


什么是连接
连接就是把一个或多个来自不同表的元组通过相同的属性字段合并成一个大的元组

如上图,把属性 ID 相同的两个元组(来自不同表)合并成一个大的元组
连接属性是否有 索引(快速定位),是否 有序(是否要全表扫描),还有 内存访问 和 磁盘访问 的速度都会影响连接操作的成本
theta 连接
theta 连接 是一种通用的连接类型,它允许在两个表之间使用 任何比较运算符(如 <、>、<=、>=、!= 等)进行连接
- 连接的表之间做 笛卡尔积
- 进行条件 筛选
等值连接 --- Equi-Join
一种特殊的 theta 连接,通过比较两个表中某一列的值是否相等来进行连接的操作。也就是,基于相等条件的连接
这就是一个 等值连接 的例子,基于 字段ID 进行连接

自然连接
一种特殊的等值连接,它自动匹配两个表中名称相同的列,并将这些列进行等值连接。自然连接会自动使用所有同名列,并且不会在结果中重复同名的列
不需要显式地指定连接条件,系统会根据列名自动匹配
嵌套循环连接 --- Nested-loop join (NLJ)

用双重循环,逐条记录对比,将符合的记录添加到最后的结果,无需索引,但价格昂贵
假设一次加载1个 block 到内存中,那么外部循环每一个块要和内部循环的所有块比较

成本计算:Nr 是 outer relation 的 记录 的数量,Br 表示 outer relation 的 块 的数量,Bs 表示 inner relation 的 块 的数量
-
最坏情况:内存只能容纳每个关系的一个block
-
传输次数:outer relation 需要 Br 次,inner relation 每轮需要 Bs 次,共有 Nr 轮,所以要 Nr*Bs+Br 次
-
寻道次数:outer relation 每个块有 Nr/Br 条记录,inner relation 每次定位只需定位到开头就可以扫描全部记录,所以 outer relation 的一个块的比较,需要寻道 1+Nr/Br,有 Br 个块,所以需要 Br+Nr

-
-
最好情况:内存能够容纳 inner relation 的所有块
-
传输次数:inner relation 需要 Bs 次传输,因为内存足够大,可以容纳 inner relation 所有块,所以一次把他加载完后,只需要加载 outer relation 的块即可,需要 Br 次传输,不需要再两者之间切换,所以总共需要 Br+Bs
-
寻道次数:outer relation 和 inner relation 都只需要定位到开头就可以了,顺序扫描即可,所以总共需要 2 次寻道

-
outer relation 比 inner relation 大(记录更多,块也更多),块传输次数多,但寻道次数少,反之,则相反
块嵌套循环连接 --- Block nested-loop join (BNLJ)
嵌套连接的变体,inner relation 的每个块和 outer relation 的每个块配对

当内存中加载了 outer relation 和 inner relation 的各一个块后,只有当 outer relation 在内存中的块的所有记录和 inner relation 在内存中的块的所有记录比对完后,才会加载下一个 inner relation 的块
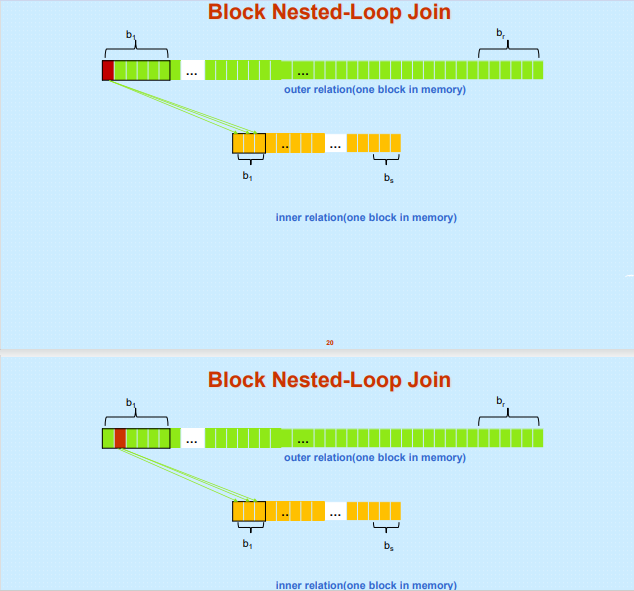
成本估算:
-
最坏情况:内存只能容纳每个关系的一个block
-
传输次数:outer relation 需要 Br 次,对于每一个 outer relation 的块,inner relation 需要传输所有块,也就是 Bs 次,所以总共需要 Br*Bs+Br 次
-
寻道次数:outer relation 需要 Br 次,每一个 outer relation 的块,需要传输 inner relation 的所有快,所以只需定位到开头,顺序扫描即可,所以总共需要 2Br 次

-
-
最好情况:内存能够容纳 inner relation 的所有块
-
传输次数:先把 inner relation 的所有快装入内存,需要 Bs 次,outer relation 每次传输1块,需要 Br 次,总共需要 Br+Bs 次
-
寻道次数:两者都只需要定位到开头,顺序扫描即可,总共需要 2 次

-
索引嵌套循环连接 --- Indexed nested-loop join (INLJ)
适用场景:
-
连接类型:该优化适用于 等值连接(Equi-Join) 或 自然连接(Natural Join)。这两种连接类型的特点是,它们连接的条件是基于某个属性的值是否相等
-
索引存在:在 inner relation 的连接属性上有 索引。索引可以帮助快速定位满足连接条件的元组,而不必遍历整个表
如何工作:
-
构造索引:为了计算连接,可以专门为连接条件构造一个索引,即使原本没有为查询创建索引
-
使用索引查找:对于 outer relation 中的每一个元组 t_r,通过使用 索引 来查找 inner relation 中满足连接条件的元组
成本估算
-
内存限制:假设缓冲区(buffer)的空间只足够容纳 r 中一个页面的数据。通常情况下,数据库的缓冲区有限,不能一次性加载整个关系的数据,只能一次性处理某个关系的一部分。
-
索引查找的开销:在最坏情况下,对 r 中的每个元组,都需要执行一次对 s 的索引查找。如果 r 中的元组数非常多,并且每次查找都需要使用索引,那么这种方法可能并不比完全扫描 s 更高效

outer relation 需要 Br*(Tr+Ts) 的时间(Tr是传输时间,Ts是寻道时间),inner relation 需要为每一个 outer relation 的元组进行匹配,每次匹配包括 索引查找开销和记录传输开销,记为 C,所以需要 Nr*C, 总共需要 Br*(Tr+Ts)+Nr*C
优点和局限:
-
优点:这种方法的好处是,通过索引查找可以 避免对 inner realtion 进行全表扫描,而是可以更快速地定位符合条件的元组,从而提高效率,特别是在内关系非常大的情况下
-
局限:如果缓冲区空间有限,或者 r 中有很多元组,那么 对于每个元组进行索引查找的开销会非常大,可能会导致性能下降。在这种情况下,完全扫描内关系(即执行文件扫描)可能会更高效
归并连接 --- Merge join (MJ)
使用场景
只能用于 等值连接 和 自然连接,因为在 合并 过程中,是基于 连接属性的值 进行匹配的
步骤
排序操作:
-
排序:首先需要对两个关系(表)按照 连接属性进行排序。如果两个关系已经根据连接属性排好序,那么就不需要再排序
-
排序的必要性:合并连接算法依赖于两个关系已经按照连接属性的值排好序。排序是为了便于后续的“合并”操作
合并操作:
- 合并:排序后的两个关系将 根据连接属性的值逐对比较。如果两个关系在相同的连接属性值上有匹配的元组,则将这些元组合并成一个连接结果
具体的匹配过程可以参考这篇博客,关键点在于 表指针 的移动
https://blog.csdn.net/qq_29611575/article/details/103587798
哈希连接 --- Hash join (HJ)
简单情况
-
建立阶段
选择 较小的表 建立哈希表(可以减少建立哈希表的时间和空间),对每个元组的连接属性使用 哈希函数 获得哈希值,该元组落入该哈希值对应的 桶
-
探测阶段
对另外一个表,扫描它的每一个元组,并计算它的连接属性的哈希值,然后落入对应的桶中,与桶内的元组进行比较,符合条件的加入合并到最终结果中
Grace hash-join

分为三步
-
分区:
将两个输入关系(表)按照 同一哈希函数 分成多个分区,每个分区的数据量小于内存的大小。这一步主要是为了 确保每个分区的大小适合内存处理。
具体做法是使用一个哈希函数对每个输入的元组进行哈希分区,分配到不同的磁盘文件(每个分区存储在磁盘上的一个文件中)
-
建立哈希表
将两个表相同的(哈希值)分区加载进内存,并对小的那个分区建立哈希表(又一个哈希函数)
-
探索
使用对小分区建立哈希表的哈希函数,进行匹配(就和简单情况是一样的)
这种方法避免了将表全部加载进内存,适合内存容量小的场景,但它需要在磁盘和内存直接交互,增加了IO开销
Hybrid hash-join

-
构建阶段
选择较小的关系(表)作为哈希构建表。选择一个合适的哈希函数分区,每个分区尽量适合内存大小处理,如果内存不够,将不够装入内存的分区写回磁盘,尽可能保证第一个分区在内存中,充分利用内存
-
探测阶段:
对于另一个较大的表,同样根据连接键进行哈希划分,但这次使用的是与 构建阶段相同的哈希函数。对于每个划分后的桶,将其内容和对应的构建表桶进行匹配
如果一个桶的大小适合内存,直接 在内存中完成连接操作(即哈希连接)
如果一个桶的大小超过了内存容量,则该桶被处理为 类似于 Grace Hash-Join 的分区处理方式,分区后的部分数据会被写入磁盘
混合哈希连接 在开始时 尽量利用内存,避免过早地将数据写入磁盘。只有在某些分区数据太大而无法全部加载到内存时,才会将数据写入磁盘并进行二次哈希分区,减少了磁盘IO开销
但复杂度更高,哈希函数和分区策略的选择也更关键


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现