python 基础---正则
在线测试工具 http://tool.chinaz.com/regex/


import re
re.findall : def findall(pattern, string, flags=0)
re.search : def search(pattern, string, flags=0)
re.match : def match(pattern, string, flags=0)
flags有很多可选值:
re.I(IGNORECASE)忽略大小写,括号内是完整的写法
re.M(MULTILINE)多行模式,改变^和$的行为
re.S(DOTALL)点可以匹配任意字符,包括换行符
re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
re.U(UNICODE)使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释
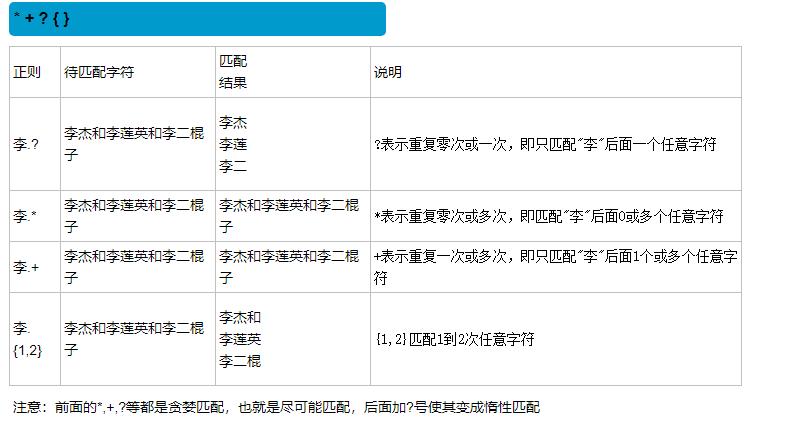
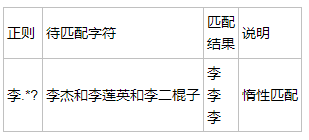
1 # ?在正则三用法:
2 #1.做量词表示零次或者一次
3 #2.放量词后面表示惰性匹配标志
4 #3.在findall里面代表取消分组优先
5
6 # while True:
7 # phone_number = input('please input your phone number : ')
8 # if len(phone_number) == 11 \
9 # and phone_number.isdigit()\
10 # and (phone_number.startswith('13') \
11 # or phone_number.startswith('14') \
12 # or phone_number.startswith('15') \
13 # or phone_number.startswith('18')):
14 # print('是合法的手机号码')
15 # else:
16 # print('不是合法的手机号码')
17 #
18 # import re
19 # phone_number = input('please input your phone number : ')
20 # if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
21 # print('是合法的手机号码')
22 # else:
23 # print('不是合法的手机号码')
24
25 import re
26 # findall
27 # search
28 # match
29
30 # findall
31 # ret = re.findall('[a-z]+','eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
32 # print( ret )
33
34 # search
35 # ret = re.search('a','eva egon yuan')
36 # # 从前往后,找到一个就返回,返回的变量需要调用group才能拿到结果
37 # # 如果没有找到,那么返回None,调用group会报错
38 # # print(ret)
39 # # print(ret.group())
40 # if ret:
41 # print(ret.group())
42
43 # match
44 # ret = re.match('ev','eva egon yuan')
45 # if ret:
46 # print(ret.group())
47 # # match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个变量。
48 # # 匹配的内容需要用group才能显示
49 # # 如果没匹配上,就返回None,调用group会报错
50
51 # split
52 # ret = re.split('[ab]','abcd')
53 # # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
54 # print(ret)
55
56 # sub
57 # ret = re.sub('\d','H','eva3egon4yuan4',1)
58 # #将数字替换成'H',参数1表示只替换1个
59 # print(ret)
60
61 # subn
62 # ret = re.subn('\d','H','eva3egon4yuan4')
63 # ##将数字替换成'H',返回元组(替换的结果,替换了多少次)
64 # print(ret)
65
66 # compile
67 # 正则规则经常要用,就可以使用compile进行编译,然后用这对象进行re模块内方法的调用
68 # obj = re.compile('\d{3}')
69 # #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
70 # ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
71 # print(ret.group())
72 # ret = obj.search('abcashgjgsdghkash456eeee3wr2') #正则表达式对象调用search,参数为待匹配的字符串
73 # print(ret.group())
74
75 # finditer
76 # ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
77 # print(ret) # <callable_iterator object at 0x10195f940>
78 # # print(next(ret).group()) #查看第一个结果
79 # # print(next(ret).group()) #查看第二个结果
80 # # print([i.group() for i in ret]) #查看剩余的左右结果
81 # for i in ret:
82 # print(i.group())
83
84 # search 取分组
85 # ret = re.search('^[1-9]\d{14}(\d{2}[0-9x])?$','110105199912122277')
86 # print(ret.group())
87 # print(ret.group(1))
88
89 # findall 没有分组机制
90 # ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
91 # print(ret) # ['oldboy']
92 # # 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
93 # # 改为
94 # ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com')
95 # print(ret) # ['www.oldboy.com']
96
97 # split 分组
98 ret =re.split('\d+','eva3egon4yuan')
99 print(ret) #结果 : ['eva', 'egon', 'yuan']
100
101 ret = re.split('(\d+)','eva3egon4yuan')
102 print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号