

什么是回归
回归分析是一种 基于已有数据建立模型的方法,旨在帮助我们进行未来的预测。通过回归分析,我们可以探索因变量(目标变量)与一个或多个自变量(特征变量)之间的关系。
损失函数
在回归分析中,我们通常需要衡量模型的预测效果,这就涉及到损失函数。常见的损失函数包括 绝对值损失和最小二乘损失。损失越小,说明模型的预测效果越好。

绝对损失
绝对损失又称为L1损失或绝对误差损失(Absolute Error Loss),用于衡量 预测值与真实值之间的绝对差异。它对每个数据点的误差进行线性惩罚。
最小二乘损失
最小二乘损失又称为L2损失或平方误差损失(Squared Error Loss),用于衡量 预测值与真实值之间的平方差。它对每个数据点的误差进行平方惩罚,强调了较大的误差。
差异
- 对异常值的敏感性
- 绝对损失:对异常值的敏感性较低,能更好地处理离群点。
- 最小二乘损失:对异常值非常敏感,平方会放大较大误差的影响。
- 优化特性
- 绝对损失:在0点处导数不存在(因为是绝对值),优化时可能不稳定,需使用次梯度方法(非光滑优化)。
- 最小二乘损失:在所有点处具有导数,优化过程平滑且易于计算。
- 应用场景
- 绝对损失:适合数据中存在异常值的情况,如金融领域的回归分析。
- 最小二乘损失:常用于数据相对干净、需要高精度预测的回归任务。
线性回归
线性回归是最基础的回归方法之一,它描述了因变量与自变量之间的线性关系。线性回归的目标是通过找到最优的 线性模型 来拟合数据。

线性回归的损失函数
线性回归的损失函数通常采用最小二乘法,目标是最小化预测值与真实值之间的差异。
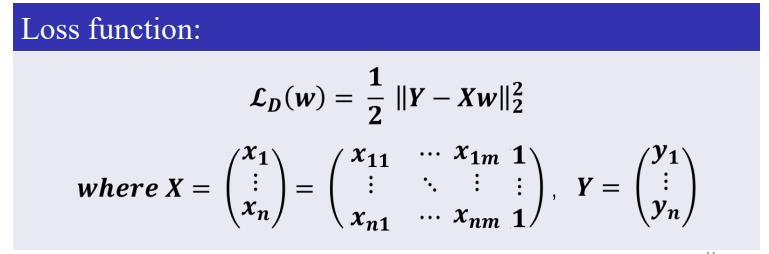
简单介绍下上面数学符号---范数

闭式解求权重 (w)
在线性回归中,我们可以通过闭式解求得权重 (w),从而实现模型的训练。

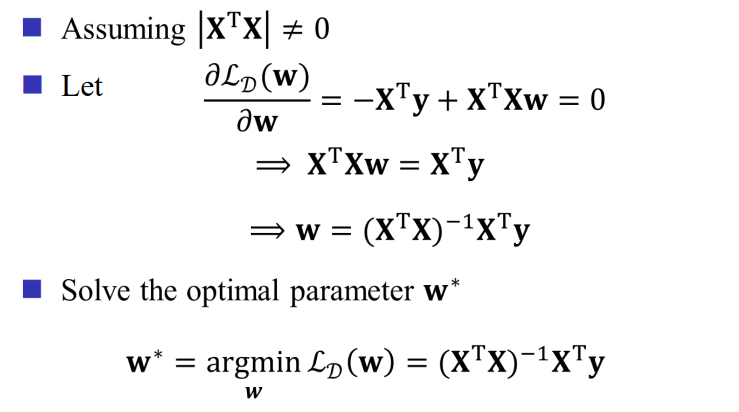
需要注意的是,有些矩阵是不可逆的,通常可以通过加一个偏置的单位矩阵来确保其可逆性。
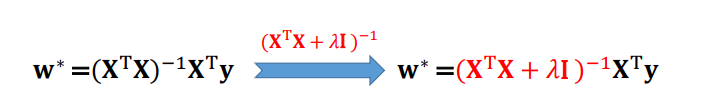
正则化最小二乘
正则化是为了防止模型过拟合的一种技术,通过对损失函数添加正则项,来限制模型复杂度。
什么是梯度
梯度是指向上升的方向,表示在某一点上函数值增加最快的方向。梯度是函数的偏导数向量,描述了在每个参数方向上的变化率。
- 上升方向:如果沿着梯度的方向移动,函数值将增加,损失函数可能变得更大。
- 下降方向:如果沿着梯度的反方向(即负梯度方向)移动,函数值将减少,损失函数也会变小。这就是梯度下降法中使用负梯度的原因。
梯度下降
梯度下降是一种用于最小化损失函数的方法,它通过迭代调整模型参数来逐步逼近最优解。
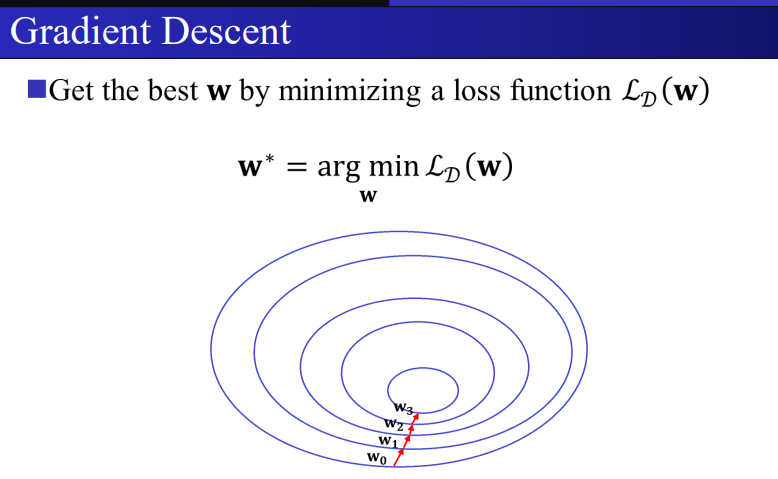
一般优化算法主要涉及方向和步长。

在梯度下降算法中,通常的步骤如下:
- 计算损失函数。
- 计算梯度。
- 使用负梯度作为下降方向,选择一个学习率来更新权重 (w)。


收敛性
在机器学习的梯度下降中,收敛指的是通过迭代过程,参数逐渐接近最优值,损失函数的值趋向于最小值。
学习率对收敛性有很大影响:如果学习率过小,收敛速度会变慢,需要更多的训练轮数;如果学习率过大,可能导致参数在最优值附近来回摆荡,从而无法收敛。

总结
要获得最佳的参数,即最好的模型,预测更准,有以下几种方法,对于线性回归
- 闭式解求权重w
- 一般优化算法
- 梯度下降优化算法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律