数据采集第四次作业
作业①:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://www.dangdang.com/
实践代码:
bookSpiders.py:(本代码爬了10页)
import scrapy
from ..items import BooksItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class BookspiderSpider(scrapy.Spider):
name = 'bookSpider'
#key='python'
start_urls = ['http://search.dangdang.com/?key=python']
# def start_requests(self):
# url=BookspiderSpider.start_urls+"?key="+BookspiderSpider.key
# print(url)
# yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit=UnicodeDammit(response.body,["utf-8","gbk"])
data=dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis=selector.xpath("//ul[@class='bigimg']/li")
print(lis)
for li in lis:
title=li.xpath("./a[position()=1]/@title").extract_first()
price=li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author=li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date=li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher=li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail=li.xpath("./p[@class='detail']/text()").extract_first()
item=BooksItem()
item["title"]=title.strip() if title else ""
item["author"]=author.strip() if title else ""
item["date"]=date.strip()[1:] if date else ""
item["publisher"]=publisher.strip() if publisher else ""
item["price"]=price.strip() if price else ""
item["detail"]=detail.strip() if detail else ""
yield item
pagenum=10
for page in range(2,pagenum):
page='http://search.dangdang.com/?key=python&page_index{}'.format(page)
yield scrapy.Request(url=page,callback=self.parse)
# link=selector.xpath("//div[@class='paging']/ul[@name='Fy']/li/a[@class='null']/@href").extract_first()
# if link:
# url=response.urljoin(link)
# yield scrapy.Request(url=url,callback=self.parse)
except Exception as err:
print(err)
pass
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
class BooksPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="**********",db="mydb",charset="utf8")#链接数据库#密码不是真实密码,只是不想改密码了
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
self.num=1
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
n=str(self.num)
self.cursor.execute("insert into books(bNum,bTitle,bAuthor,bPublisher,bDate, bPrice,bDetail)values(%s,%s,%s,%s,%s,%s,%s)",(n,item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count+=1
self.num+=1
except Exception as err:
print(err)
return item
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
items.py:
import scrapy
class BooksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
author=scrapy.Field()
date=scrapy.Field()
publisher=scrapy.Field()
detail=scrapy.Field()
price=scrapy.Field()
pass
settings.py:
ITEM_PIPELINES = {
'books.pipelines.BooksPipeline': 300,
}
run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl bookSpider -s LOG_ENABLED=False".split())
实践结果:
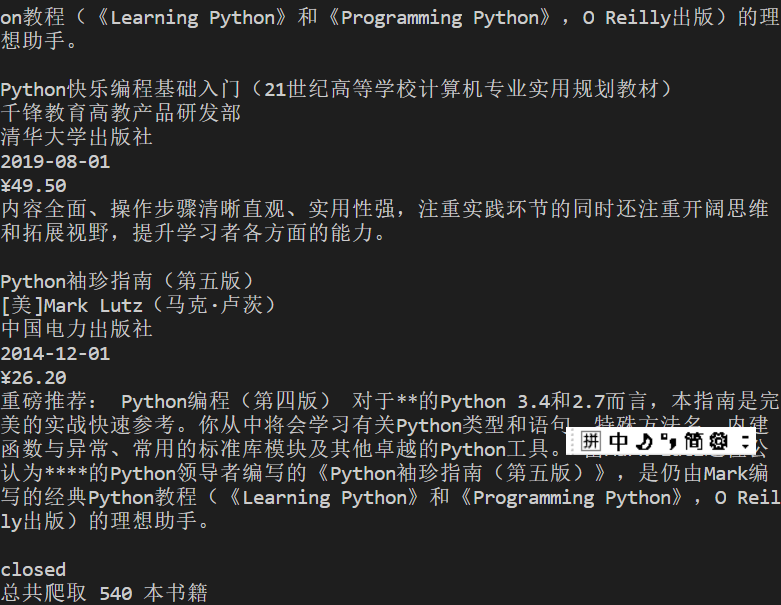
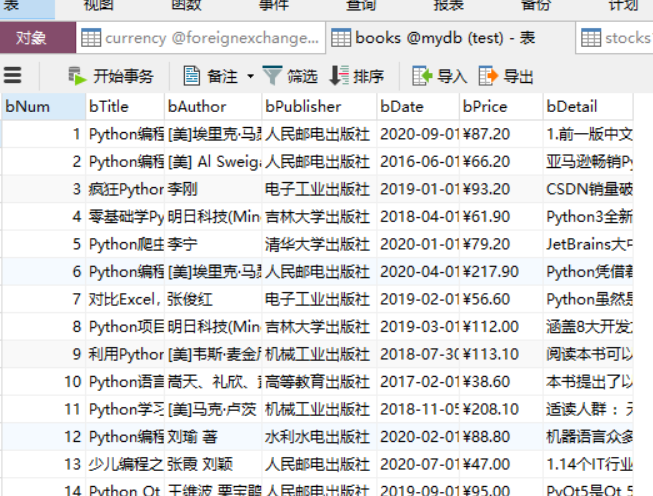
实践心得:
本次爬取当当网图书作业是书上实例的复现,刚开始源代码运行不出来还是爬不到数据来着,就改了部分代码。后面再来看源代码,爬出来了,貌似是url的问题,至今没搞清楚去了中括号为啥就行了。。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
##新浪股票:http://finance.sina.com.cn/stock/
实践代码:
Scrapy+MySQL,在之前代码的基础上把pipelines.py中改一改就行了,采用的是js抓包,然后提取数据
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
class StocksPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="**********",db="mydb",charset="utf8")#链接数据库#密码不是真实密码,只是不想改密码了
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks1")
self.opened=True
self.count=0
self.num=1
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
if self.opened:
n=str(self.num)
self.cursor.execute("insert into stocks1(序号,股票代码,股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(n,item["Code"] , item["name"] , item["Latest_price"],item["UD_range"] , item["UD_price"] ,item["Deal_num"] ,item["Deal_price"] ,item["Amplitude"], item["Up_est"] ,item["Down_est"], item["Today"] ,item["Yesterday"]))
self.count+=1
self.num+=1
except Exception as err:
print(err)
return item
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
由于我们这是爬取动态网页,为了要使用到xpath,采取scrapy+selenium+xpath+Mysql。
注意得清空表格stocks1:
stocksdemo.py:
import scrapy
from ..items import SeleniumstockItem
import datetime
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
class StocksdemoSpider(scrapy.Spider):
name = 'stocksdemo'
def start_requests(self):
url = 'http://quote.eastmoney.com/center/gridlist.html'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
browser = webdriver.Chrome()
print("正在打开网页...")
browser.get("http://quote.eastmoney.com/center/gridlist.html")
print("等待网页响应...")
# 需要等一下,直到页面加载完成
#wait = WebDriverWait(browser, 10)
#wait.until(EC.presence_of_element_located((By.CLASS_NAME, "grid")))
browser.implicitly_wait(10)
print("正在获取网页数据...")
trs=browser.find_elements_by_xpath("//table[@class='table_wrapper-table']/tbody/tr")
for tr in trs:
td=tr.find_elements_by_xpath("./td")
item=SeleniumstockItem()
item["Snumber"]=td[0].text
item["Code"]=td[1].text
item["Name"]=td[2].text
item["Latest_price"]=td[4].text
item["UD_range"]=td[5].text
item["UD_price"]=td[6].text
item["Deal_num"]=td[7].text
item["Deal_price"]=td[8].text
item["Amplitude"]=td[9].text
item["Up_est"]=td[10].text
item["Down_est"]=td[11].text
item["Today"]=td[12].text
item["Yesterday"]=td[13].text
#print(item["Snumber"]+" "+item["Code"] + ' ' + item["Name"] + ' ' + item["Latest_price"] + ' ' + item["UD_range"] + ' ' + item["UD_price"] + ' ' + item["Deal_num"] + ' ' + item["Deal_price"] + ' ' +item["Amplitude"] + ' ' + item["Up_est"] + ' ' + item["Down_est"] + ' ' + item["Today"] + ' ' + item["Yesterday"])
yield item
browser.close()
pass
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
class SeleniumstockPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="********",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks1")
self.opened=True
self.count=0
self.num=1
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
if self.opened:
n=str(self.num)
self.cursor.execute("insert into stocks1(序号,股票代码,股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["Snumber"],item["Code"] , item["Name"] , item["Latest_price"],item["UD_range"] , item["UD_price"] ,item["Deal_num"] ,item["Deal_price"] ,item["Amplitude"], item["Up_est"] ,item["Down_est"], item["Today"] ,item["Yesterday"]))
self.count+=1
self.num+=1
except Exception as err:
print(err)
return item
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl stocksdemo -s LOG_ENABLED=False".split())
setting.py、items.py同之前一样
实践结果:
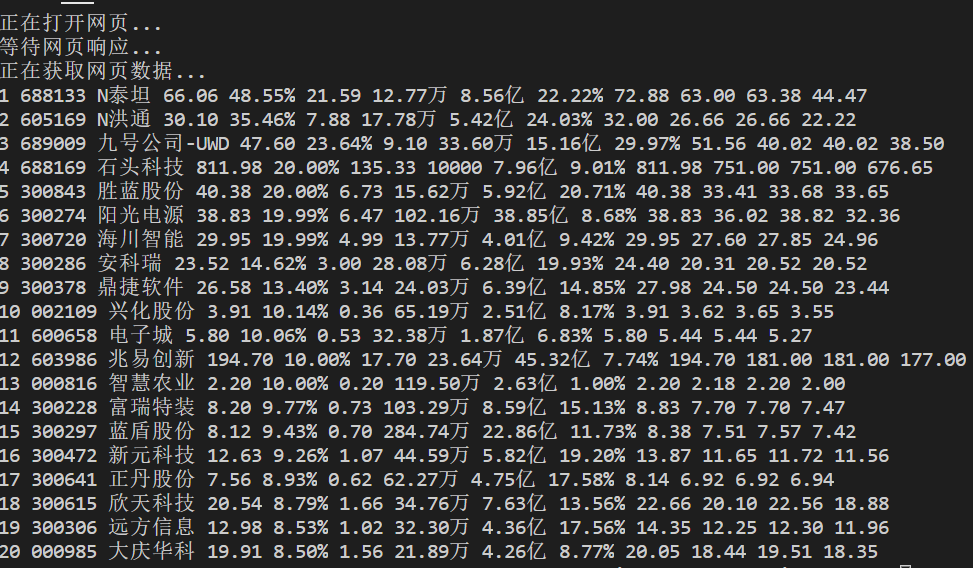
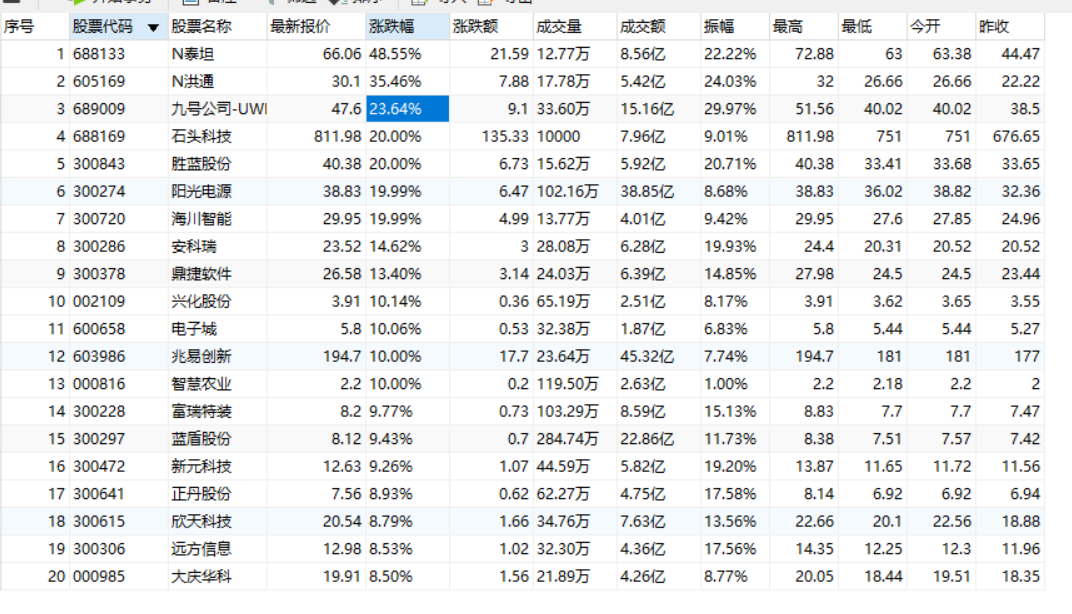
实践心得:
通过实践,对selenium框架有了更加深入的理解。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
输出信息:MYSQL数据库存储和输出格式
实践代码:
Exchange.py:
import scrapy
from ..items import CurrencyItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class ExchangeSpider(scrapy.Spider):
name = 'Exchange'
start_urls = ['http://fx.cmbchina.com/hq/']
def parse(self, response):
try:
dammit=UnicodeDammit(response.body,["utf-8","gbk"])
data=dammit.unicode_markup
selector=scrapy.Selector(text=data)
trs=selector.xpath("//div[@id='realRateInfo']/table[@class='data']//tr")
num=0
for tr in trs:
if (num==0):
num=num+1
continue
Currency=tr.xpath("./td[@class='fontbold']/text()").extract_first()
TSP=tr.xpath("./td[position()=4]/text()").extract_first()
CSP=tr.xpath("./td[position()=5]/text()").extract_first()
TBP=tr.xpath("./td[position()=6]/text()").extract_first()
CBP=tr.xpath("./td[position()=7]/text()").extract_first()
Time=tr.xpath("./td[position()=8]/text()").extract_first()
item=CurrencyItem()
item["Currency"]=Currency.strip() if Currency else ""
item["TSP"]=TSP.strip() if TSP else ""
item["CSP"]=CSP.strip()[1:] if CSP else ""
item["TBP"]=TBP.strip() if TBP else ""
item["CBP"]=CBP.strip() if CBP else ""
item["Time"]=Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
pass
pipelines.py:
from itemadapter import ItemAdapter
import pymysql
class CurrencyPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="**********",db="foreignExchange",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from currency")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def process_item(self, item, spider):
try:
if self.opened:
self.count+=1
n=str(self.count)
print(n+" "+item["Currency"]+" "+item["TSP"]+" "+item["CSP"]+" "+item["TBP"]+" "+item["CBP"]+" "+item["Time"])
self.cursor.execute("insert into currency(bNum,bCurrency,bTSP,bCSP, bTBP,bCBP,bTime)values(%s,%s,%s,%s,%s,%s,%s)",(n,item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
except Exception as err:
print(err)
return item
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
items.py:
import scrapy
class CurrencyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
Time=scrapy.Field()
pass
settings.py:
ITEM_PIPELINES = {
'currency.pipelines.CurrencyPipeline': 300,
}
run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl Exchange -s LOG_ENABLED=False".split())
实践结果:

实践心得:
此题为爬取静态网页,理解了第一个实例,本题就没什么可说的了。

