04.大型数据库应用技术课堂测试-日志数据分析
测试题目:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
测试要求:
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据分析:在HIVE统计下列数据。
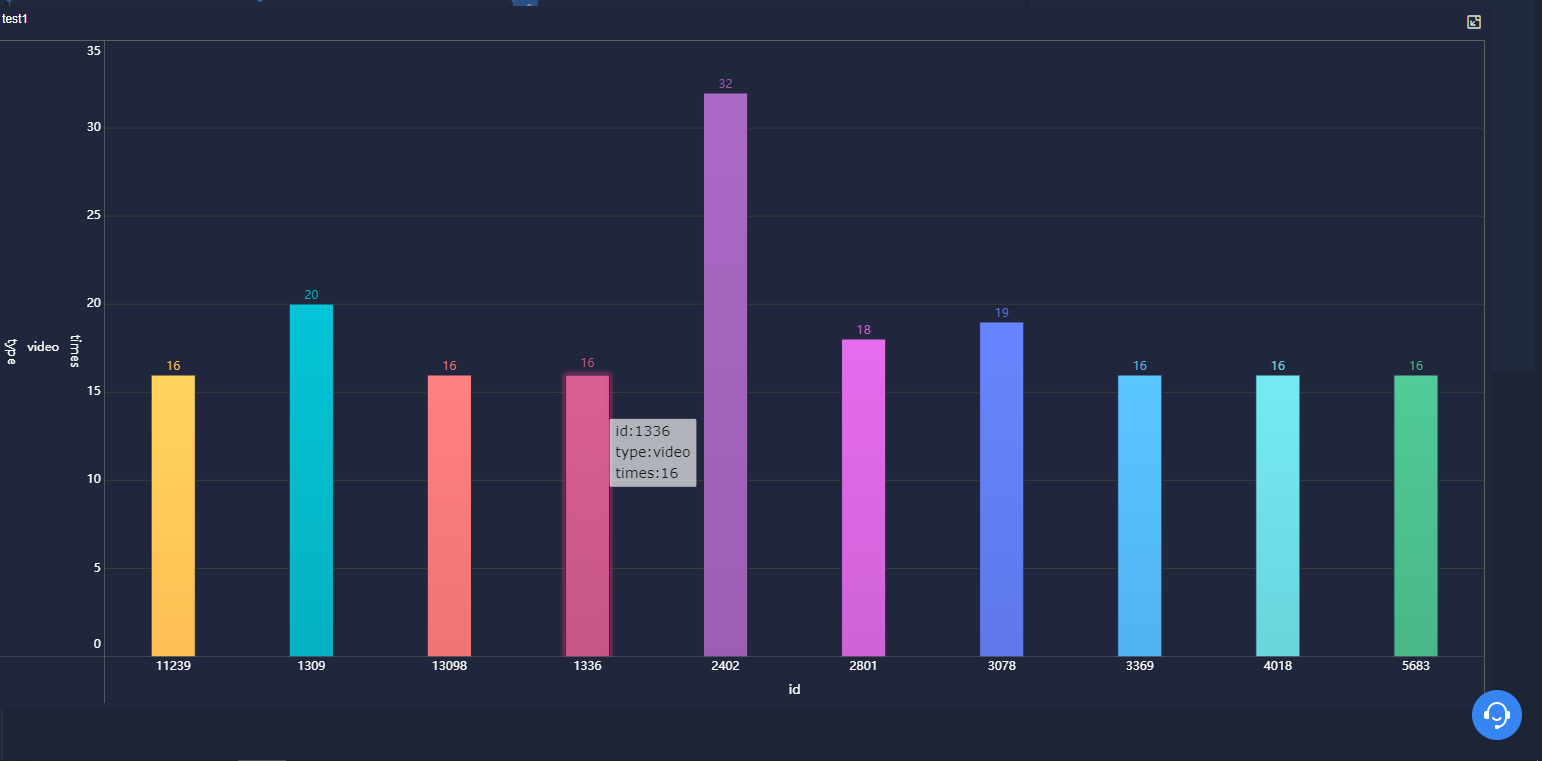
(1)统计最受欢迎的视频/文章的Top10访问次数 (video/article)
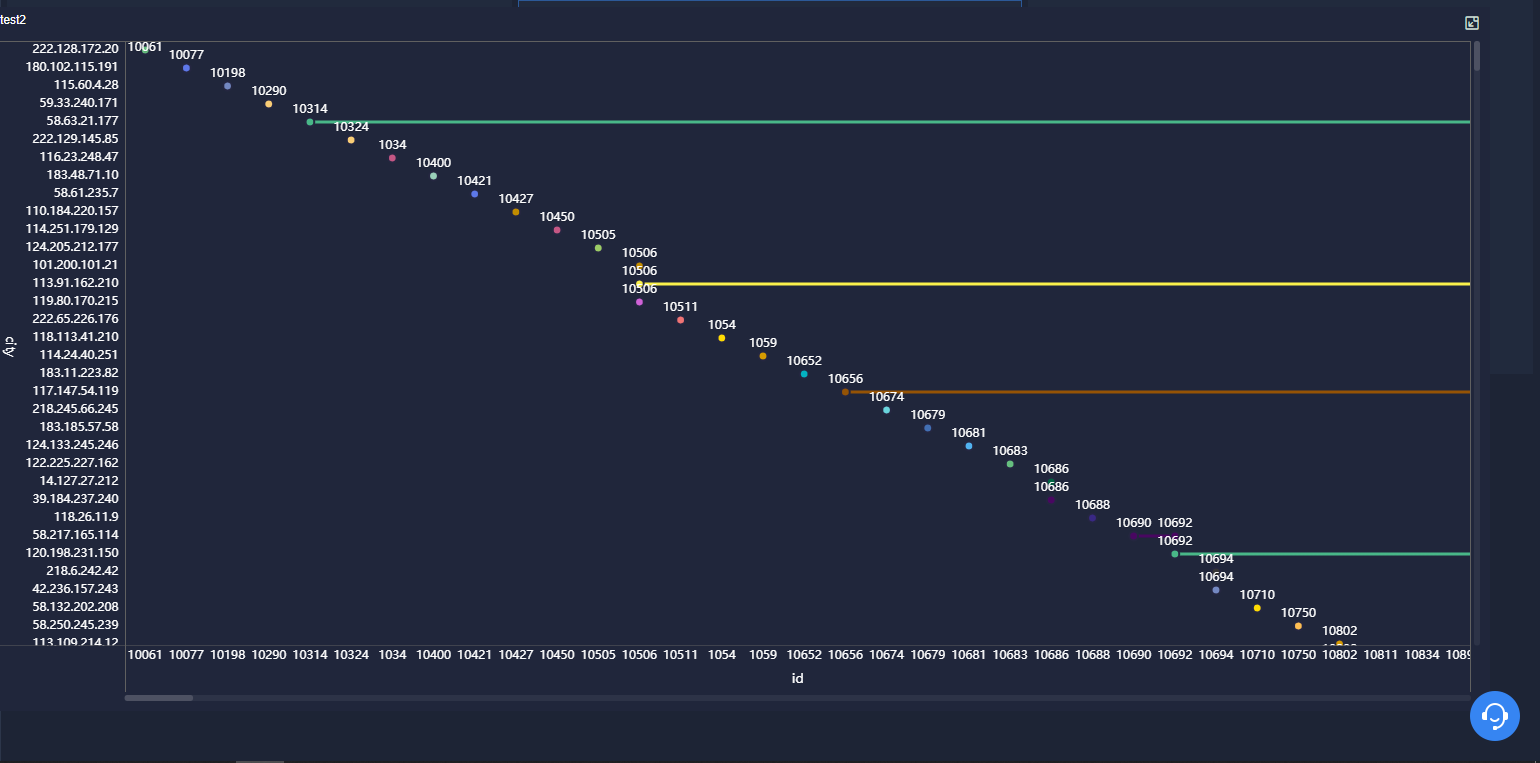
(2)按照地市统计最受欢迎的Top10课程 (ip)
(3)按照流量统计最受欢迎的Top10课程 (traffic)
3、数据可视化:
将统计结果倒入MySql数据库中,通过图形化展示的方式展现出来。
实现过程:
1.数据导入
1.1.将txt 文件转csv文件,从win 到 opt/software 目录下
1.2.hive 建表
create table `test20221018`(
`ip` string,
`Date` string,
`day` string,
`traffic` string,
`type` string,
`id` string
)
ROW format delimited fields terminated by ',' STORED AS TEXTFILE;
1.3.向hive 导入csv文件:
hadoop目录下执行命令:
hadoop fs -put /opt/software/result.csv /user/hive/warehouse/hive20221018.db/test20221018
2.数据清洗
2.1.时间格式转换
public class DataClean { static String INPUT_PATH="hdfs://192.168.57.128:9000/testhdfs1026/run/input/DataClean.txt"; static String OUTPUT_PATH="hdfs://192.168.57.128:9000/testhdfs1026/run/output/DataClean"; /* * 数据格式: * Ip Date Day|Traffic|Type|Id * 106.39.41.166,10/Nov/2016:00:01:02 +0800,10,54,video,8701 */ public static final SimpleDateFormat FORMAT = new SimpleDateFormat("d/MMM/yyyy:HH:mm:ss", Locale.ENGLISH); //原时间格式 public static final SimpleDateFormat dateformat1 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//现时间格式 //提取数据的函数 ######################################################################################### //将一行数据清洗整合到一个字符串数组里 parse:解析 //String line --> String[] public static String[] parse(String line){ String ip = parseIP(line); String date = parseTime(line); String day = parseDay(line); String traffic = parseTraffic(line); String type = parseType(line); String id = parseId(line); return new String[]{ip,date,day,traffic,type,id}; } //Ip private static String parseIP(String line) { String ip =line.split(",")[0].trim(); return ip; } //Date private static String parseTime(String line) { //time=日期String String time =line.split(",")[1].trim(); //截取最后的" +0800" final int f = time.indexOf(" "); String time1 = time.substring(0, f); Date date = parseDateFormat(time1); return dateformat1.format(date); } //把String类型转换成Date类型 private static Date parseDateFormat(String string){ Date parse = null; try{ parse = FORMAT.parse(string);//parse()方法,把String型的字符串转换成特定格式的date类型 }catch (Exception e){ e.printStackTrace(); } return parse; } //Day private static String parseDay(String line) { String day =line.split(",")[2].trim(); return day; } //Traffic private static String parseTraffic(String line) { String traffic = line.split(",")[3].trim(); return traffic; } //Type private static String parseType(String line) { String type = line.split(",")[4].trim(); return type; } //Id private static String parseId(String line) { String id =line.split(",")[5].trim(); return id; } /* * Mapper * 把需要的信息从原始日志中提取出来,根据提取出来的信息做精细化操作 */ public static class Map extends Mapper<LongWritable,Text,Text,NullWritable>{ public static Text word = new Text(); public void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{ String line = value.toString(); String arr[] = parse(line); word.set(arr[0]+"\t"+arr[1]+"\t"+arr[2]+"\t"+arr[3]+"\t"+arr[4]+"\t"+arr[5]+"\t"); context.write(word,NullWritable.get()); } } public static class Reduce extends Reducer<Text,NullWritable,Text,NullWritable>{ public void reduce(Text key, Iterable<NullWritable> values,Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } public static void main(String[] args) throws Exception{ Path inputpath=new Path(INPUT_PATH); Path outputpath=new Path(OUTPUT_PATH); Configuration conf=new Configuration(); System.out.println("Start"); Job job=Job.getInstance(conf); job.setJarByClass(DataClean.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.addInputPaths(job, INPUT_PATH); FileOutputFormat.setOutputPath(job,outputpath); boolean flag = job.waitForCompletion(true); System.out.println(flag); System.exit(flag? 0 : 1); } }
验证格式是否更改成功:
在hive中使用 select
3.数据分析
注意:下面sql在hive中执行
3.1.统计最受欢迎的视频/文章的Top10访问次数
drop table test20221018_1; create table test20221018_1 as (select type, id, count(*) as times from test20221018 group by type, id order by times DESC limit 10); select * from test20221018_1;
3.2.按照地市统计最受欢迎的Top10课程
drop table test20221018_test2; create table test20221018_test2 as (select CONCAT(split(ip,'\\.')[0],'.',split(ip,'\\.')[1]) as city, ip, traffic, type, id from test20221018); select * from test20221018_test2 limit 10; drop table test20221018_2; create table test20221018_2 as select city, type, id, count(*) as cishu from test20221018_test2 group by city,type,id order by cishu DESC; select * from test20221018_2;
3.3.按照流量统计最受欢迎的Top10课程
drop table test20221018_3; create table test20221018_3 as select type, id, sum(traffic) as liulian from test20221018_test2 group by type,id order by liulian DESC limit 10; select * from test20221018_3;
4.数据可视化
4.1.数据可视化echarts,这里推荐大家使用 fineBI 这个软件,看黑马教程
10-基于FineBI实现可视化报表--配置数据源及数据准备_哔哩哔哩_bilibili
4.2.柱状图
4.3.点图
4.4.环状图
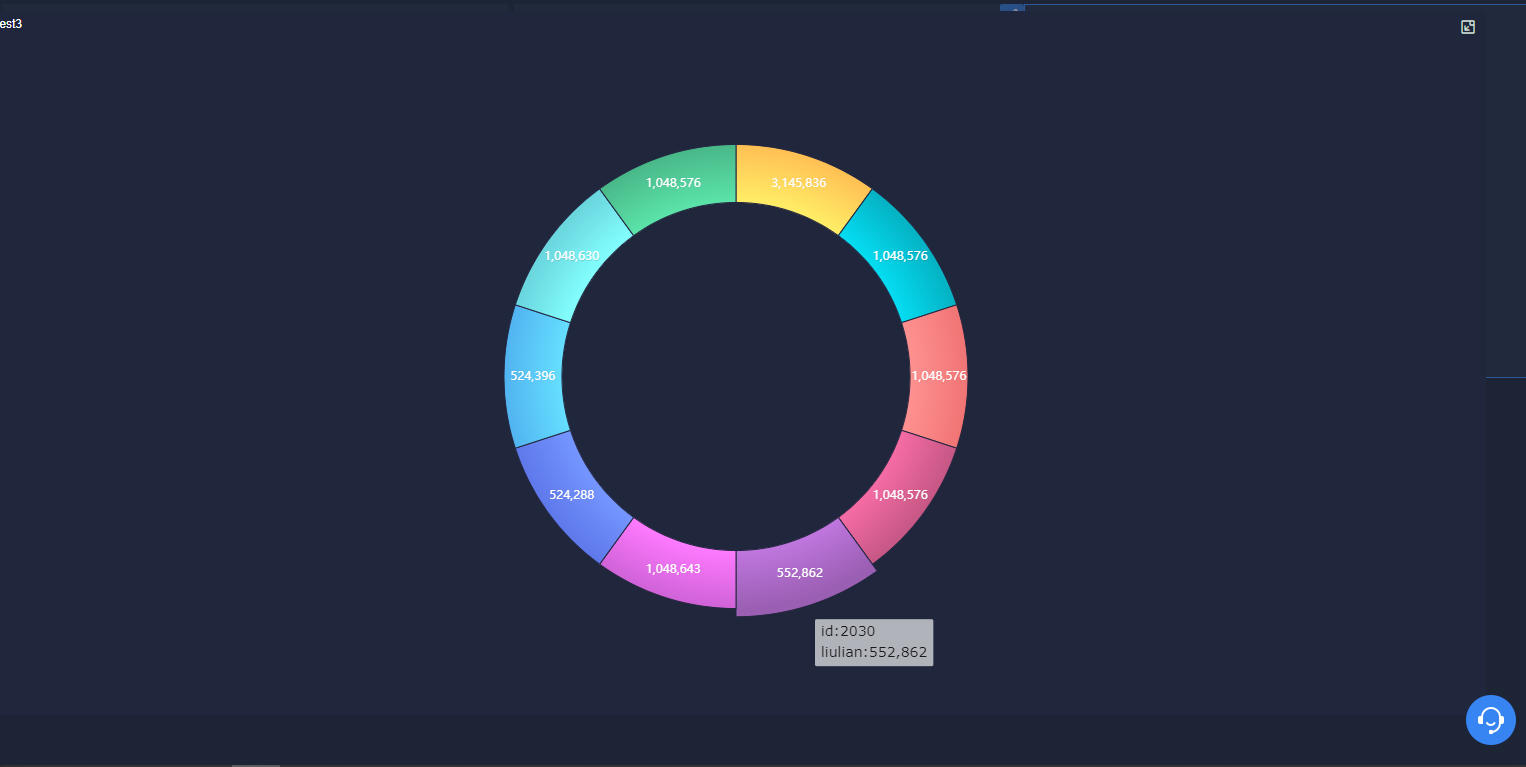
不得不说,这图比自己做好看的多了,推荐大家使用
下期出一期错误总结,大家可以参考参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号