<强化学习>基于采样迭代优化agent
前面介绍了三种采样求均值的算法
——MC
——TD
——TD(lamda)
下面我们基于这几种方法来 迭代优化agent
传统的强化学习算法
||
ν
ν
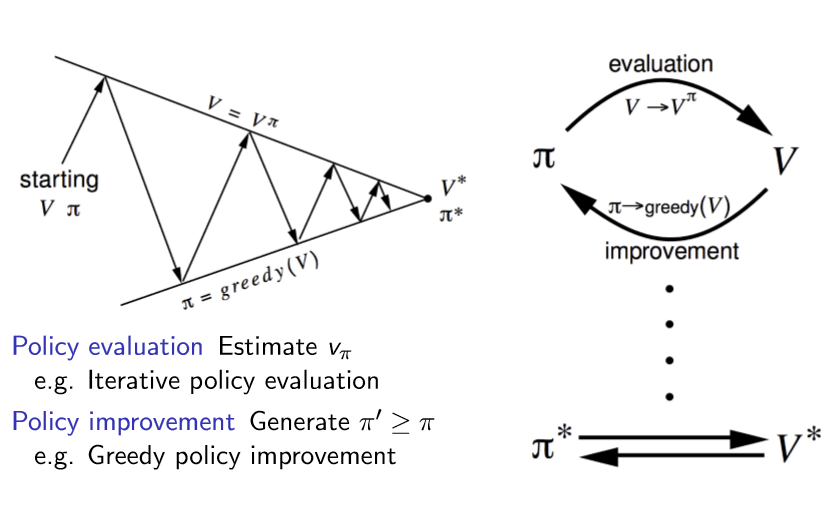
已经知道完整MDP——使用价值函数V(s)
没有给出完整MDP——使用价值函数Q(s,a)
可见我们的目标就是确定下来最优策略和最优价值函数
|
|——有完整MDP && 用DP解决复杂度较低
| ====》 使用贝尔曼方程和贝尔曼最优方程求解
|——没有完整MDP(ENV未知) or 知道MDP但是硬解MDP问题复杂度太高
| ====》 policy evaluation使用采样求均值的方法
| |—— ON-POLICY MC
| |—— ON-POLICY TD
| |____ OFF-POLICY TD
1 价值函数是V(s)还是Q(s,a)?
agent对外界好坏的认识是对什么的认识呢?是每一个状态s的好坏还是特定状态下采取特定行为(s,a)的好坏?
这取决于是什么样的问题背景。
有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态的好坏。如sutton书中的jack‘s car rental问题,方格问题等等,这些都是事先就明确知道状态行为转移概率矩阵的。丝毫没有“人工智能”的感觉。
没有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态行为对(s,a)的好坏。比如,围棋!我们下子之后,对手会把棋落哪是完全没法预测的,所以后继state是绝对不可预测,所以agent是不能用V(s)作为评价好坏的价值函数,所以agent应该在乎的是这个(s,a)好这个(s,a)不好,所以使用Q(s,a)作为价值函数。
2. ON-POLICY 和OFF-POLICY
on policy :基于策略A采样获取episode,并且被迭代优化的策略也是A
off policy :基于策略A采样获取episode,而被迭代优化的策略是B
3.为什么ε-greedy探索在on policyRL算法中行之有效?
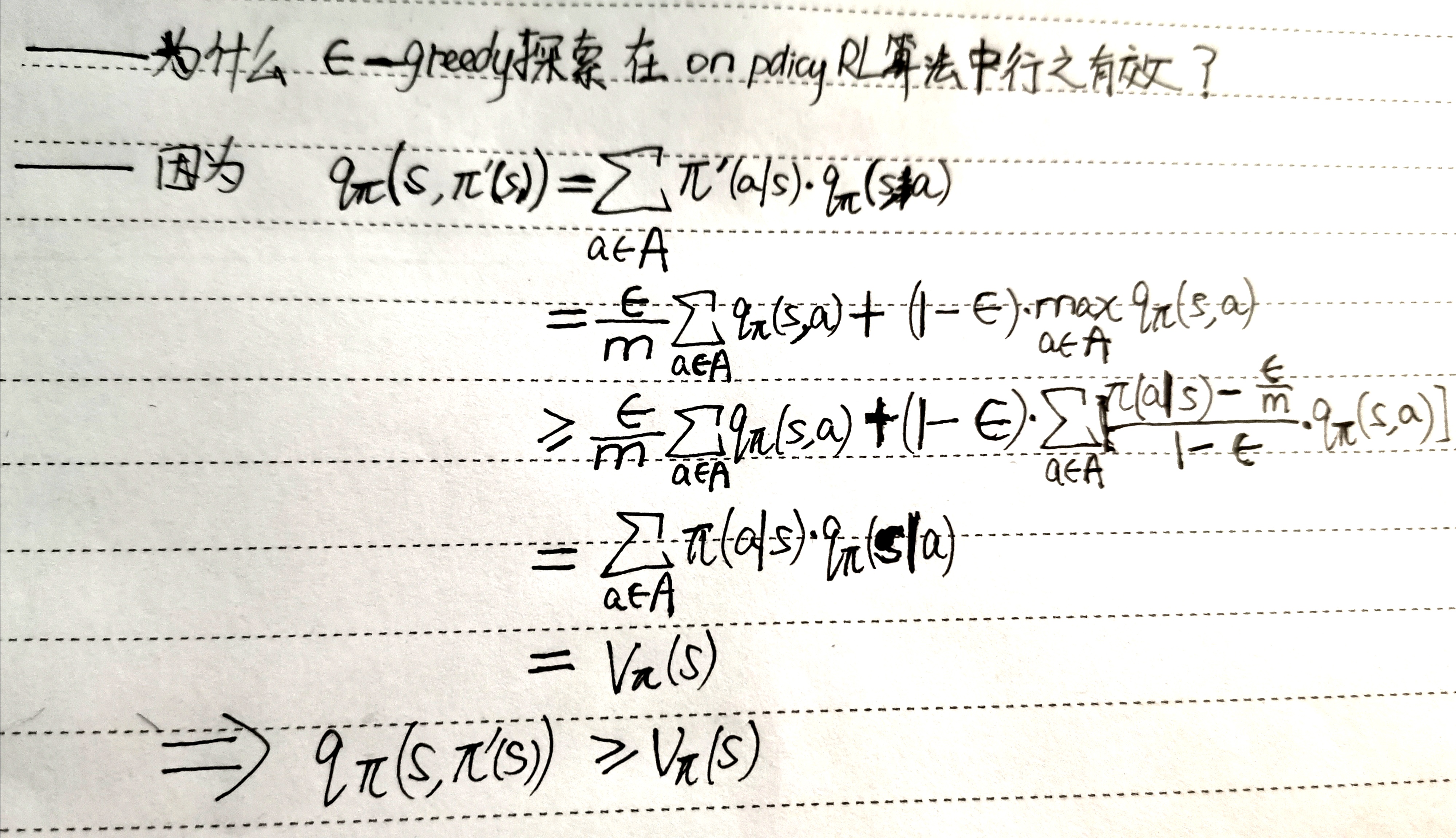

 浙公网安备 33010602011771号
浙公网安备 33010602011771号