2023-学习记录16-CNN
卷积神经网络结构介绍
如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
(1)首先将图像展开为向量会丢失空间信息;
(2)其次参数过多效率低下,训练困难;
(3)同时大量的参数也很快会导致网络过拟合。
而使用卷积神经网络可以很好地解决上面的三个问题。
与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度。其中的宽度和高度是很好理解的,因为本身卷积就是一个二维模板,但是在卷积神经网络中的深度指的是激活数据体的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。举个例子来理解什么是宽度,高度和深度,假如使用CIFAR-10中的图像是作为卷积神经网络的输入,该输入数据体的维度是32x32x3(宽度,高度和深度)。我们将看到,层中的神经元将只与前一层中的一小块区域连接,而不是采取全连接方式。
构建卷积神经网络的各种层
卷积神经网络主要由这几类层构成:输入层、卷积层,ReLU层、池化(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。在实际应用中往往将卷积层与ReLU层共同称之为卷积层,所以卷积层经过卷积操作也是要经过激活函数的。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数,即神经元的权值w和偏差b;而ReLU层和池化层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
2.1 卷积层
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。注意是计算量而不是参数量。
2.1.1 卷积层作用
1. 滤波器的作用或者说是卷积的作用。卷积层的参数是有一些可学习的滤波器集合构成的。每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据一致(这一点很重要,后面会具体介绍)。直观地来说,网络会让滤波器学习到当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案。
2. 可以被看做是神经元的一个输出。神经元只观察输入数据中的一小部分,并且和空间上左右两边的所有神经元共享参数(因为这些数字都是使用同一个滤波器得到的结果)。
3. 降低参数的数量。这个由于卷积具有“权值共享”这样的特性,可以降低参数数量,达到降低计算开销,防止由于参数过多而造成过拟合。
2.1.2 重点理解
在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。相反,我们让每个神经元只与输入数据的一个局部区域连接。该连接的空间大小叫做神经元的感受野(receptive field),它的尺寸是一个超参数(其实就是滤波器的空间尺寸)。在深度方向上,这个连接的大小总是和输入量的深度相等。需要再次强调的是,我们对待空间维度(宽和高)与深度维度是不同的:连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
2.2 池化层
通常在连续的卷积层之间会周期性地插入一个池化层。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。汇聚层使用 MAX 操作,对输入数据体的每一个深度切片独立进行操作,改变它的空间尺寸。最常见的形式是汇聚层使用尺寸2x2的滤波器,以步长为2来对每个深度切片进行降采样,将其中75%的激活信息都丢掉。每个MAX操作是从4个数字中取最大值(也就是在深度切片中某个2x2的区域),深度保持不变。
汇聚层的一些公式:输入数据体尺寸 ,有两个超参数:空间大小FF和步长SS;输出数据体的尺寸
,其中
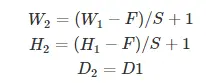
这里面与之前的卷积的尺寸计算的区别主要在于两点,首先在池化的过程中基本不会进行另补充;其次池化前后深度不变。
在实践中,最大池化层通常只有两种形式:一种是F=3,S=2F=3,S=2,也叫重叠汇聚(overlapping pooling),另一个更常用的是F=2,S=2F=2,S=2。对更大感受野进行池化需要的池化尺寸也更大,而且往往对网络有破坏性。
普通池化(General Pooling):除了最大池化,池化单元还可以使用其他的函数,比如平均池化(average pooling)或L-2范式池化(L2-norm pooling)。平均池化历史上比较常用,但是现在已经很少使用了。因为实践证明,最大池化的效果比平均池化要好。
反向传播:回顾一下反向传播的内容,其中max(x,y)函数的反向传播可以简单理解为将梯度只沿最大的数回传。因此,在向前传播经过汇聚层的时候,通常会把池中最大元素的索引记录下来(有时这个也叫作道岔(switches)),这样在反向传播的时候梯度的路由就很高效。(具体如何实现我也不是很懂)。
不使用汇聚层:很多人不喜欢汇聚操作,认为可以不使用它。比如在Striving for Simplicity: The All Convolutional Net一文中,提出使用一种只有重复的卷积层组成的结构,抛弃汇聚层。通过在卷积层中使用更大的步长来降低数据体的尺寸。有发现认为,在训练一个良好的生成模型时,弃用汇聚层也是很重要的。比如变化自编码器(VAEs:variational autoencoders)和生成性对抗网络(GANs:generative adversarial networks)。现在看起来,未来的卷积网络结构中,可能会很少使用甚至不使用汇聚层。
2.3 归一化层
在卷积神经网络的结构中,提出了很多不同类型的归一化层,有时候是为了实现在生物大脑中观测到的抑制机制。但是这些层渐渐都不再流行,因为实践证明它们的效果即使存在,也是极其有限的。
2.4 全连接层
这个常规神经网络中一样,它们的激活可以先用矩阵乘法,再加上偏差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号