer
-
stop 分析器 和 simple 分析器很像,唯⼀不同的是,stop 分析器增加了对删除停⽌词的⽀ 持,默认使⽤了english停⽌词
-
stopwords 预定义的停⽌词列表,⽐如 (the,a,an,this,of,at)等等
-
POST localhost:9200/_analyze
{ "analyzer": "whitespace", "text": "The best 3-points shooter is Curry!" }
-
-
language analyzer
-
(特定的语⾔的分词器,⽐如说,english,英语分词器),内置语⾔:arabic, armenian,basque, bengali, brazilian, bulgarian, catalan, cjk, czech, danish, dutch, english, finnish,french, galician, german, greek, hindi, hungarian, indonesian, irish, italian, latvian,lithuanian, norwegian, persian, portuguese, romanian, russian, sorani, spanish,swedish, turkish, thai
-
Post localhost:9200/_analyze
{ "analyzer": "english", "text": "The best 3-points shooter is Curry!" }
-
-
pattern analyzer
-
⽤正则表达式来将⽂本分割成terms,默认的正则表达式是\W+(⾮单词字符)
-
POST localhost:9200/_analyze
{ "analyzer": "pattern", "text": "The best 3-points shooter is Curry!" }
-
-
选择分词器
-
PUT localhost:9200/my_index
{ "settings": { "analysis": { "analyzer": { "my_analyzer": { "type": "whitespace" } } } }, "mappings": { "properties": { "name": { "type": "text" }, "team_name": { "type": "text" }, "position": { "type": "text" }, "play_year": { "type": "long" }, "jerse_no": { "type": "keyword" }, "title": { "type": "text", "analyzer": "my_analyzer" } } } }
-
中文分词器
-
smartCn
-
安装 sh elasticsearch-plugin install analysis-smartcn
-
检验
-
安装后重新启动
-
POST localhost:9200/_analyze
{ "analyzer": "smartcn", "text": "⽕箭明年总冠军" }
-
-
卸载 sh elasticsearch-plugin remove analysis-smartcn
-
-
IK分词器
-
下载 https://github.com/medcl/elasticsearch-analysis-ik/releases
-
安装 解压安装到plugins⽬录
-
检验
-
安装后重新启动
-
POST localhost:9200/_analyze
{ "analyzer": "ik_max_word", "text": "⽕箭明年总冠军" }
-
-
常见的字段类型
-
数据类型
- 核心数据类型
- 复杂数据类型
- 专用数据类型
-
核心数据类型
-
字符串
- text
- ⽤于全⽂索引,该类型的字段将通过分词器进⾏分词
- keyword
- 不分词,只能搜索该字段的完整的值
- text
-
数值型
- long, integer, short, byte, double, float, half_float, scaled_float
-
布尔 - boolean
-
⼆进制 - binary
-
范围类型
- 范围类型表示值是⼀个范围,⽽不是⼀个具体的值
- integer_range, float_range, long_range, double_range, date_range
- 譬如 age 的类型是 integer_range,那么值可以是 {"gte" : 20, "lte" : 40};搜索 "term" :{"age": 21} 可以搜索该值
-
⽇期 - date
-
由于Json没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型
-
format默认为:strict_date_optional_time||epoch_millis
-
格式
- "2022-01-01" "2022/01/01 12:10:30" 这种字符串格式
-
从开始纪元(1970年1⽉1⽇0点) 开始的毫秒数
- 从开始纪元开始的秒数
-
PUT localhost:9200/nba/_mapping
{ "properties": { "name": { "type": "text" }, "team_name": { "type": "text" }, "position": { "type": "text" }, "play_year": { "type": "long" }, "jerse_no": { "type": "keyword" }, "title": { "type": "text" }, "date": { "type": "date" } } } -
POST localhost:9200/nba/_doc/4
{ "name": "蔡x坤", "team_name": "勇⼠", "position": "得分后卫", "play_year": 10, "jerse_no": "31", "title": "打球最帅的明星", "date":"2020-01-01" | 1610350870 |1641886870000 }
-
-
-
复杂数据类型
-
数组类型 Array
- ES中没有专⻔的数组类型, 直接使⽤[]定义即可,数组中所有的值必须是同⼀种数据类型, 不⽀持混合数据类型的数组:
- 字符串数组 [ "one", "two" ]
- 整数数组 [ 1, 2 ]
- Object对象数组 [ { "name": "Louis", "age": 18 }, { "name": "Daniel", "age": 17 }]
- 同⼀个数组只能存同类型的数据,不能混存,譬如 [ 10, "some string" ] 是错误的
-
对象类型 Object
-
对象类型可能有内部对象
-
POST localhost:9200/nba/_doc/8
{ "name": "吴亦凡", "team_name": "湖⼈", "position": "得分后卫", "play_year": 10, "jerse_no": "33", "title": "最会说唱的明星", "date": "1641886870", "array": [ "one", "two" ], "address": { "region": "China", "location": { "province": "GuangDong", "city": "GuangZhou" } } }
-
-
-
专⽤数据类型
-
IP类型
-
IP类型的字段⽤于存储IPv4或IPv6的地址, 本质上是⼀个⻓整型字段.
-
POST localhost:9200/nba/_mapping
{ "properties": { "name": { "type": "text" }, "team_name": { "type": "text" }, "position": { "type": "text" }, "play_year": { "type": "long" }, "jerse_no": { "type": "keyword" }, "title": { "type": "text" }, "date": { "type": "date" }, "ip_addr": { "type": "ip" } } } -
PUT localhost:9200/nba/_doc/9
{ "name": "吴亦凡", "team_name": "湖⼈", "position": "得分后卫", "play_year": 10, "jerse_no": "33", "title": "最会说唱的明星", "ip_addr": "192.168.1.1" } -
POST localhost:9200/nba/_search
{ "query": { "term": { "ip_addr": "192.168.0.0/16" //192.168.0.0~192.168.255.255 } } }
-
-
-
更多数据介绍
kibana的安装和使用
-
下载
-
启动
- 进⼊到⽂件夹的bin⽬录,执⾏sh kibana
- 访问localhost:5601
-
使⽤
- 进⼊到Dev Tools
问题
启动报错【原因,elasticserach不支持root用户启动】
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
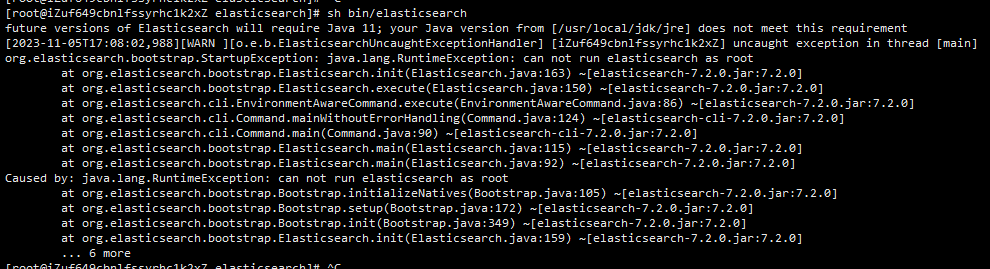
解决
使用其他用户
adduser es
passwd es
chown -R es:es elasticsearch-6.8.9/
chmod 770 elasticsearch-6.8.9/
启动报错【最大虚拟内存不够】
问题一:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
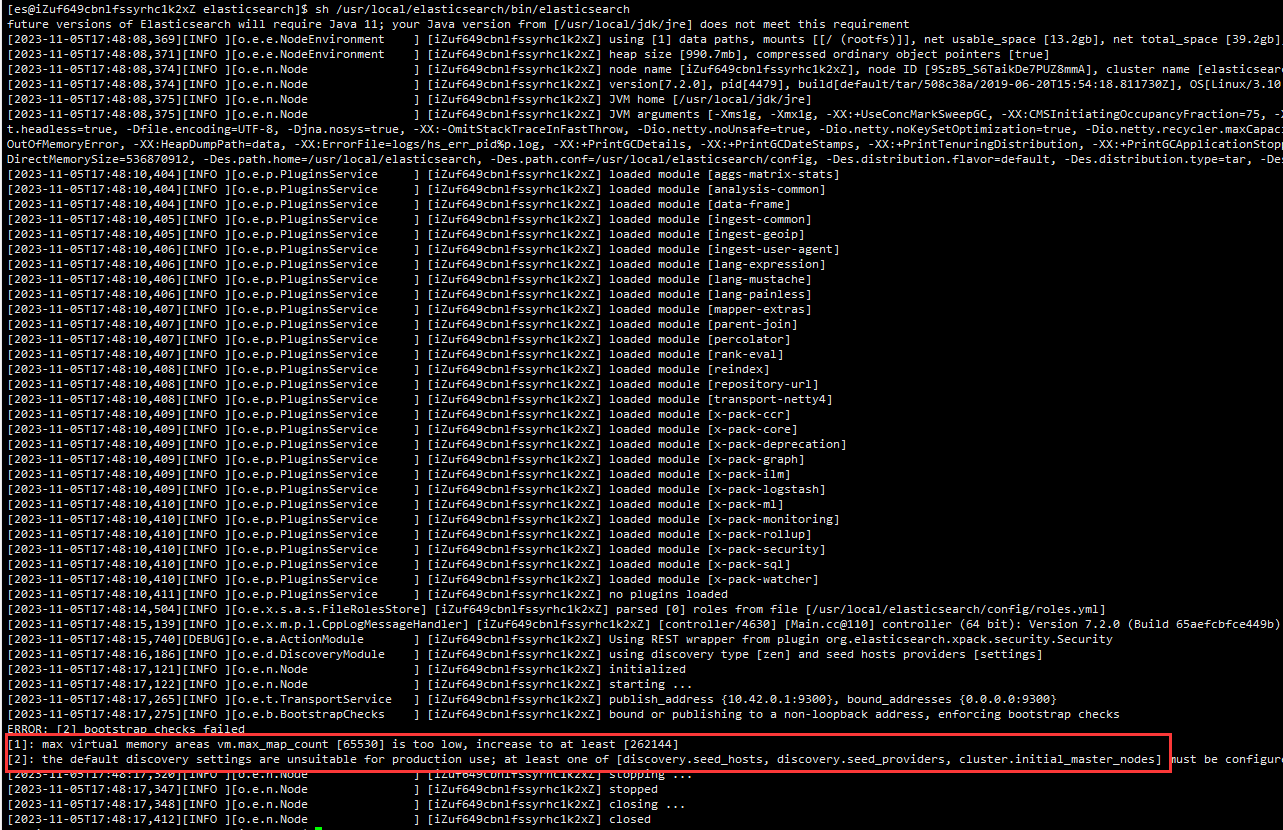
1.修改vm.max_map_count
[root@localhost ~]# sysctl -a|grep vm.max_map_count
vm.max_map_count = 65530
[root@localhost ~]# sysctl -w vm.max_map_count=262144
vm.max_map_count = 262144
[root@localhost ~]# sysctl -a|grep vm.max_map_count
vm.max_map_count = 262144
2.如果重启虚拟机 1)失效则在 /etc/sysctl.conf文件最后添加一行(永久修改)
vm.max_map_count=262144
问题二:the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
network.host: 0.0.0.0
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: "*"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号