Improvements since Nature DQN / 2014~2016
Intro
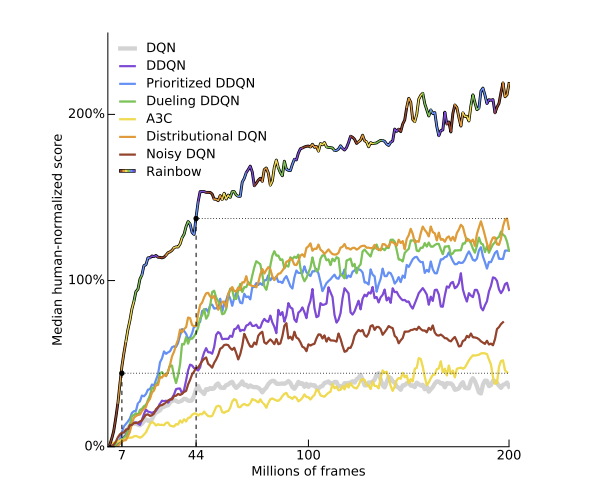
如果想省时间,建议直接看:Rainbow
Deep Q Network(Vanilla DQN)
抓两个点:
- Replay Buffer
- Target Network
详细见:https://www.cnblogs.com/dynmi/p/13994342.html
更新evaluate-network的损失函数:
\(Loss = (r + \gamma * max_{a' \in A}Q(s',a'|\theta^{-})-Q(s,a|\theta))^2\)
paper:
https://www.nature.com/articles/nature14236
official code:
https://sites.google.com/a/deepmind.com/dqn/ nature.com/nature
Double DQN
较Vanilla DQN只修改了TD target计算方法,它的损失函数是:
\(Loss = (r+ \gamma * Q(s',argmax_{a'}Q(s',a'|\theta)|\theta^{-})-Q(s,a|\theta))^2\)
Priorited Replay Buffer
详细见:https://www.cnblogs.com/dynmi/p/14004610.html
Duelling network
针对DQN的模型构造作出修改,将最后一层分出两个channel,然后对两个channel合并作为输出。
- Action-independent value function \(V(s, v)\)
- Action-dependent advantage function \(A(s, a, w)\)
- \(Q(s, a) = V(s, v) + A(s, a, w)\)
结构图对比:

Rainbow
正如其名“七色彩虹”,这个算法就是多个算法的糅合。
将Double DQN的TD Target, Prioritied Replay Buffer, Duelling DQN的模型结构,Multi-step Learning,Distribution RL,NoisyNet组合到一起,就成了结合体Rainbow。
Reference
- David Silver, ICML2016, Deep RL Tutorial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号