Python自动化登录验证码问题解决
1.测试环境中通常解决验证码问题的方法
在测试环境中我们通常通过各种手段来逃避或者获得验证,而这些手段主要是要求开发者在开发的时候留有一定的后门。下面简述几种:
1、使用万能验证码,这种方法就是在判断验证的时候,如果遇到前台输入的是万能验证码,那就不要做验证码校验直接通过。
2、特定用户跳过验证码,这种方法就是如果遇到指定用户登录,那么不管输入什么验证码,验证码校验都通过。
3、使用hidden 控件在页面上显示验证码,就是在使用验证码的页面上,加入一个隐藏的控件,该控件的内容就是验证码。虽然用户看不到但是自动化测试工具可以找到该控件,并获得验证码。当然隐藏控件中的验证码也可以使用加密的方法,自动化测试脚本得到加密的验证后,可以通过解密操作解密验证码。
上述的方法都需要开发对代码进行一定的修改,最好不要在生产环境上做,不然会造成安全漏洞。
2.通过OCR识别解决验证码问题
在正式环境中通常不能使用上面的几种方法去处理验证码问题,下面是我通过Python的第三方库pytesseract解决验证码的过程;
识别的方法,优点在于完全不用考虑服务端,直接通过图像识别的技术(如OCR技术),通过识别图片来破解验证码。这种方法优点就在于不需要服务器端做任何修改,不用提供任何接口,自动化测试便可以完成自己的验证码识别。但是这种方法也有致命的缺点,就是它的识别成功率的问题,在存在变形和背景加入噪音的验证码中,这种识别率相当的低。如果验证码还存在中文的话,那识别成功率就几乎难以忍受了。这种方法我们在以往的实践经验中,曾经使用OCR技术处理过验证码。但是最近遇到一些验证码,使用OCR的识别率都很低。
简单说明一下为什么OCR的识别率比较低,OCR是光学字符识别的简称,他一般用来识别等大规则字体的图像,比方说他可以扫描印刷的图书,将纸质的书扫描到计算机中形成文本;也可以用来识别证件号码,加快机读证件速度。所以如果在验证不规整或者存在噪点,那么识别率会直线下降。但是市面上有些人做的验证码识别程序为什么识别率那么高而通用的OCR识别程序识别率低呢?由于验证码的生成时的变形和加入噪点是存在规律的,开发者可以通过这些规律,为特定的验证码生成程序编写特定的识别代码,这种情况下的识别率是非常高的。还有为什么中文识别率低?这个就比较好理解了,想想英文只有26个字母,26种形态,我们中文一个字一个形态。还有在OCR识别的时候,他的算法可能会通过识别部分来确认全部,有点盲人摸象的感觉(具体的算法可以参照OCR具体的实现算法),在这种情况下,如果中文有稍微的变形就很难识别的了。如果不能理解这点,想想我们小学学习那些形近字的痛苦,也就知道对于计算机是多难了。
————————————————
版权声明:本文为CSDN博主「程序员威子」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/okcross0/article/details/126840243
2.1 安装tesseract-OCR
在网页下载对应的安装程序,然后根据默认安装,一般默认安装目录:C:\Program Files\Tesseract-OCR
安装地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe
然后添加环境变量,首先在系统变量path中添加Tesseract-OCR的安装目录
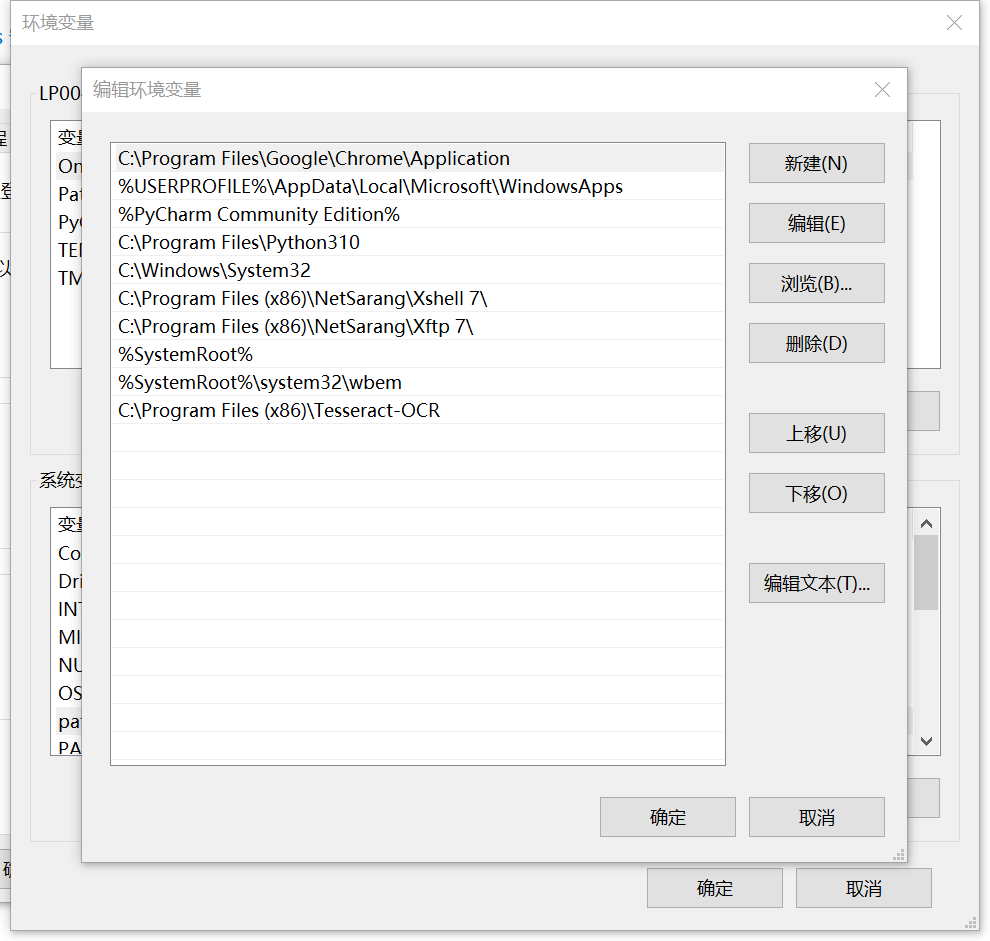
然后新建一个变量名和值,变量名TESSDATA_PREFIX,变量值为Tesseract-OCR的tessdata目录

添加环境变量后,重启电脑
现在我们cmd里面就可以使用tesseract了,但是在pycharm里面还不行
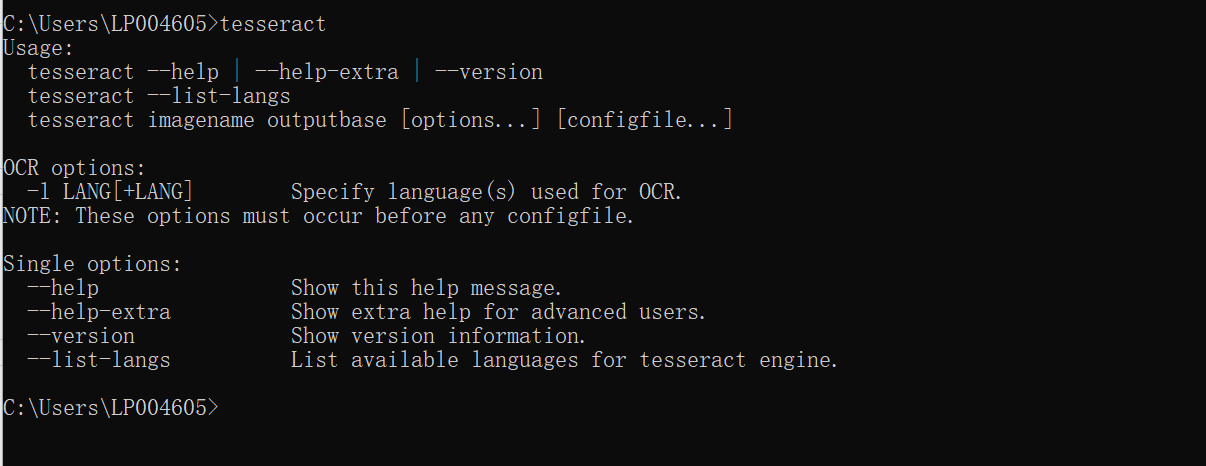
因为在pycharm中pytesseract模块没有配置路径
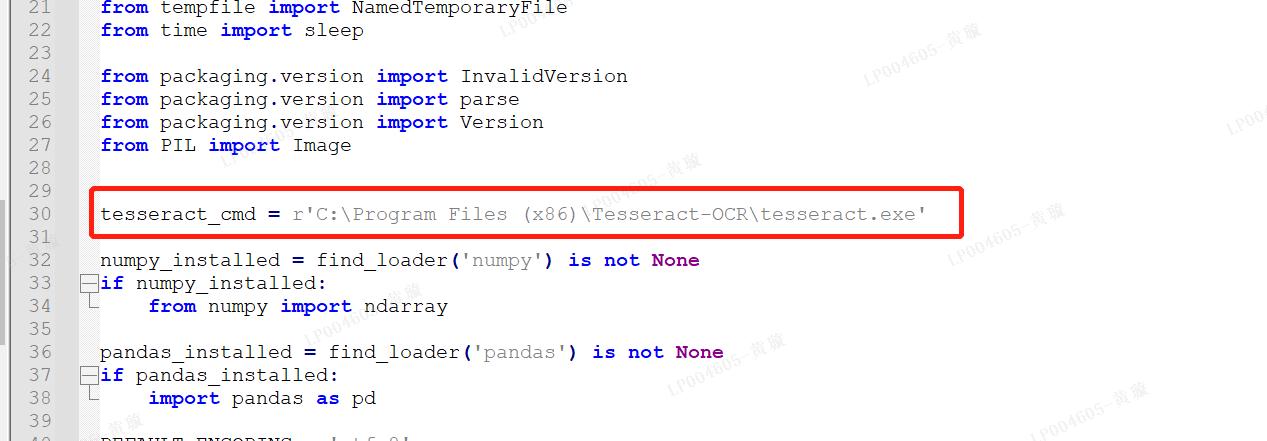
在我们安装pytesseract这个库的解释器路径下找到pytesseract.py文件,打开
将tesseract_cmd路径替换成tesseract_OCR目录下tesseract.exe文件的路径
2.2 安装Pillow和pytesseract模块
在cmd中通过pip安装这两个模块时报错Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None))...
安装命令:py -3.10 -m pip install pytesseract
原因:
其实就是找第三方库的时候链接超时,总是获取不到。自带的pip命令去国外的服务器请求第三方包了,所以超时,因而换成国内镜像下载即可,并且要信任镜像的URL。
解决:
改为国内镜像源下载
常用国内源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
以清华大学镜像源下载为例:
一、直接使用镜像源下载
二、配置默认使用某镜像源下载
1.找到系统盘下C:\C:\Users\用户名\AppData\Roaming
2.查看在Roaming文件夹下创建一个pip文件夹;
3.进入pip文件夹,创建一个pip.ini文件;
4.使用记事本的方式打开pip.ini文件,写入以下内容保存:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple # 指定下载源
trusted-host = mirrors.aliyun.com # 指定域名记得一定要删掉注释

2.3 代码

from selenium import webdriver from PIL import Image import pytesseract import time from selenium.webdriver.common.by import By driver=webdriver.Chrome() driver.get("地址URL") driver.maximize_window() driver.find_element(By.XPATH,"//input[@type='text']").send_keys("登录名") driver.find_element(By.XPATH,"//input[@type='password']").send_keys("密码") #获取验证码的图片 driver.find_element(By.XPATH,'//*[@id="userLayout"]/div/div[1]/div[1]/div[2]/div/div/form/div[1]/form/div[3]/div[2]/img').screenshot('3.png' '') #获取图片信息 image=Image.open("3.png") #识别图片验证码 vcode=pytesseract.image_to_string(image) # print(vcode,len(vcode)) time.sleep(1) driver.find_element(By.XPATH,'//span/span/input').send_keys(vcode) driver.find_element(By.XPATH,"//button[@type='submit']").click()
经过测试,OCR识别验证码的结果没有那么理想,准确率没有那么高


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现