机器学习笔记(一)
前言
因工作需要,需要应用机器学习。本人C#出身,会点Java,对Python和机器学习是小白。都说语言是相通的,工作倒逼我去必须去尝试,去学习,通过学习知道是否能掌握一门陌生技能。在网上了解机器学习的学习路径后,买了2本容易上手的入门书籍开始啃,结合网上的一些零碎片段及动手编码实验,现将学到的机器学习知识在园子里做一下记录,希望和初学者一起成长进步。
1、什么是机器学习
1.1 机器学习定义
机器学习是计算机根据数据做出或改进预测或行为的方法。机器学习的形式可分为监督学习,半监督学习,无监督学习,强化学习。形象的描述为对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。机器学习的生命周期为项目需求,样本定义,数据处理,建模,模型上线,模型监控,模型重训或重建。
1.2 机器学习、人工智能、深度学习的关系
通用人工智能:具有人类智能体的软硬件系统。难以实现。波士顿动力公司正在研发的战斗机器人。
(野外战斗测试,目标识别、持枪射击、跨越障碍、快速奔跑与跳跃)
狭义人工智能:人脸识别、语音识别。
机器学习:基于数据学习并做决策,实现人工智能的一种方式方法,被视为实现人工智能的核心。
深度学习:使用多层(一般多于5层)人工神经网络学习数据内部的复杂关系。
机器学习是人工智能的子集,深度学习是机器学习的子集。
2、机器学习的开发环境
2.1 开发语言:Python
语法简单,兼容丰富的第三方库,公认的进行科学计算,数据分析,机器学习首选开发语言。
Python3 和 Python2 是不兼容的,而且差异比较大,Python3是不向下兼容的,但是绝大多数组件和扩展都是基于python2的。Python2性能要比Python3高出15%~30%。目前实际应用中大部分暂不考虑 Python3,有的时候注意写兼容 2/3 的代码。用 Python2 为主的写新代码时要考虑以后迁移到 Python3 的可能性。据数据统计显示目前10% 使用 Python 3;20% 既使用Python2也使用Python3,Python 2用的更多;70% 使用Python2。
无历史包袱,选择3.x版,最新版本3.10,稳定版3.8,实际开发中选择3.8,可以选择较新的特性
安装和配置教程:《Phython环境搭建》
2.2 编辑器:Jupyter Notebook
几乎已成为机器学习领域的标准编辑器,与其他IDE开发工具(IDLE,PyCharm,Spyder)相比,最大的优势是可以根据执行结果,快速在同一界面调整代码(数据)。在处理数据分析时,可以频繁调整代码处理方法,然后观察处理结果,这种频繁的交互过程,又叫探索式编程,节省大量的调试时间。
安装和配置教程:《Jupyter Notebook安装配置与使用教程》
2.3 部署
优先使用Docker进行工程化、标准化
其次使用make_server做Restful风格Api,优点是可部署在生产环境,但需要自行写路由,其实写路由也很简单
再次引入第三方flask库做Restful风格Api,但不适合部署在生产环境,因为不支持并发,仅供学习使用
以上知识可以都可通过百度搜索获取
3、第三方开源库
3.1 Numpy
借助多维数组和相关的函数实现复杂的数据处理和计算,是其他科学计算的基础库,是进行数据分析,科学研究,机器学习需要掌握的入门级库
3.2 Scikit-learn
一款优秀的机器学习库,机器学习必须掌握的库。使用范围为传统的,面向通用功能的,中小规模应用的机器学习库,可通过个人计算机来做机器学习。学习方式是通过参数设置,不同的模型的选择,数据特征的处理,在人辅助的情况下进行机器学习。学习难度上适合机器学习的初学者入门。
3.3 TensorFlow
谷歌近几年推出的机器学习库,震惊世界的打败世界围棋冠军的AlphaGo就算采用TensorFlow作为底层支撑技术。使用范围为面向深度学习,进行大规模数据应用学习,对计算机要求高,需要专用GPU芯片对数据处理进行加速,并需要采用性能更高的专业服务器进行数据处理。学习方式为通过自身的机器学习模型,自动提炼数据,无须人为辅助。学习难度上不适合机器学习的初学者入门。
3.4 Pandas
开源数据处理库。在行、列两个方向对数据预处理、建模、分析能力都达到了极致。是数据工程师、数据研究科学家需重点关注的一个库
3.5 Matplotlib
基于Python语言的可视化(数字图像)标配开源库,提供了强大的二维、三维及动画展示功能。可被Numpy、Scipy、Pandas、Scikit-learn等调用
3.6 Scipy
Numpy的强化版,提供更强大的科学计算能力,但要求掌握非常专业的数学知识和不同领域的专业知识,才能有针对性地进行学习和掌握。可根据自身能力选择性学习
4、机器学习入门
4.1、概念
4.1.1 特征
用于刻画事物异于其他事物的特点,由属性和属性值组成。
4.1.2 特征向量
一个事物所记录的所有特征,构成了一个特征向量。
4.1.3 距离度量
距离度量是数学法则,用于空间测量沿曲线的距离和曲线间的角度。常见的距离度量算法包括欧式(欧几里得)距离算法、街区距离算法、棋盘距离算法等。标记是监督学习的优点,有些数据是无法做标记的,就得采用无监督学习,如语音识别里得去噪音,就需要用到距离度量算法。
4.1.4 算法
算法就是解决问题的过程,能够对一定规范的输入,在有限时间内获得所要求的输出,如线性回归算法,均值算法等。
4.1.5 模型
借助算法和数据形成固定模式,实现对事物性质的准确判断与表达。线性回归分类是监督学习的一种算法,基于该算法和相关数据建立的数据模型,称线性回归分类模型。分类算法可以是线性回归分类、决策树、朴素贝叶斯、支持向量机等。
4.1.6 数据集
数据集指机器学习中提供的数据样本,用于不同模型的计算、评估、验证和预测,最终产生有用的信息。通常分为训练集,测试集。
实际使用过程中通常将80%左右的数据样本分为训练集,20%左右的数据样本分为测试集。
交叉验证是另一种数据集分类方式,详见《机器学习中的交叉验证(cross-validation)》。
4.2 Scikit-learn库
提供的主要功能分六大部分:分类、回归、聚类、降维、模型选择、数据预处理
4.2.1 分类
确定数据对象的所属类别。常见应用场景有垃圾邮件分类、可标记图像识别等。提供了普通最小二乘线性、线性和二次判别分析、向量机、随机梯度下降、最近邻、高斯处理、交叉分解、朴素贝叶斯、决策树、多类和多标签、特征选择、半监督、等渗回归、概率校准、神经网络算法等功能。不支持深度学习,不适合大规模数据处理场景。
4.2.2 回归
预测与给定对象相关联的连续属性。常见应用场景如预测药物反应、预测股票价格趋势等。提供了向量回归、岭回归、套索回归、弹性网络、最小角度回归、贝叶斯回归、稳健型回归、多项式回归算法等功能。
4.2.3 聚类
自动识别具有相似属性的给定对象,并将其分组为集合,属于无监督学习的范畴。常见应用场景如顾客细分、实验结果分组等。提供了K均值聚类、亲和力传播聚类、光谱聚类、均值偏移聚类、分层聚类、基于密度的噪声应用空间聚类等算法功能。
4.2.4 降维
采用主成分分析、截断奇异值分解语义分析、字典学习、因子分析、独立成分分析、非负矩阵分解或特征选择等降维技术来减少要考虑的随机变量个数,以提高运行速度。主要应用场景有可视化处理,自然语言处理、信息检索和计算效率提升等。
4.2.5 模型选择
通过调整参数对模型进行比较、验证、选择、以选择最佳精度的模型效果。提供了交叉验证、各种模型评估、模型持久性、验证曲线等功能。
4.2.6 数据预处理
数据特征的提取和归一化,是机器学习过程中的第一个也是最重要的一个环节。归一化指将输入数据转换为具有零均值和单位权方差的新变量。大多数情况下做不到精确等于零,设置一个可接受的范围,零均值一般都要求落在0~1之间。数据特征提取指将文本或图像数据转换为可用于机器学习的数字变量。
5、数据准备
5.1 国内外专业在线数据源
利用搜索引擎从在线公共数据源中搜索各种自己想要研究的数据。
国内如
天元数据网:https://www.tdata.cn/
国外如
5.2 Scikit-learn数据源
Scikit-learn库本身提供两类数据,一类是自带的小数据集,另一类是在线真实世界数据集
5.3 业务数据库数据源
关系型数据库MySQL\SQLServer\Oracle\SQLite(Pytho自带单机数据库系统)\Acces等,NoSQL数据库系统MongoDB\Cassandra\Redis\Hbased等,NewSQL数据库PostgreSQL\SequoiaDB\SAP HANA\MariaDB\VoltDB\Clustrix等
Python语言为此提供了大量的数据库系统访问驱动接口程序,读取数据库中的数据
5.4 随机自生成数据
Scikit-learn提供了随机样本生成器。随机样本生成器可以根据读者的预期要求,快速生成模拟样本数据集,然后在这个样本的基础上,进行各种数据分析和机器学习验证
5.4.1 分类样本数随机生成器
sklearn.datasets.make_classification(n_samples=100,n_reatures=20,n_informative=2,n_redundant=2,...)
5.4.2 聚类样本数随机生成器
sklearn.datasets.make_blobs(n_samples,n_features,centers,cluster_std,center_box,shuffle,random_state)
5.4.3 回归模型样本数随机生成器
sklearn.datasets.make_regression(n_samples=100,n_features=100,n_informative=10,n_target=1,...)
5.4.4 S曲线数据集随机生成器
sklearn.datasets.make_s_curve(n_samples=100,noise=0.0,random_state=None)
5.4.5 其他随机样本生成器
Scikit-learn官网还提供了其它16种随机样本生成器,可通过np.info()获取使用帮助信息
5.5 指定文件读取数据
Scikit-learn库提供了文件读取功能,实现对文本、图片数据的读取处理。
5.5.1 文本文件读取
datasets.load_files(path,description,categories,content,shuffle,encoding,decode_error,random_state)
5.5.2 图片文件读取
datasets.load_sample_images()及datasets.load_sample_images(image_name)
图片文件需放在默认安装的Scikit-learn库路径下
6、分类
分类属于监督学习,确定对象属于哪个类别。常见的实现模型包括SVM、最近邻居、随机森林等,常用于垃圾邮件检测、图像识别等。
6.1 分类基础
机器学习的基本过程为
第一步:准备训练数据
第二步:选择分类模型,准备学习(机器学习分类模型比较多)
第三步:分类模型训练学习,掌握分类特征,分类标签(无监督学习无该项内容),并进行验证测试,调优
第四步:训练后的分类模型进行实际应用
第五步:应用结果评估
分类机器学习基本过程和其他机器学习的基本过程相似,可以应用到其他机器学习基本过程中。
6.2 SVC分类模型
SVC全称C-Support Vector Classification(C-支持向量分类),通过样本数据间的间隔(距离)计算对数据进行分类,函数如下
sklearn.svm.SVC(C=1.0,kernel='rbf',degred=3,gamma='auto_deprecated',coef0=0.0,shrinking=True,...)
6.3 fit()方法拟合SVC分类模型
SVC分类模型要实现训练集的学习,必须通过fit()方法实现,fit()根据给定的训练数据拟合SVM模型,fit()根据给定的训练数据拟合SVM模型,函数如下
fit(X,y,sample_weight=None)
6.3 SVC模型代码示例
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
Data = np.array([[1.0,1.0,0], #准备训练数据样本集,最后一列为分类标签
[1.0,2.0,0],
[1.5,3.0,0],
[2.0,1.0,0],
[2.5,2.0,0],
[2.0,2.5,0],
[5.0,5.0,1],
[4.0,4.0,1],
[4.5,5.0,1]])
x_train = Data[:,:-1] #准备训练集数据
y_train = Data[:,-1] #提供训练集对应的标签值
cl = svm.SVC(C=0.9,kernel='linear',gamma=10) #在线性核算法情况下,需要确定C、gamma参数,创建学习模型
cl.fit(x_train,y_train) #指定训练集,分类标签集,进行拟合训练学习
T = np.array([[1.5,2],[4.5,4]]) #测试集数据
er = cl.predict(T) #测试模型,并给出分类结果
print('测试数据分类结果',er)
x = np.linspace(0,8,20) #设分类线的x坐标值
y = -(cl.coef_[0,0]*x+cl.intercept_[0])/EEEcl.coef_[0,1] #计算分类线y值,coef_为线性斜率,intercept_为截距
plt.plot(x,y,'g') #绘制分类线
plt.plot(x_train[0:6,0],x_train[0:6,1],'bP') #绘制标签为0的样本数据,十字标记
plt.plot(x_train[6:,0],x_train[6:,1],'mo') #绘制标签为1的样本数据,圆形标记
plt.plot(T[:,0],T[:,1],'gD',markeredgewidth=4) #绘制测试数据,粗的实心菱形标记
plt.show()
测试数据分类结果:[0. 1.] #测试数据[1.5,2]分类为0,[4.5,4]分类为1

分类线左小角为十字标记的是标签值为0的样本,分类线右上角为圆形标记的是标签值为1的样本,左小角一个粗的实心菱形标记是测试数据[1.5.2],其标签值也为0,归入左小角样本类,右上角一个粗的实心菱形标记是测试数据[4.5,4],其标签值也为1,归入右上角样本类。测试结果表明测试数据分类非常明确
7、回归
回归属于无监督学习。根据事物之间的因果关系,借助已有数据预测后续数据发展趋势。随时间在x轴上的发展,随机性发展的事物在y轴上趋于平均值的回归性。常用于药物反应、股票价格预测分析等。
7.1 回归基础
Scikit-learn库中常见算法包括线性回归,逻辑回归,多项式回归,逐步回归,岭回归,套索回归,弹性网络回归,决策树分类回归,随机森林回归等
7.2 决策树分类回归模型
决策树采用类似二叉树的算法,判断每个节点特征值的相似度。当节点只有两个子节点时,则是基于二叉树决策分析;当节点具有多个子节点时(可以是1个,2个,3个,...),则为基于普通分类树决策分析,决策树根据节点的关系分层次,层次越多判断节点越多。决策树既可以用于分类,又可以用于回归决策。函数为
sklearn.tree.DecisionTreeClassifier(criterion='gini',splitter='best',max_depth=None,...)
7.3 决策树分类回归模型代码示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
plt.rc('font',family='SimHei',size=10) #设置黑体,大小为10
plt.rcParams['axes.unicode_minus']=False #解决坐标轴负数的负号显示问题
from sklearn.datasets import make_regression #导入回归模型样本随机生成器
#=============================================================产生样本数据
data,target,Coef = make_regression(n_samples=200,n_features=3,coef=True,noise=8,
random_state=97) #生成线性回归样本
x_train,y_train = data[:160],target[:160] #训练集
x_test,y_test = data[160:],target[160:] #测试集
#=============================================================决策树回归计算
tree_model = tree.DecisionTreeRegressor() #创立决策树回归模型
tree_model.fit(x_train,y_train) #对训练集数据进行模型学习
result = tree_model.predict (x_test) #用测试集数据预测
score = tree_model.score(x_test,y_test) #评估模型预测的准确度
#=============================================================数据可视化
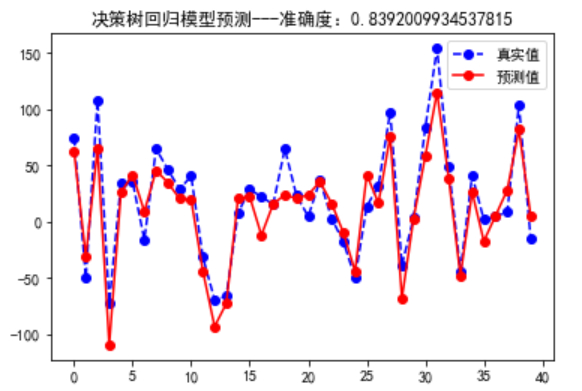
plt.figure()
plt.plot(np.arange(len(result)),y_test,"bo--",label='真实值') #绘制真实线形图
plt.plot(np.arange(len(result)),result,"ro-",label='预测值') #绘制预测线性图
plt.title(f"决策树回归模型预测---准确度:{score}")
plt.legend(loc="best")
plt.show()
7.4 随机森林回归模型
随机森林回归模型是在集成决策树回归模型的基础上,通过指定N个决策模型一起工作,产生的预测结果。随机森林模型是机器学习里功能非常强大的模型之一。随机森林回归模型对象RandomForestRegressor用于建立随机森林回归模型。
7.4 鸢尾花随机深林回归模型代码示例
通过对鸢(yuan)尾花的数据分析,可以知道每个样本数据有4个特征,随机深林回归模型能接受多特征值的情况,预测分析4个特征值各自的重要性如何?
from sklearn.model_selection import train_test_split #导入样本分类器
from sklearn.ensemble import RandomForestRegressor #导入随机森林回归模型
from sklearn.datasets import load_iris #导入鸢尾花样本集函数
iris = load_iris() #装入鸢尾花样本集
#==============================================================鸢尾花样本集基本情况
labels=iris.feature_names #获取鸢尾花的四个特征名
print('鸢尾花的四个特征名是:')
print('萼片宽度%s,萼片长度%s,花瓣宽度%s,花瓣长度%s'%(labels[0],labels[1],labels[2],labels[3]))
print('获取鸢尾花记录的前2条的四个特征值')
print('第一朵花特征值',iris['data'][0])
print('第二朵花特征值',iris['data'][1])
num,fw=iris['data'].shape #获取鸢尾花data样本集的形状大小
print('该样本集提供了%d朵鸢尾花(带%d个特征)记录'%(num,fw))
print('该样本提供了鸢尾花记录对应的标签分类树:',iris['target'].shape)
x = iris['data'] #150朵鸢尾花特征记录(4个特征值)
y = iris['target'] #标签值为0,1,2的150朵花的分类
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.2,random_state=201) #按照4:1分割训练集合测试集
print(train_x.shape,train_y.shape,test_x.shape,test_y.shape)
#=============================================================创建随机深林模型并学习
rModal = RandomForestRegressor(n_estimators=20) #建20个随机决策树的随机森林模型
rModal.fit(train_x,train_y) #取150*80%样本作为训练集学习
#=============================================================测试集数据模型测试
result = rModal.predict(test_x) #取150*20%样本作为测试集进行测试,这里无分类标签
print(r'30个样本分类预测相似度结果:') #标签分类值为0,1,2
print(result)
score=rModal.score(test_x,test_y)
print('30个测试样本预测平均分类相似度',score)
r2 = rModal.predict([iris.data[121]])
print('第121朵鸢尾花测试分类相似度为',r2)
print('第121朵鸢尾花实际分类标值为',iris['target'][121])
#=============================================================显示各特征值的重要性
print('萼片宽度,萼片长度,花瓣宽度,花瓣长度') #特征名称
print(rModal.feature_importances_) #对应的重要性百分比

由代码执行结果可知,花瓣宽度重要性最高,占57.0%;其次为花瓣长度,占41.5%;再次为萼片宽度,萼片长度。在样本特征特别多的情况下,应该保留主要特征值,舍去次要特征值,以提高运算速度
8、聚类
聚类属于非监督学习。把相似的元素进行自动分类。应用很广,常用于消费者分类,实验数据分类等。
8.1聚类基础
Scikit-learn库提供了KMeans(K均值)、临近传播、光谱聚类、均值偏移、分层聚类、DBSCAN(基于密度的聚类)、Brich(综合层次聚类)等聚类算法。聚类算法的一个突出特点是没有借助样本数据的标签值进行分类,这是监督学习与非监督学习的一个最主要区别。
聚类算法基本实现思路包括划分法,层次法,基于密度法,基于网格法,基于模型法。
划分法的基本过程如下
第一步:指定K确定所需簇的个数,即确定样本数据集K类的个数
第二步:迭代。迭代过程是先确定K类的K个初始质心,把相邻距离的样本点纳入该簇中,依次完成K个初始质心的一次样本归类,计算各自分簇样本数据的距离均值,以各自均值为新的质心,依次计算并调整样本数的归类,反复迭代计算,一直到新质心稳定不变或符合迭代阈值要求,实现样本数据的预测。
8.2 K均值模型
函数KMeans(n_clusters,init,n_init,max_iter,tol,precompute_distances,verbose,random_state,copy_x,n_jobs,algorithm),K均值聚类要求数据具有一定的离散分类特征,且没有异常或孤立点数据,否则会降低聚类准确度,并增加计算量。
8.3 K均值模型代码示例
from sklearn.cluster import KMeans #导入Kmeans模型
import numpy as np
Data = np.array([[1,2],[2,4],[1,1], #预置第一类训练集数据
[7,5],[8,4],[8,6]]) #预置第二类训练集数据
kmeans = KMeans(n_clusters=2,random_state=133) #创建模型,指定k值为2,样本数据分两类
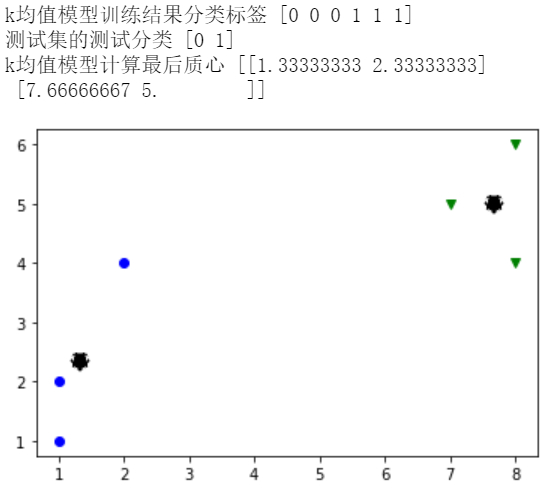
kmeans.fit(Data) #样本数据K均值模型训练
lb = kmeans.labels_ #训练结果的分类标签
print('k均值模型训练结果分类标签',lb)
result = kmeans.predict([[2,3],[9,5]]) #数据测试预测分类
print('测试集的测试分类',result) #预测结果
kc = kmeans.cluster_centers_ #计算最后质心
print('k均值模型计算最后质心',kc)
#============================================================可视化
import matplotlib.pyplot as plt
plt.figure()
plt.plot(Data[:3,0],Data[:3,1],'bo') #绘制蓝色圆点第1类样本
plt.plot(Data[3:,0],Data[3:,1],'gv') #绘制绿色下三角点第2类样本
plt.plot(kc[:,0],kc[:,1],'k*',markeredgewidth=10) #绘制黑色粗*质心点
plt.show()
9、降维
降维降低处理的特征维度,提高运行效率,使数据处理可视化,机器学习更加实用。解决了样本数据特征维度过高,大规模的样本数据特征都参与机器学习,导致运算速度缓慢的二类问题。
9.1 降维基础
主流降维方法为投影和流形学习。
投影是把高维度的特征数据降到低维度,然后进行机器学习。如把三维样本数据降低到二维,用二维图展现其特征。
流形学习认为实际观察到的数据是由一个低维流形映射到高维空间,可以用低维唯一的表示高维的特征。流形指数据表现出来的形状,如二维平面形状数据可以在三维中弯曲或扭曲,如瑞士卷。
Scikit-learn库提供了降维算法包括主成分分析(PCA),独立成分分析(ICA)、文档主题生成模型(LDA),自组织映射网络(SOM),多维尺度变换(MDS),等距离映(ISOMAP),局部线性嵌入(LLE),T-分布随机近邻嵌入(T-SNE)等。
9.2 主成分分析(PCA)模型
PCA算法是一种无监督学习,最常用的降维算法之一,其采用投影方法降维。
函数PCA(n_components,copy,whiten,svd_solver,tol,iterated_power,random_state)
9.3 PCA模型降维代码示例
import numpy as np
from sklearn.decomposition import PCA
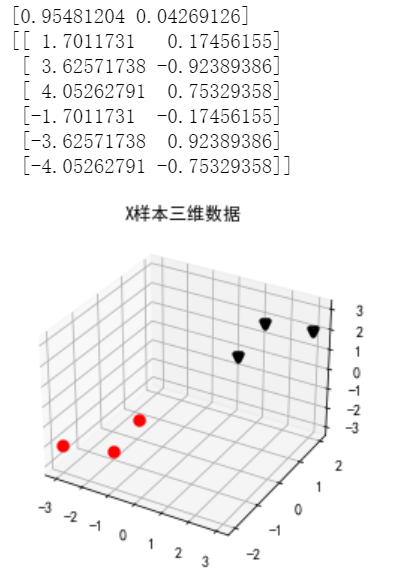
X = np.array([[-1,-1,-1],[-2,-1,-3],[-3,-2,-2],[1,1,1],[2,1,3],[3,2,2]]) #三维样本
pca = PCA(n_components=2) #创建PCA模型,从三维降到二维
pl = pca.fit_transform(X) #模型训练并返回降维结果
print(pca.explained_variance_ratio_) #指出降维后各特征的重要性比
print(pl) #输出从三维降到二维的结果
#==========================================================X样本三维数据可视化
from matplotlib import pyplot as plt
from mpl_toolkits.mplot3d import Axes3D #导入三维坐标模块Axes3D
plt.rc('font',family='SimHei',size=10) #设置黑体,大小为10
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴负数的负号显示问题
plt.figure()
ax1 = plt.axes(projection='3d')
i=0
for x in X:
if i<3:
ax1.scatter(x[0],x[1],x[2],c='r',marker='o',linewidths=4) #在三维用散点函数绘制前3个点
else:
ax1.scatter(x[0],x[1],x[2],c='k',marker='v',linewidths=4) #在三维用散点函数绘制后3个点
i+=1
plt.title('X样本三维数据')
plt.show()
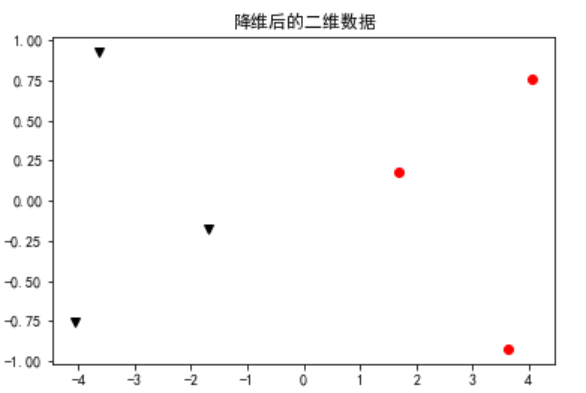
#==========================================================降维后的二维数据可视化
plt.title('降维后的二维数据')
plt.plot(pl[:3,0],pl[:3,1],'ro') #在二维绘制前2个点
plt.plot(pl[3:,0],pl[3:,1],'kv') #在二维绘制后2个点
plt.show()
10、模型选择
机器学习过程中,训练完成的模型在实际使用过程中会出现准确率很低的问题。训练集模型经验满足不了新样本数据(验证集)的预测要求,产生 泛化能力不足的问题。在实际应用中,用户希望选择最佳模型,由此产生了模型选择问题。
Scikit-learn库的模型库都带有score()方法,用于评估模型对样本的预测准确度,评分越高模型越适合。如可以针对相同手写字数字图片样本数据集,采用SVC分类模型,K均值聚类模型所能识别的准确度进行比较,确定那个模型更适合。
10.1 模型选择基础
训练完成的模型在实际应用中表现不佳,表现为欠拟合和过拟合,可以从数据集 、模型训练方法选择、模型参数调优、模型选择着手进行完善。
10.1.1 欠拟合和过拟合
欠拟合指模型拟合程度不高,数据距离拟合曲线较远,或模型没有很好地捕捉到数据特征。主要解决方法是增加数据集的新特征,添加多项式特征,减少正则化参数,使用非线性模型并调整模型的容量。该部分涉及数据集的解决方法是数据预处理。
过拟合是指对训练集进行模型拟合训练的情况下偏差很小(预测错误率),但在实际验证集下的泛化预测准确性很差。主要解决方法是增加更多的训练数据,减少训练集的特征个数(如降维),对模型进行正则化处理。
Scikit-learn为过拟合提供了learning_curve()方法,通过准确度对比发现是否存在过拟合问题。
10.1.2 模型参数调优
机器学习模型中一般存在大量的参数,不同的参数值对同一样本数据也会产生不同的训练结果。通过人工电子参数,希望得到最优的模型,但是大量参数调整工作将带来很大的工作量,一般建议模型推荐的默认值或通过等间隔取值方式观测并确定最佳参数值,或通过可视化方式确定参数值
10.2 交叉验证及模型选择
验证集产生的方法可以分为Holdout验证方法、留一验证方法、交叉验证方法等。
Holdout验证方法把样本数据分为训练集、测试集、验证集三部分,一般拆分比例为6:2:2,也可以把验证集分为几个进行连续验证
留一验证法是在样本里取一条记录作为验证数据,进行模型训练,然后取下一个记录,一直到所有的样本都获取一遍,产生最终的训练模型。该方法适应与小样本训练。
交叉验证方法是把样本随机分拆成n分子样本,一个单独的子样本用于验证模型,剩余的n-1份用于模型训练。每个子样本验证一次,这就交叉验证n次,然后产生最终的模型结果。一般n取10次。
Scikit库自带的手写数字小样本进行10次随机交叉验证,并通过SVC分类模型的'rbf'和'sigmoid'算法进行分别验证,最后通过曲线学习观察函数ShuffleSplit(),用可视化方式评估交叉验证的效果。
交叉验证模型代码示例如下
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC #导入C-支持向量分类模型
from sklearn.datasets import load_digits #导入小样本手写数字集
from sklearn.model_selection import learning_curve #导入学习曲线观察函数
from sklearn.model_selection import ShuffleSplit #随机分拆样本获取指定数量交叉验证集函数
plt.rc('font',family='SimHei',size=10) #设置黑体,大小为10
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴负数的负号显示问题
def do_learning_curve(estimator,title,X,y,cv=None,n_jobs=1,train_sizes=np.linspace(0.1,1.0,5)):
plt.xlabel("训练集样本数")
plt.ylabel("验证集预测准确分数")
plt.title(title)
train_sizes,train_scores,test_scores = learning_curve(
estimator,X,y,cv=cv,n_jobs=n_jobs,train_sizes=train_sizes) #学习曲线观测
print('训练集准确度大小',train_scores.shape)
train_scores_mean = np.mean(train_scores,axis=1) #训练集训练结果取n次交叉验证得分平均值
test_scores_mean = np.mean(test_scores,axis=1) #验证集预测结果取n次交叉验证得分平均值
plt.plot(train_sizes,train_scores_mean,'bo-',label="训练集准确度得分") #绘制训练集5点的训练准确度
plt.plot(train_sizes,test_scores_mean,'go-',label="交叉验证准确度得分") #绘制验证集5点的训练准确度
plt.legend(loc="best")
plt.show()
digits = load_digits() #装入手写字样本数据集
X,y = digits.data,digits.target #获取样本数据和对应的标签值
#通过10次迭代进行交叉验证,获得更平滑的平均测试和训练得分曲线,每次随机取20%的数据作为验证集
cv = ShuffleSplit(n_splits=10,test_size=0.2,random_state=0) #随机获取10次交叉验证集
estimator = SVC(gamma=0.001) #创建SVC分类模型,默认值是'rbf'算法
do_learning_curve(estimator=estimator,title='高斯核算法-学习曲线',X=X,y=y,cv=cv,n_jobs=4)
estimator1 = SVC(gamma=0.001,kernel='sigmoid') #创建SVC分类模型,选择'sigmoid'算法
do_learning_curve(estimator=estimator1,title='S型核算法-学习曲线',X=X,y=y,cv=cv,n_jobs=4)
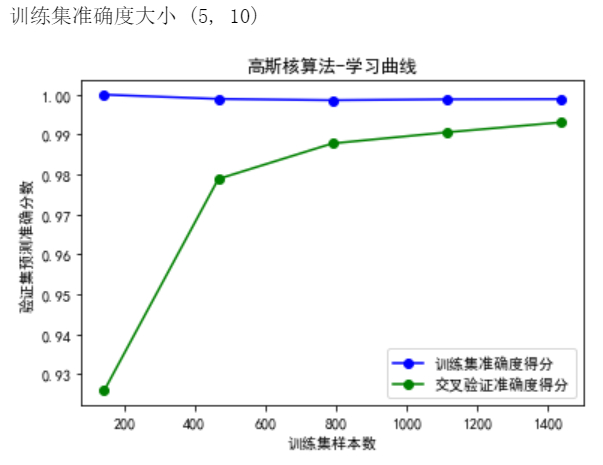
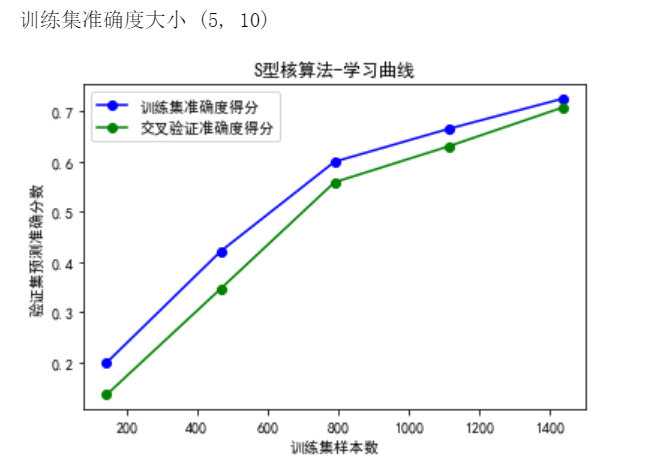
训练集准确度大小(5,10) ,5为5个验证点,10为每个点位10次交叉验证的准确值
从可视化结果看SVC模型的‘rbf’算法,通过交叉验证训练存在欠拟合现象,在样本数400范围内交叉验证准确度与训练集准确度值相差较大。随着样本数量大到400开始,两曲线日趋接近,拟合状况变好
从可视化结果看SVC模型的'sigmoid'算法,通过交叉验证训练拟合相似很好,能接受样本大小所带来的变化影响。
需要注意的是,采用'rbf'算法的预测准确度在[0.93,1]之间,而'sigmoid'算法只有[0.2,0.75]之间,无论是传统的Holdout验证方法还是交叉验证方法,'rbf'算法表现要远远好于'sigmoid'算法。因此,在实际应用中,这里应采用基于SVC模型的'rbf'算法,进行交叉验证训练,并产生更加强壮的模型。
10.3 dump函数固定模型
进过训练,评估认为较优的模型,应该固定下来,在实际应用时直接调用预测,而不是先训练再调用预测,这样可以节省大量时间。
Scikit-learn库提供了Python对象保存函数joblib.dump(),以文件形式保存经过训练的模型参数内容。函数如下
joblib.dump(value,filename,compress=0,protocol=None,cache_siw=None)
固定模型代码示例如下
from sklearn.externals import joblib
from sklearn.datasets import load_digits #导入小样本手写数字集
from sklearn.model_selection import train_test_split #导入样本随机分拆函数
Xtrain,Xtest,Ytrain,Ytest = train_test_split(digits.data,digits.target,test_size=0.2,random_state=1)
estimator.fit(Xtrain,Ytrain) #模拟拟合训练
joblib.dump(estimator,'digits_svc_g.m') #保存高斯核算法SVC模型到文件中
#=============================================================调用训练模型
from sklearn.datasets import load_digits #导入小样本手写函数
from sklearn.svm import SVC #导入C-支持向量分类模型
SVC_g = joblib.load('digits_svc_g.m') #把模型对象从文件中加载
tests = SVC_g.predict(Xtest) #测试集预测
SVC_g.score(Xtest,Ytest) #测试集预测准确度
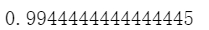
11、数据预处理
以上所使用样本数据都是Scikit-learn库自带的经过预处理后的规则数据,可以直接用来训练模型。但是,在实际情况下,采集的原始数据需要进行严格检查,根据数据的特点进行各种预处理后,才能被用于机器学习。数据预处理方法常用方法有标准化,正则化方法
11.1 数据预处理基础
原始采集的数据,根据数据类型可以分为数值型和非数值型。
11.1.1 原始采集数据存在的问题
(1) 特征值缺失,需要通过合适的方法进行弥补,使数据完整
(2) 特征之间的方差过大,使模型学习失败,需要通过标准化处理
(3) 对分类特征值仅提供了连续值,如果-2,-1,0,1,2,需要把该类特征值按照正负值进行分类
(4) 对于存在异常值的样本数据,如某城市地表监测温度值存在超过70°C的异常值,需要进行处理
(5) 一些机器学习模型无法处理非数值型数据,由此需要把该类数据进行数值化处理
(6) 一些机器学习模型需要提供标准化值的数据,使均值为0,方差为1
(7) 在训练数据不够多,训练模型结果存在过拟合问题时,需要通过正则化方法进行处理
11.2 标准化
数据集的标准化是将数据按比例进行缩放,将其转化为无量纲的纯数据,方便不同单位或量级的指标能够进行比较。如书的厚度、重量、价格,存在不同的单位和不同的数量级,如果不进行标准化处理,模型将无法很好地同时处理这些特征。这里介绍Z标准化和0-1范围缩放标准化
11.2.1 Z标准化(Zero-Score Normalization),又叫标准差标准化
对原始数据集去均值的中心化(特征值的均值为0)和方差的规范化(特征值的方差为1),代码如下
from sklearn import preprocessing
import numpy as np
Data = np.array([[100,98,78],[89,0.,100.],[0,99,95]])
S_data = preprocessing.scale(Data) #Z标准化处理
S_data #输出Z标准化结果
#====================================================验证标准化结果均值为0,方差为1
fm = S_data.mean(axis=0) #求每列特征值的均值
print('特征值均值为',fm)
print('特征值均值为%.2f,%.2f,%.2f'%(fm[0],fm[1],fm[2]))
fs=S_data.std(axis=0) #求每列特征值的方差
print('特征值方差',fs)
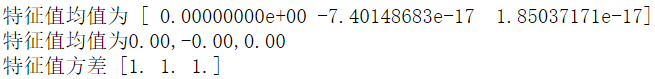
执行结果确定原始数据被处理成特征均值为0、方差为1的标准化数据
11.2.2 0-1范围缩放标准化
对原始数据集进行线性变换,使结果落在[0,1]区间,计算公式如下:
x=(x-min)/(max-min)
max、min分别为数据集的最大值和最小值,代码如下
from sklearn import preprocessing
import numpy as np
Data = np.array([[100,98,78],[89,0.,100.],[0,99,95]])
scaler = preprocessing.MinMaxScaler() #最大值,最小值配置
print(scaler.fit(Data)) #样本数据0-1化训练
print(scaler.transform(Data)) #转换为0-1范围的标准化

MinMaxScaler(copy=True,feature_range=(0,1))为0-1训练化结果
11.3 正则化
机器学习的分类或聚类需要用到数据的正则化。如用于文本内容的分类,对文本上下文内容的聚类。
Scikit-learn的preprocessing模块提供了正则化函数normalize(),函数如下
preprocessing.normalize(X,norm='12',axis=1,copy=True,return_norm=False),正则化代码如下
from sklearn import preprocessing
import numpy as np
Data = np.array([[100,98,78],[89,0.,100.],[0,99,95]])
n_2 = preprocessing.normalize(Data,norm='l2') #数据安装12标准进行正则化
n_2 #输出正则化结果

12 、识别图片库中的手写数字
写个数字5,然后拍成图片(F5_T.jpg),通过机器学习生成测试集,然后用生成的测试集,到图片库中进行模型识别,识别出数字5。
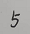
图片存放路径为Python安装路径下Python\Python37\site-packages\sklearn\datasets\images
#======================================================分析预处理图片
import matplotlib.pyplot as plt
from sklearn.datasets import load_sample_image
plt.rc('font',family='SimHei',size=10) #设置黑体,大小为10
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴负数的负号显示问题
Five = load_sample_image(r'F5_T.jpg') #从默认样本图片路径读取需要进行数字识别的图片
plt.imshow(Five) #显示图片
plt.title('手写5')
plt.show()
Five.shape #查看该图片的数据维度
'''
输出结果(28,28,3)
该图片的数组维度为三维,不符合digits或MNIST样本数据处理要求。从该数组的第一维度3可以知道图片存在RGB三个颜色通道,可以取第一个颜色通道值,使图片数组变成二维数组
'''
F1=Five[:,:,0] #保留第一维的第0个通道的值
F1 #观察图片的数组情况
'''
输出结果
array([[254,255,255,...,255,255,255],[255,255,255,...,254,254,253],[255,253253,...,0,2,0],[0,4,5,...,253,251,249],...])
该图片数值是范围从0到155的整数,大于200的都是代表图片的空白处,小于10的代表"5"的形状。数组维度为二维,满足样本数据的测试要求。
但是样本数据的空白都用0表示,其整数值英语表示手写数字的形状,尝试用0-1范围缩放标准化函数MinMaxScaler()来预处理数据
'''
#========================================================
#========================================================0-1范围缩放标准化
from sklearn import preprocessing
scaler = preprocessing.MinMaxScaler() #最大值,最小值配置
scaler.fit(F1) #样本数据0-1化训练
F2 = scaler.transform(F1) #转化为0-1范围的标准化
plt.imshow(F1) #显示0-1范围缩放标准化处理的图片效果
plt.title('手写5')
plt.show()
F2 #观察转化为0-1范围的标准化后的结果
'''
array([[0.75,1.,0.75,0.83333333,...,1.],[1.,1.,1.,...,0.33333333],...])
缩放后的数据值范围在[0,1]之间,将平均值以下的值置为True,平均值以上的值置为False,并转化为0、1。0值表示为图片的空白,1值表示为"5"的形状。
'''
C = np.ones((28,28))*0.5 #取中值,并产生28*28的均值数组
F3 = C>F2 #均值数值与同形状的"5"图片数组进行数值比较
F3 = F3.astype(int) #逻辑值转为整数,True转为1,False转为0
F3 #观察数组值
'''
array([[1,1,1,...,1],[1,1,1,...,0],...])
经过数据预处理后的数组数据具有很强的0、1数据特征,并较好的体现了"5"的形状,具备了手写数字预测的要求。
'''
#========================================================
#========================================================预处理后的数值进行模型识别
from sklearn.model_selection import train_test_split #导入样本分类器
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original') #加载70000张手写数字图片
x,y = mnist['data'],mnist['target'] #把图片数据赋值给x,把对应的标签值赋值给y
train_X,test_X,train_y,test_y = train_test_split(x,y,test_size=0.2,random_state=201) #按照4:1分割训练集
from sklearn import tree
tree_model = tree.DecisionTreeRegressor() #创立决策树回归模型
tree_model.fit(train_X,train_y) #对训练集数据进行模型学习
result = tree_model.predict([F3]) #对测试集数据"5"的图片数据进行预测
print(result) #输出预测分类结果
#结果为[5.],识别结果是数字5,跟实际图片内容一致
注意:手写图片的数字建议用圆珠笔写,字的粗细、字型的大幅变换会影响识别的准确度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号