4.K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
import matplotlib.pyplot as pillow #导入所需要的包
mortyimage=pillow.imread("./morty.png") #导入自备的图片Morty!!!!!
pillow.imshow(mortyimage) #显示图片

观察图片文件大小,占内存大小,图片数据结构,线性化
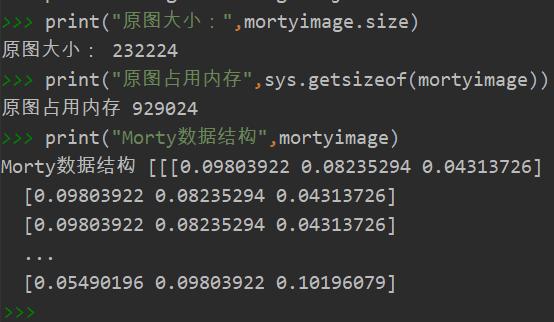
print("原图大小:",mortyimage.size) print("原图占用内存",sys.getsizeof(mortyimage)) print("Morty数据结构",mortyimage)

用kmeans对图片像素颜色进行聚类
n_colors =64 #将颜色聚成64类
K_model = KMeans(n_colors)
获取每个像素的颜色类别,每个类别的颜色
labels = K_model.fit_predict(X)
colors = K_model.cluster_centers_
print(labels.shape,colors.shape)

压缩图片生成:以聚类中收替代原像素颜色,还原为二维

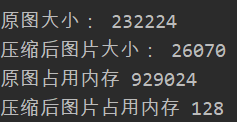
观察压缩图片的文件大小,占内存大小
mortyimg=mortyimage[::3,::3] #每三个像素取一个像素
print("原图大小:",mortyimage.size)
print("压缩后图片大小:",mortyimg.size)
print("原图占用内存",sys.getsizeof(mortyimage))
print("压缩后图片占用内存",sys.getsizeof(mortyimg))
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
事先网上爬取数据,进行油耗排量的K均值算法
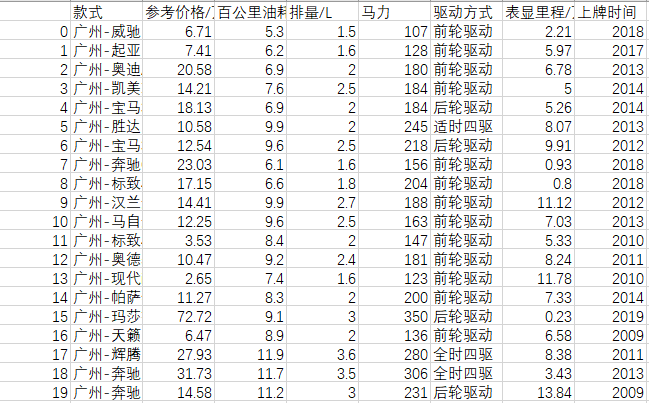
实验代码如下:
import numpy as np
from sklearn.cluster import KMeans
import pandas as pd
data = pd.read_csv('./201706120033 段泽平.csv')
x= data.iloc[:,[3,4]].astype('int')
x= np.array(x)
km_model=KMeans(n_clusters=3) #将油耗分为高中低三类
km_model.fit(x) #训练模型
a_Kmeans=km_model.predict(x) #预测模型
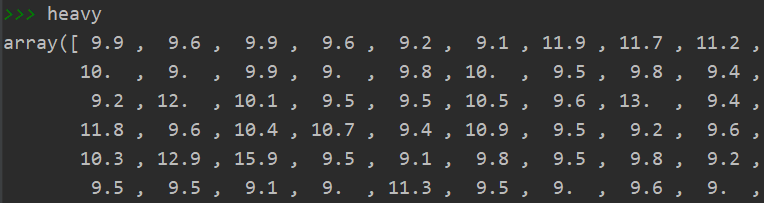
heavy = np.array(data[a_Kmeans==0]['百公里油耗/L'])
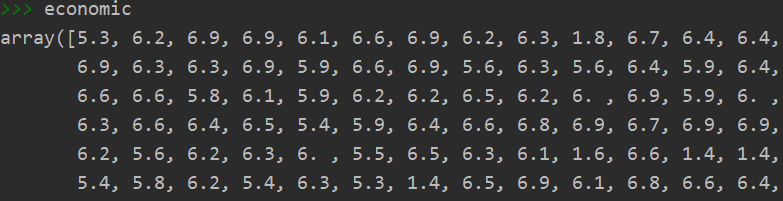
economic = np.array(data[a_Kmeans==1]['百公里油耗/L'])
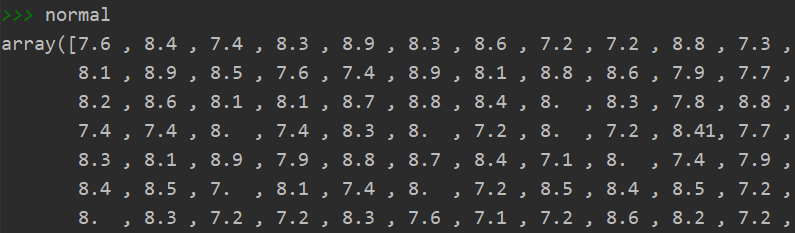
normal = np.array(data[a_Kmeans==2]['百公里油耗/L'])
经济型:
正常类型:
费油型


 浙公网安备 33010602011771号
浙公网安备 33010602011771号