数据采集第六次作业
作业①:
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
实践代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import re
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ol[class='grid_view'] li")
#print(lis)
for li in lis:
rank=li.find("em").text
name=li.find("div",attrs={"class":"hd"}).find("span").text
dirtor=li.find("div",attrs={"class":"bd"}).find("p").text
pfield=re.split('\n',dirtor)
first=pfield[1]
second=pfield[2]
diract_field=re.split(':',first)
dirtor=diract_field[1]
actor=diract_field[len(diract_field)-1].strip()
#print(actor)
director = re.sub(r'(主)(.*)', "", dirtor)
tcf_field=re.split('/',second)
time=tcf_field[0].strip()
country=tcf_field[1]
film_type=tcf_field[2]
score=li.find("div",attrs={"class":"star"}).find("span",attrs={"class":"rating_num"}).text
num=li.select("div[class='star'] span")[3].text
number=re.findall("[0-9]*",num)[0]
quote=li.find("p",attrs={"class":"quote"}).find("span").text
print(rank+' '+name+' '+director+' '+actor+' '+time+' '+country+' '+film_type+' '+score+' '+number+' '+quote)
images=soup.select("ol[class='grid_view'] img")
for image in images:
try:
src=image["src"]
alt=image["alt"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
#print(url)
count=count+1
T=threading.Thread(target=download,args=(url,count,alt))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count,alt):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
route=''+alt+ext
fobj=open("./images2/"+alt+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+alt+ext)
except Exception as err:
print(err)
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
count=0
threads=[]
for i in range(0, 251, 25):
start_url = "https://movie.douban.com/top250?start=" + str(i) + "&filter="
imageSpider(start_url)
for t in threads:
t.join()
print("The END")
实践结果:
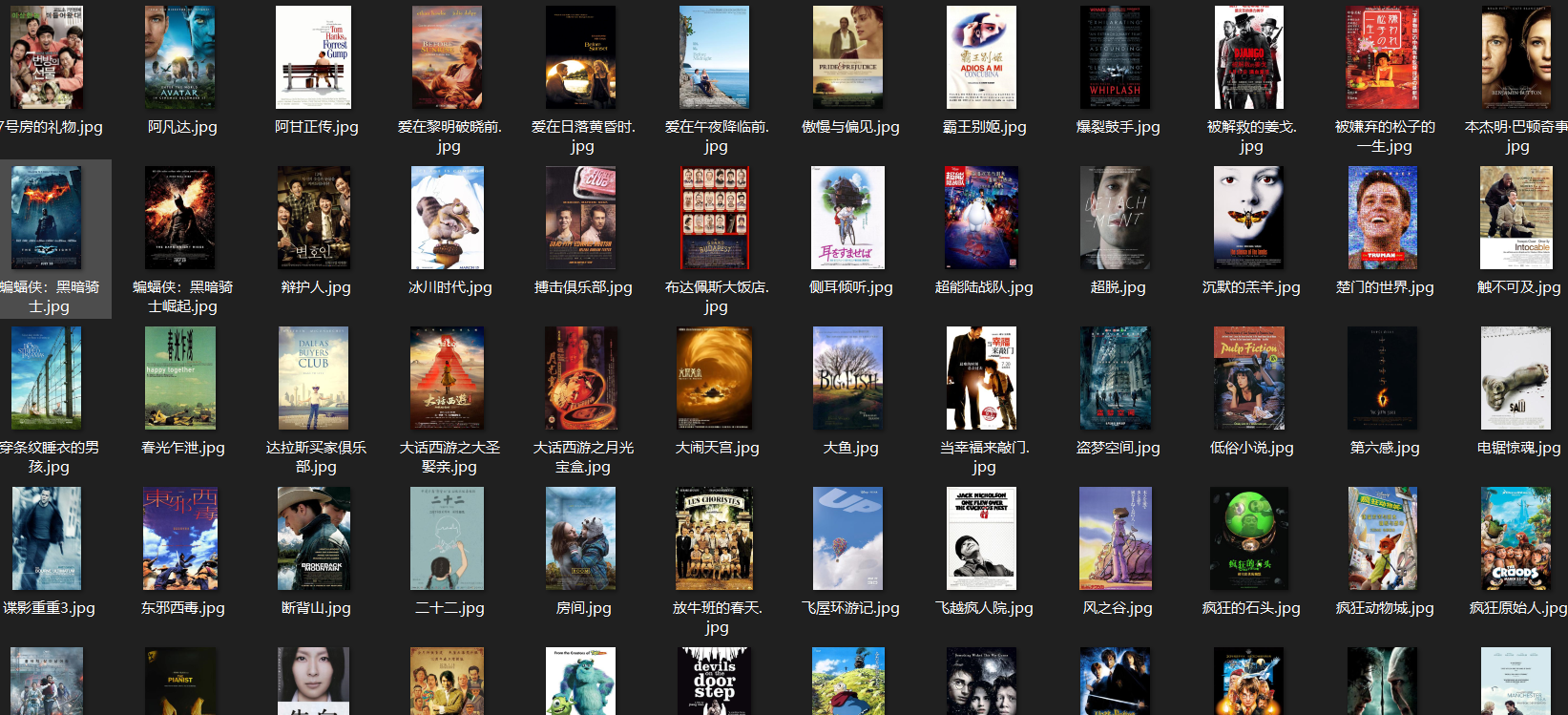
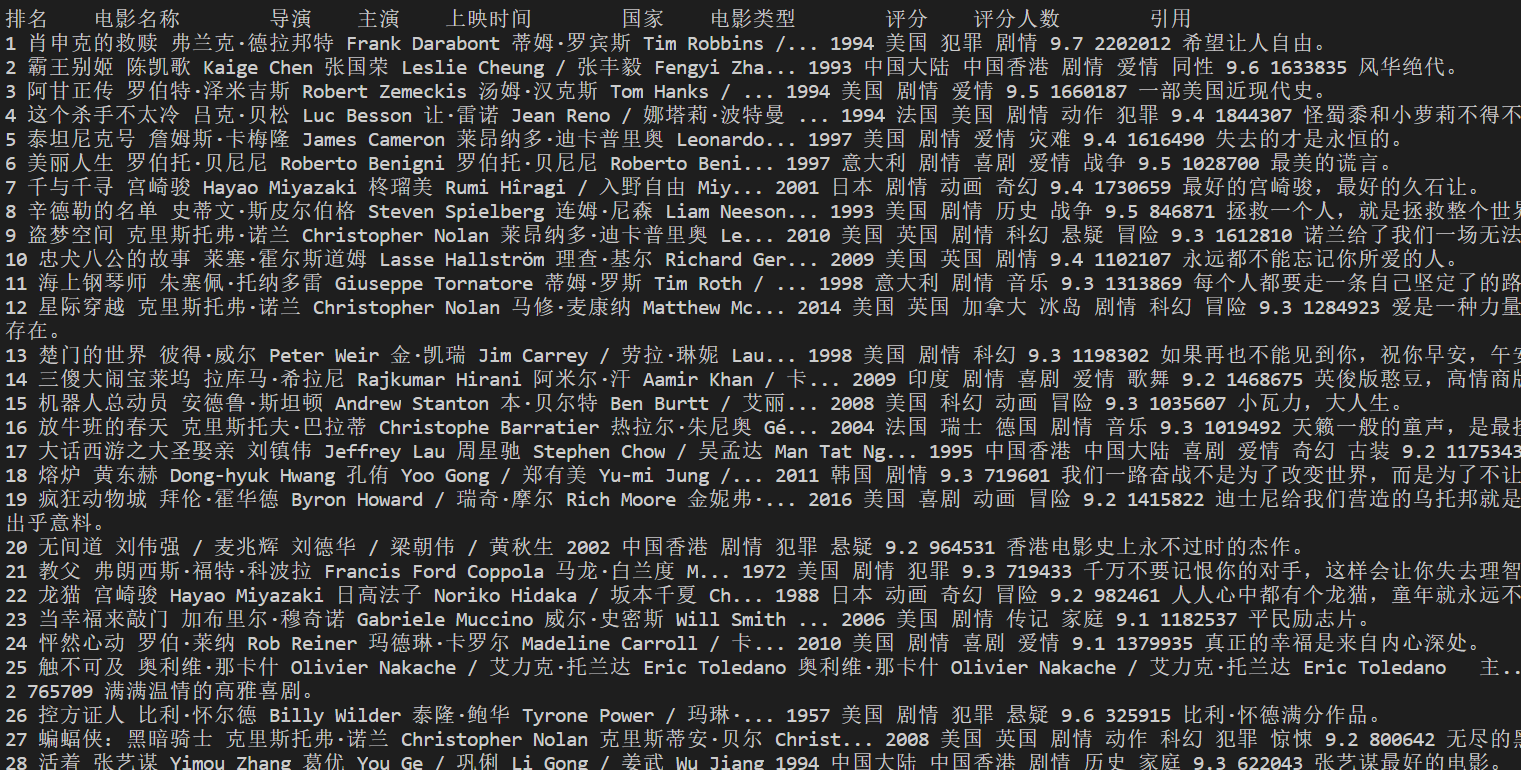
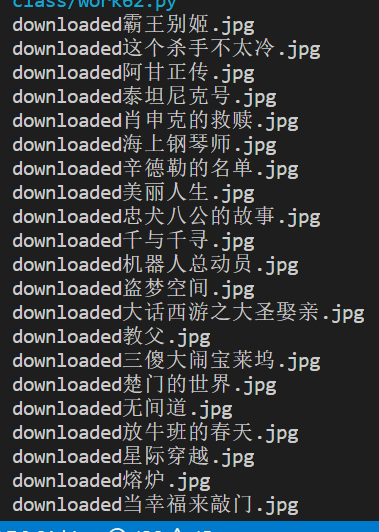
实践心得:
通过这一题对之前的一部分知识做了比较好的回顾,对requests、BeautifulSoup库方法爬虫更加了解,对单线程多线程做了一定的温习,在对正则表达式的温习中,不断匹配中,不断加深正则表达式的相关语法等细碎知识的记忆。多页爬取所需的相关内容也更加熟练,总之还是有一定收获的。
作业②:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
实践代码:
detailrank.py:
#此为scrapy爬取二级页面
#由于大学的具体介绍在下一个页面,我们需要重新定义一个方法,进入下一个页面爬取数据,同时parse方法需要将下一个页面的路径和数据传递给第二个方法
import scrapy
from ..items import RankdetailItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
class DetailrankSpider(scrapy.Spider):
name = 'detailrank'
start_urls = ['https://www.shanghairanking.cn/rankings/bcur/2020']
def parse(self, response):
startUrl='https://www.shanghairanking.cn'
dammit=UnicodeDammit(response.body,["utf-8","gbk"])
data=dammit.unicode_markup
selector=scrapy.Selector(text=data)
trs=selector.xpath("//table[@class='rk-table']/tbody/tr")
for tr in trs:
sNo=tr.xpath("./td[position()=1]/text()").extract_first()
schoolName=tr.xpath("./td[position()=2]/a/text()").extract_first()
city=tr.xpath("./td[position()=3]/text()").extract_first()
#二级页面路径
href=tr.xpath("./td[position()=2]/a/@href").extract_first()
src="https://www.shanghairanking.cn/"+href
item=RankdetailItem()
item["sNo"]=sNo.strip() if sNo else ""
item["schoolName"]=schoolName.strip() if schoolName else ""
item["city"]=city.strip() if city else ""
yield scrapy.Request(url=src,callback=self.parse_detail,meta={'item':item})
#scrapy.Request常用参数:url:下一个页面的路径,callback:指定该要求返回的Response,由那个函数来处理,meta:在不同的请求之间传递数据使用,字典dict型
def parse_detail(self, response):
item = response.meta['item']
#print(item["sNo"]+' '+item["schoolName"]+' '+item["city"])
item["info"] = response.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[6]/div[3]/div/p/text()').extract()[0]
item['image_url'] = response.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
image_url = response.xpath('//td[@class="univ-logo"]/img/@src').extract_first()
item["officalUrl"]=response.xpath("//div[@class='univ-website']/a/text()").extract_first()
suffix= item['image_url'].split('.')[-1]
try:
filename = item['sNo'] + '.' + suffix
except:
filename="-"
item['mFile']=filename
#print(item["sNo"]+' '+item["schoolName"]+' '+item["city"]+' '+item["officalUrl"]+' '+item["info"]+item['image_url']+' '+item[mFile])
yield item
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
import urllib.request
import os
class RankdetailPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from mooc")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
if self.opened:
self.download(item)
#print(item["sNo"]+' '+item["schoolName"]+' '+item["city"]+' '+item["officalUrl"]+' '+item["info"]+item['image_url']+item['mFile'])
self.cursor.execute("insert into mooc(sNo,schoolName,city,officalUrl,info,mFile)values(%s,%s,%s,%s,%s,%s)",(item["sNo"],item["schoolName"],item["city"],item["officalUrl"],item["info"],item['mFile']))
except Exception as err:
print(err)
return item
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
def download(self,item):
dirname='./moocpicture'
filepath = os.path.join(dirname, item['mFile'])
urllib.request.urlretrieve(item['image_url'], filepath)
print(item['mFile']+'下载完成')
items.py:
import scrapy
class RankdetailItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
sNo = scrapy.Field()
schoolName=scrapy.Field()
city=scrapy.Field()
officalUrl=scrapy.Field()
info=scrapy.Field()
image_url=scrapy.Field()
mFile=scrapy.Field()
pass
settings.py
ITEM_PIPELINES = {
'rankdetail.pipelines.RankdetailPipeline': 300,
}
实践结果:
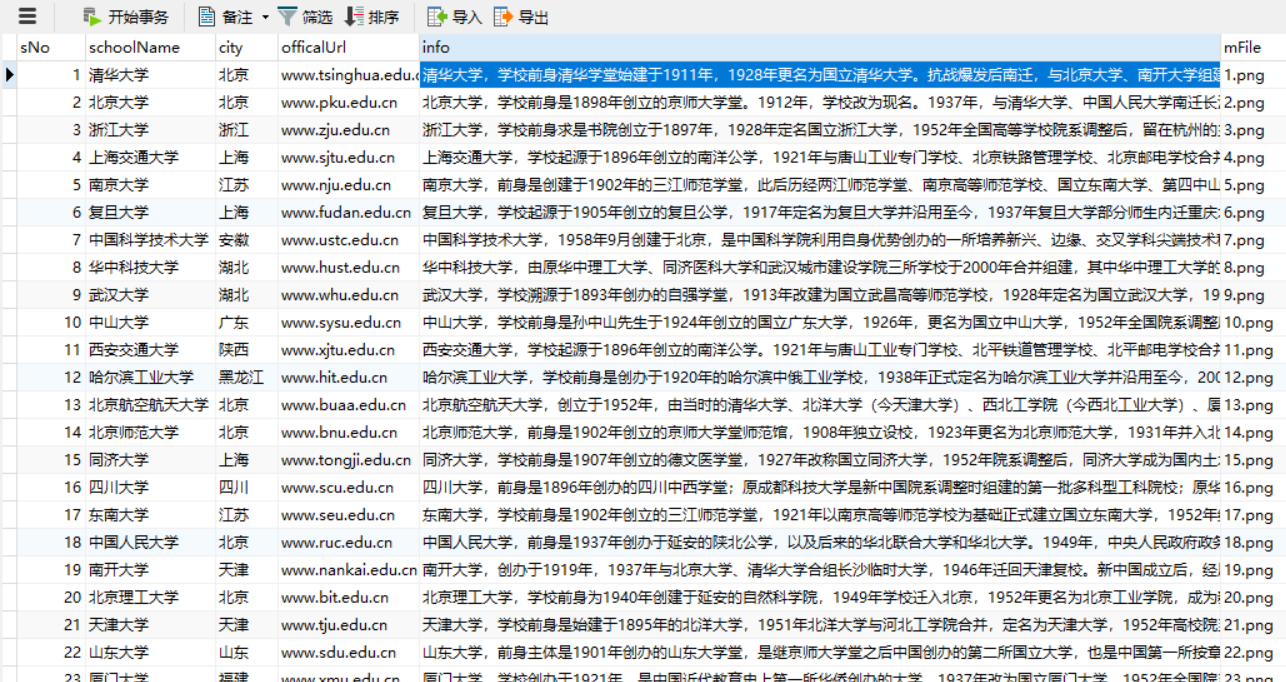
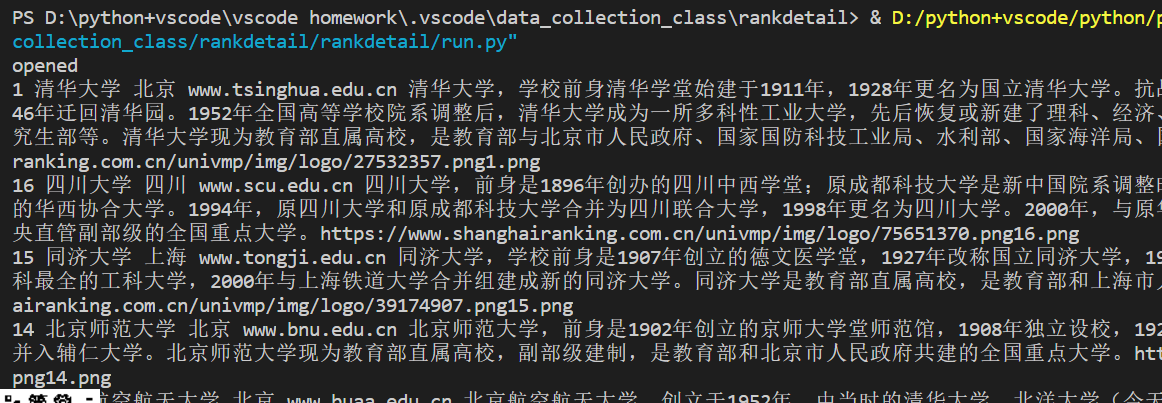

实践心得:
这一题对于我的主要意义就在于这是一个二级页面爬取的过程,之前还是很少遇到的。这一题不仅仅是页面的不断跳转,还有由于大学的具体介绍在下一个页面,我们需要重新定义一个方法,进入下一个页面爬取数据,同时parse方法需要将下一个页面的路径和数据传递给第二个方法,才能取得我们所需的信息。经过这一题,我对scrapy逻辑框架更加了解,多级页面爬取也是比较有意思的。
作业③:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
实践代码:
from selenium import webdriver
import time
import datetime
import pymysql
class MySpider:
def login(self,url):
try:
self.driver = webdriver.Chrome()
self.driver.get(url)
time.sleep(2)
self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click()
time.sleep(1)
self.driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']/span[@class='ux-login-set-scan-code_ft_back']").click()
time.sleep(1)
self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[2]").click()
time.sleep(6)
temp_iframe_id = self.driver.find_elements_by_tag_name('iframe')[1].get_attribute('id')
self.driver.switch_to_frame(temp_iframe_id)
user = self.driver.find_element_by_id("phoneipt")
user.send_keys("18649794133")
pwd = self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']")
pwd.send_keys("************")
self.driver.find_element_by_id("submitBtn").click()
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']/div/a/span[@class='nav']").click()
except Exception as err:
print(err)
def openUp(self):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from selenium_mooc")
#self.opened=True
#self.nnum=0
except Exception as err:
print(err)
#self.opened=False
def insertDB(self,num,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess, cBrief):
try:
self.cursor.execute("insert into selenium_mooc(Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess, cBrief)values(%s,%s,%s,%s,%s,%s,%s,%s)",(num,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess, cBrief))
except Exception as err:
print(err)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
divs = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']/div")
count=0
for div in divs:
try:
count +=1
try:
cCourse = div.find_element_by_xpath(".//div[@class='title']/div[@class='text']//span[@class='text']").text
cCollege=div.find_element_by_xpath(".//div[@class='school']/a").text
except:
cCourse = "-"
cCollege="-"
#print(cCourse,cCollege)
self.driver.execute_script("arguments[0].click();", div.find_element_by_xpath(".//div[@class='menu']/div/a"))
#ActionChains(self.driver).move_to_element(element_item).click().perform()
#time.sleep(2)
current_window = self.driver.window_handles[-1]
self.driver.switch_to.window(current_window)
time.sleep(2)
#print(self.driver.current_url)
try:
cTeacher=self.driver.find_element_by_xpath("//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']").text
cCount=self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
cTeam_divs=self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con']/div")
cTeam=''
for cTeamdiv in cTeam_divs:
cTeam1=cTeamdiv.find_element_by_xpath(".//h3").text
cTeam +=' '+cTeam1
print('cTeam'+cTeam)
cProcess=self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']/span[2]").text
cBrief=self.driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text
except:
cTeam="-"
cCount="-"
cProcess="-"
cBrief="-"
print(str(count)+' '+cCourse+' '+cCollege+' '+cTeacher+' '+cTeam+' '+cCount+' '+cProcess+' '+cBrief)
self.insertDB(str(count),cCourse,cCollege,cTeacher,cTeam,cCount,cProcess, cBrief)
self.driver.close()
backwindow = self.driver.window_handles[0]
time.sleep(2)
self.driver.switch_to.window(backwindow)
time.sleep(2)
if (count>2):
break
except:
pass
try:
nextpage = self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']")
time.sleep(3)
nextpage.click()
self.processSpider()
except:
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']")
except:
pass
def closeUp(self):
self.con.commit()
self.con.close()
#self.opened=False
self.driver.close()
print("closed")
def executeSpider(self,url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.login(url)
print("Spider login......")
self.openUp()
print("DB open......")
self.processSpider()
print("Spider completed......")
self.closeUp()
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org"
spider = MySpider()
spider.executeSpider(url)
实践结果:


实践心得:
对于这一题,上一次的作业还是铺垫了很多的,但这一题涉及到登录,主要的收获也是在这一方面。我们常常出现“Message: no such element: Unable to locate element”的错误,一般出现这个问题主要有三个原因,1、定位的方法或者属性写的有问题。2、延迟等待时间不够。3、有iframe。而这三个原因在这一题中都遇到了。其中iframe这一方面比较容易被忽视掉。iframe是HTML标签,作用是文档中的文档,或者浮动的框架(FRAME)。iframe元素会创建包含另外一个文档的内联框架(即行内框架), 作用就是嵌套网页。而我们在登陆时,定位的密码元素是在嵌套的iframe页面里,我们要操作这个元素,需要先切换到iframe页面,才能正常定定位,所以这里需要注意。
