记一次后端性能测试与调试
先说结论:项目遇到的主要瓶颈在CPU和uwsgi的listen参数。下面以时间顺序记录排查过程。
背景
导师安排的一个项目,由于需要使用一些百度智能云的服务,服务器我选的百度BCC,预设的部署方案是两台4核4G应用服务器(uwsgi+falsk)、三台2核8G的数据服务器(Redis+MongoDB,3台保证可用)、一台2核2G的配置和部署服务器。但实际开发时为节省成本,暂时将MongoDB、redis、nginx、uwsgi以及后端代码部署于同一台2核8G服务器。
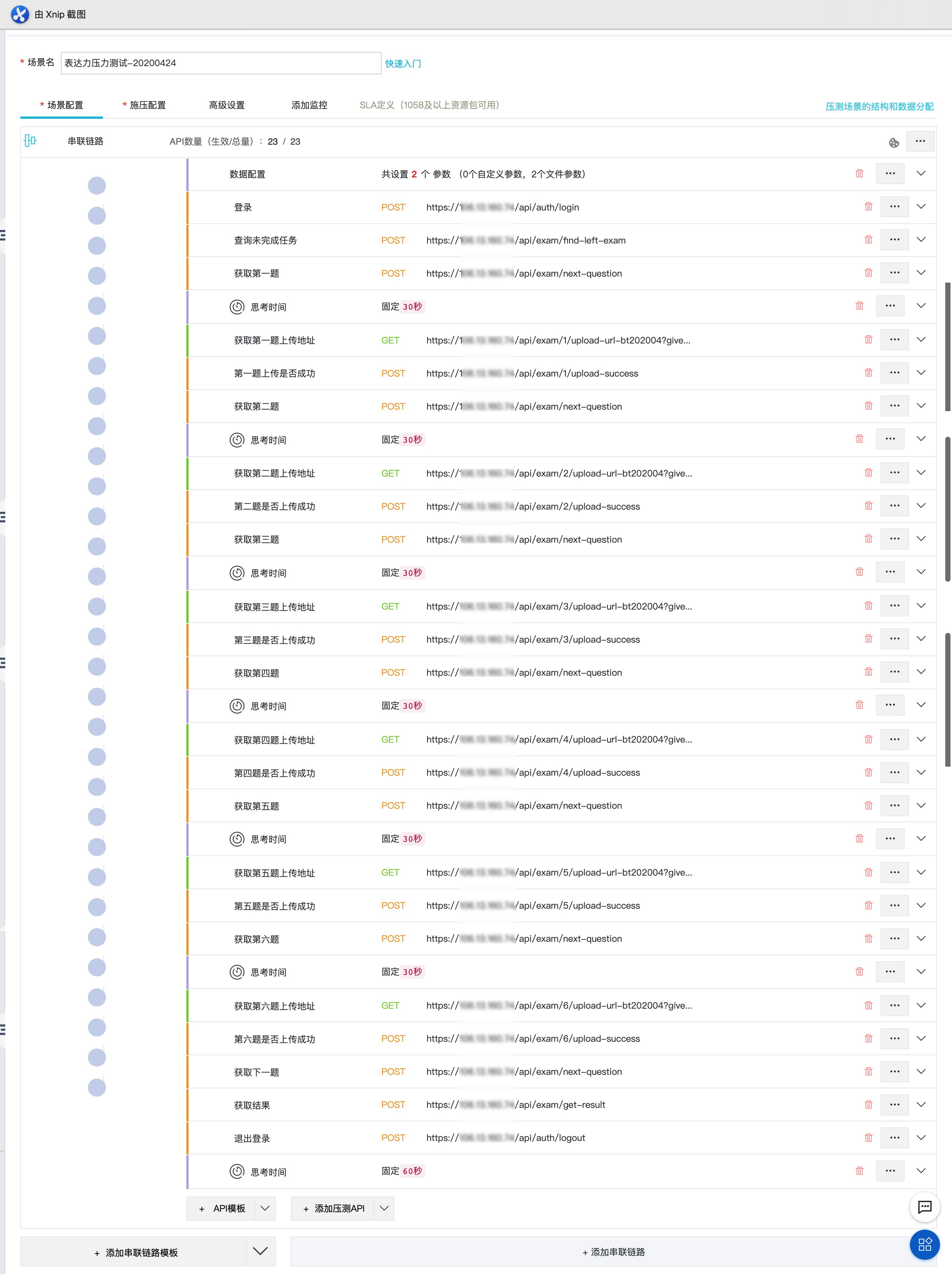
使用阿里云PTS以500并发施压时发现有较大性能瓶颈,大量请求超过设置的5s时限。每个线程依次请求的接口和顺序如下(原始接口较丑陋,功能不太合理且不符合REST风格,新版REST接口平滑替换中):
uwsgi 初始配置文件
应用服务器中uWSGI部分配置如下:
[uwsgi]
strict = true
single-interpreter = true
die-on-term = true
need-app = true
socket=0.0.0.0:5001
pidfile=/tmp/uwsgi-exp-flask.pid
vacuum=true
# python 虚拟环境目录:
home=/root/.local/share/virtualenvs/expression-flask-p9tMTecW
pythonpath=/var/www/expression-flask
# web 应用python主程序:
wsgi-file=run_app.py
# callable=app 这个 app 是 manage.py 程序文件内的一个变量,这个变量的类型是 Flask的 application 类
callable=app
uid=root
gid=root
chdir=/var/www/expression-flask
max-fd=65535
# socket监听队列大小,默认100
listen=100
# 2进程,每个进程1线程
processes=2
# threads=1
# apscheduler requires enable-threads, if no worker threads are used
enable-threads=true
master=true
# 无master时自动结束worker
no-orphans=true
# 设置master进程名称
procname-master=uWSGI master (%p)
# 平滑重启最长等待时间(秒)
reload-mercy=6
此外/etc/sysctl.conf部分配置如下:
net.ipv4.tcp_keepalive_time=1800
net.ipv4.tcp_keepalive_probes=3
net.ipv4.tcp_keepalive_intvl=15
net.ipv4.tcp_max_tw_buckets=25000
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_fin_timeout=10
net.ipv4.tcp_syncookies=0
net.core.somaxconn=65535
过程1 - 调整uwsgi listen参数
发现性能问题后,首先需要定位慢在什么地方。
调整Nginx日志,记录时间:
# Nginx配置(部分)
user www-data;
worker_processes auto;
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
worker_rlimit_nofile 65535;
events {
worker_connections 32768;
# multi_accept on;
}
http {
# ......
##
# Logging Settings
##
log_format timed_combined '$remote_addr - $remote_user [$time_local] [REQ:$request_time] [RESP:$upstream_response_time] [CONN:$upstream_connect_time] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" [$upstream_addr $upstream_status]';
access_log /var/log/nginx/access.log timed_combined;
error_log /var/log/nginx/error.log;
# ......
}
这样可以看到如下这种时间记录:
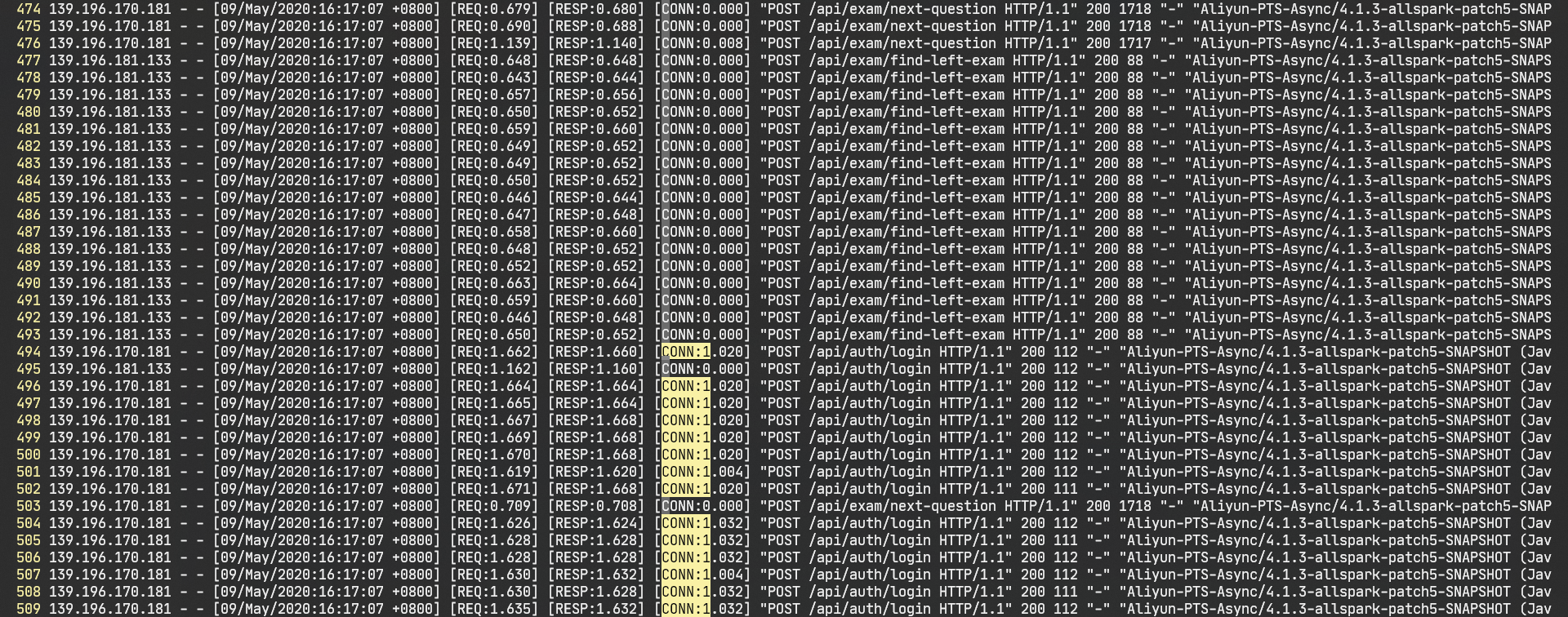
CONN(upstream_connect_time)是Nginx连接uwsgi花费的时间。这个图是后来截取的,最初REQ超5秒,CONN超2秒。CONN过大是uwsgi的listen参数过小造成的。listen队列大小默认是100,满了之后就会拒绝请求,这时候任务会被堆积在Nginx端,记录的CONN就比较大。
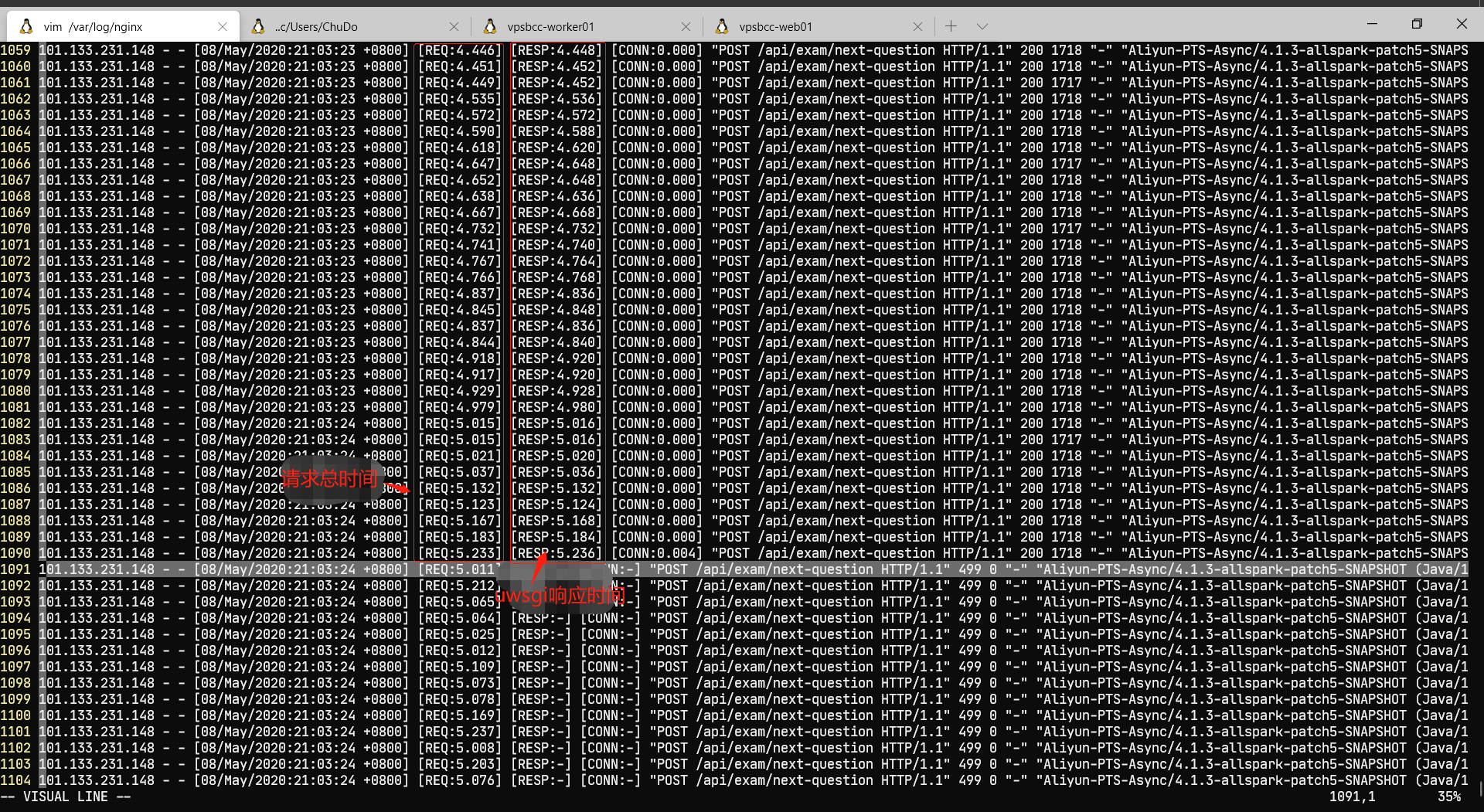
通过把listen参数大小改成65535(不可超过net.core.somaxconn,否则uwsgi拒绝启动),可以让uwsgi接受更多请求放入backlog,所以降低了upstream_connect_time:
过程2 - 确认是uwsgi的锅
上面通过调整listen让uwsgi一股脑地接受所有请求,并不能让整体速度提高(请求失败的都是499错误):
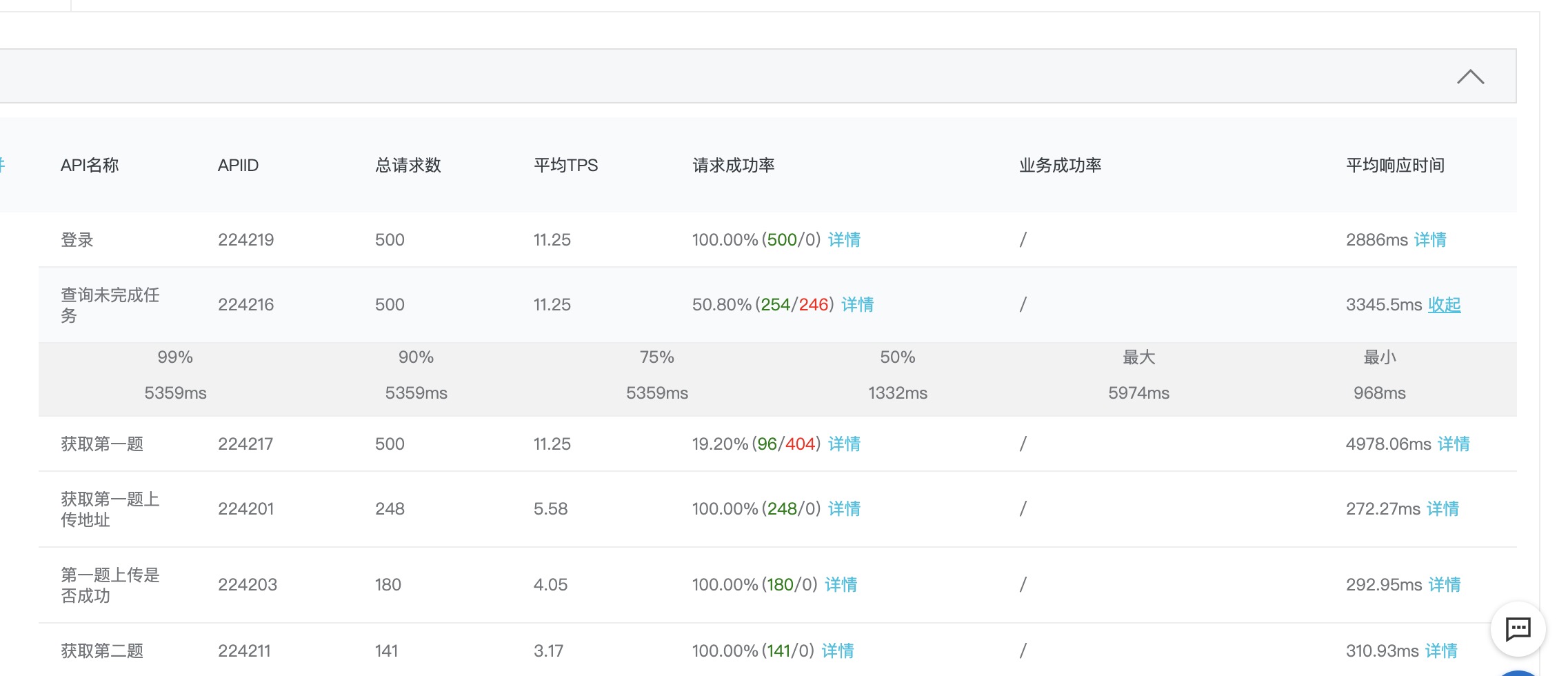
所以,还需要确认一下uwsgi和flask代码到底是谁慢。
查看uwsgi的日志可看出耗时最长的请求执行了不到1秒:
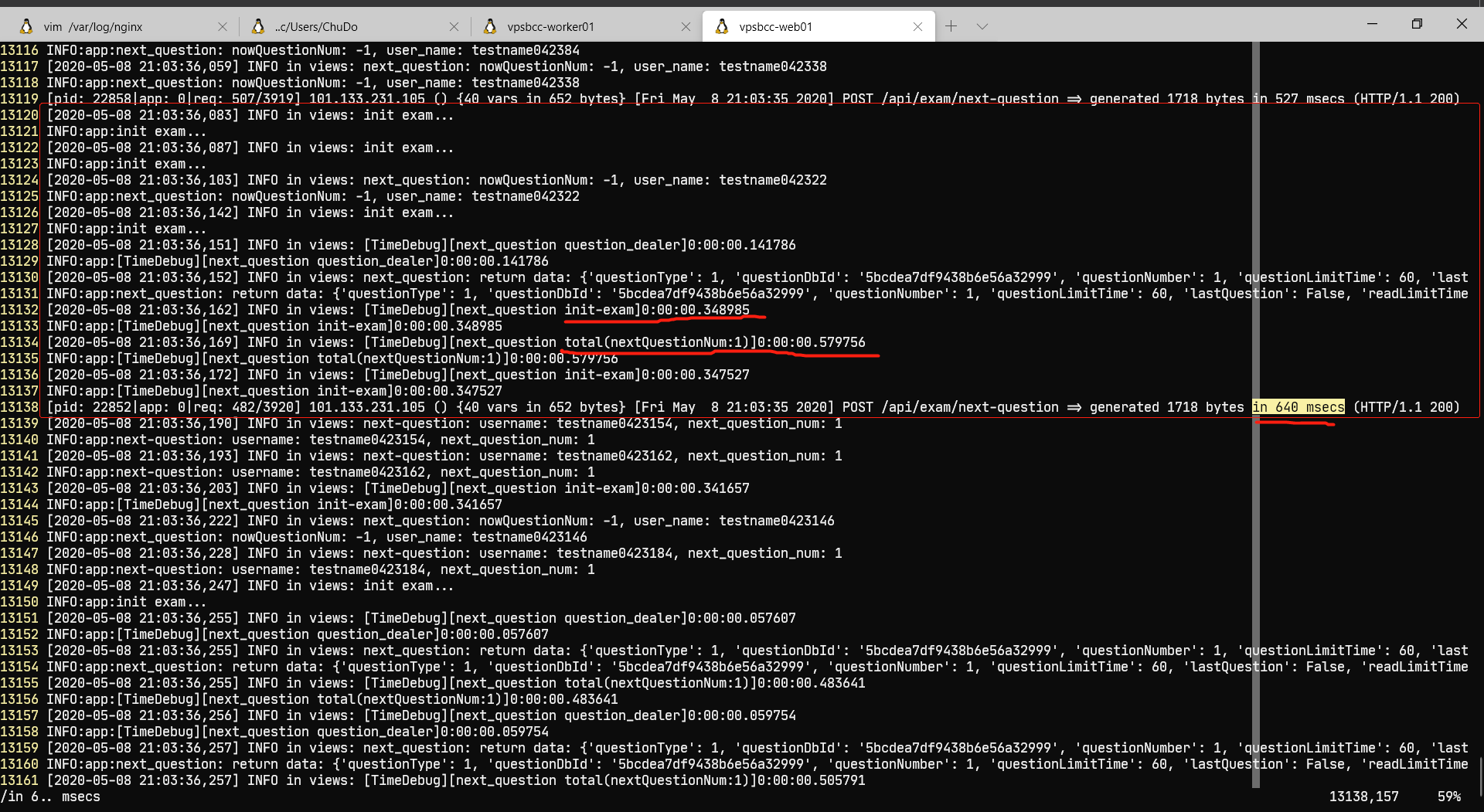
所以代码执行速度还可以,锅是uwsgi的。
过程3 - 是CPU遇到瓶颈了
uwsgi处理很慢,是不是worker数量太少?所以尝试把2进程增大到4/8/16/64进程,但是性能并没有变好,4进程的时候似乎快了一点,8进程似乎又慢了一点,16/64进程反而导致性能再次下降。猜测是CPU性能不够。prometheus和vps自带监控精度都太低,不能看到瞬发的CPU占用率,于是开htop肉眼观察,发现请求到达时CPU占用可以到达88%上下,是挺高的。
(可能有人问为什么要500并发瞬发而不连续压测,因为连续压测测试的是吞吐量而不是响应时间)
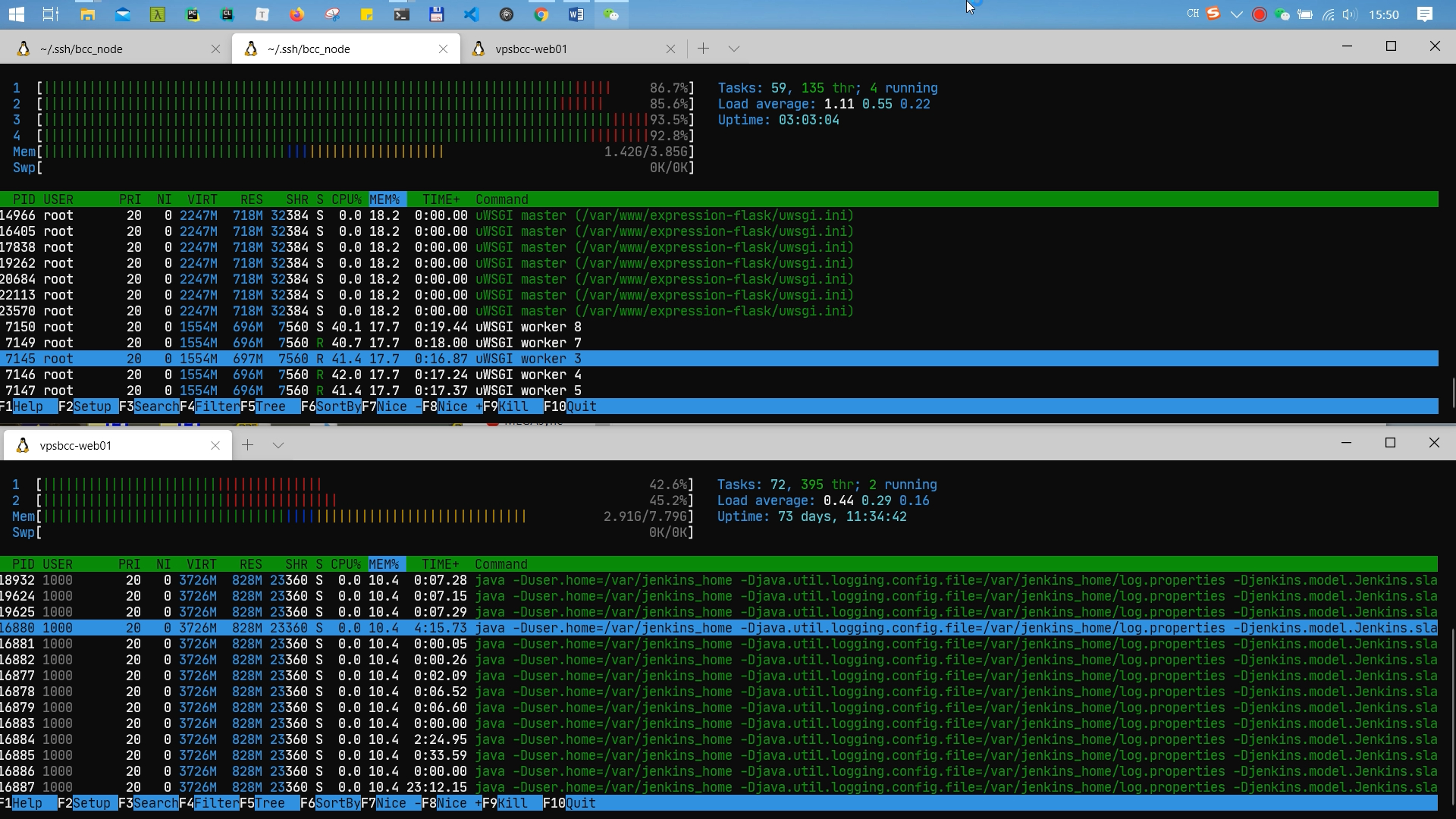
于是临时搭个4核4G的服务器部署Nginx、uwsgi、flask代码,redis和MongoDB仍在原来的2核8G服务器上,配置hosts通过内网访问。
这下提升很明显:
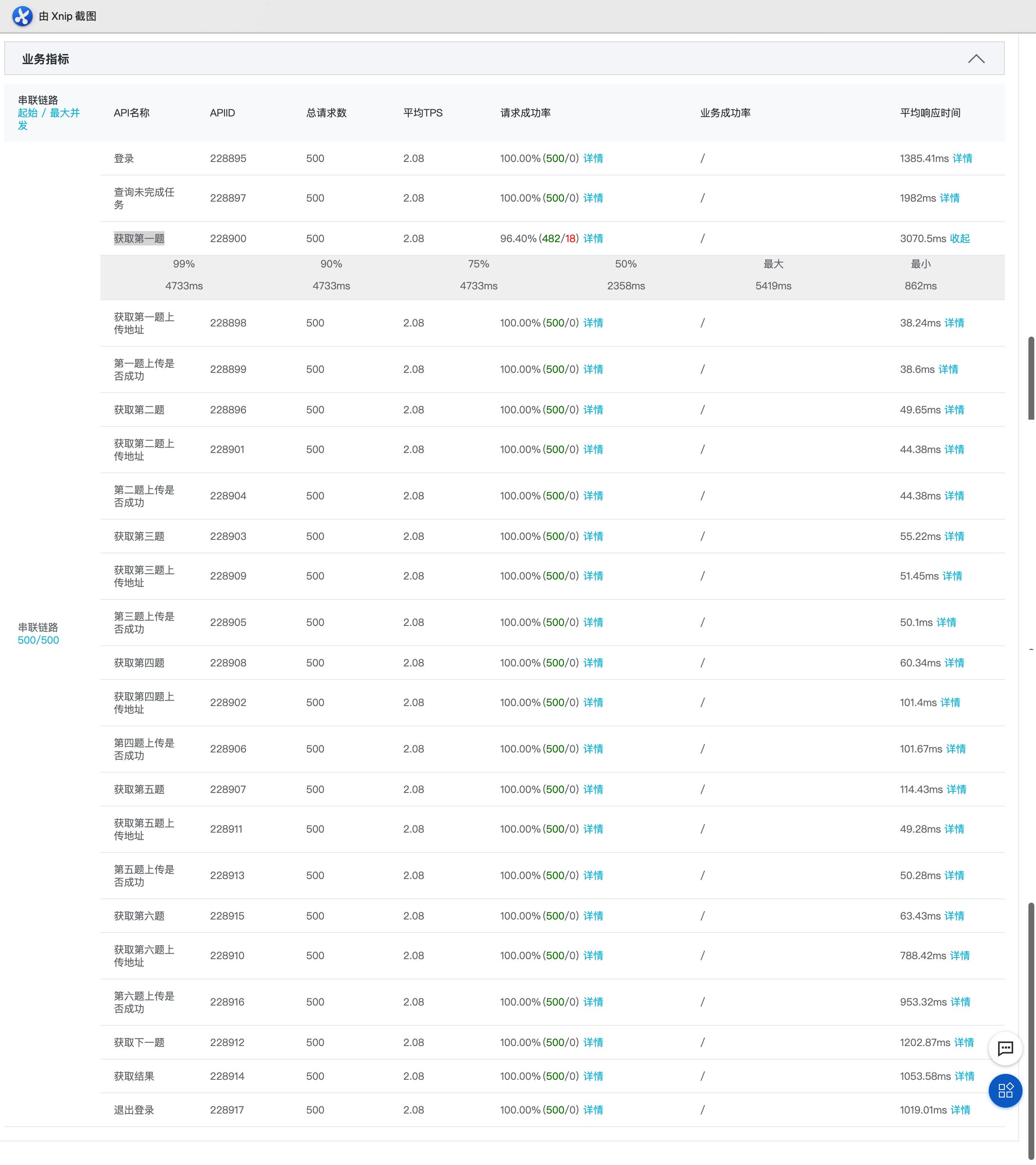
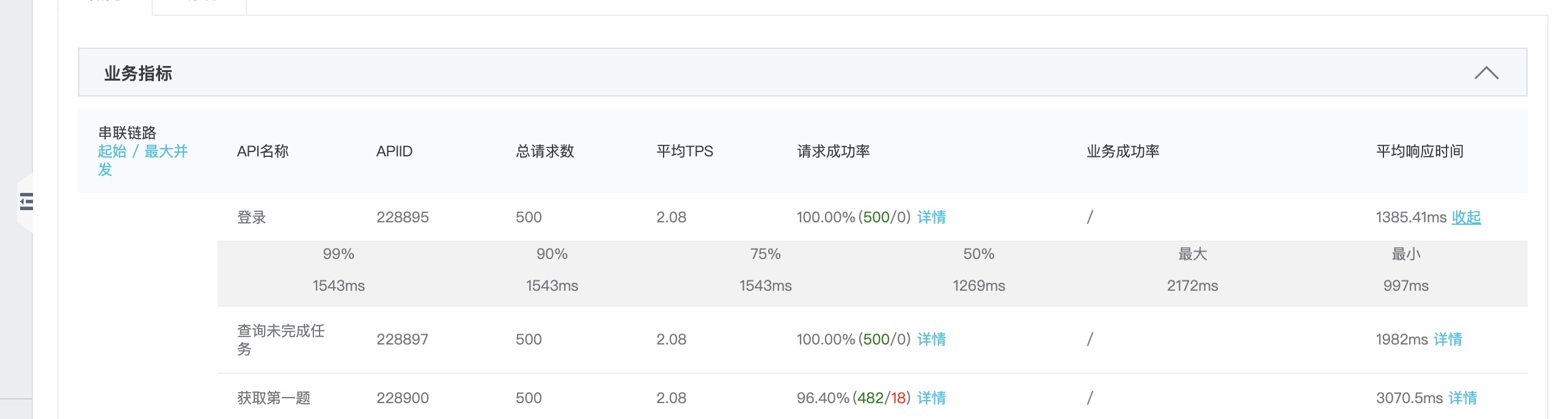
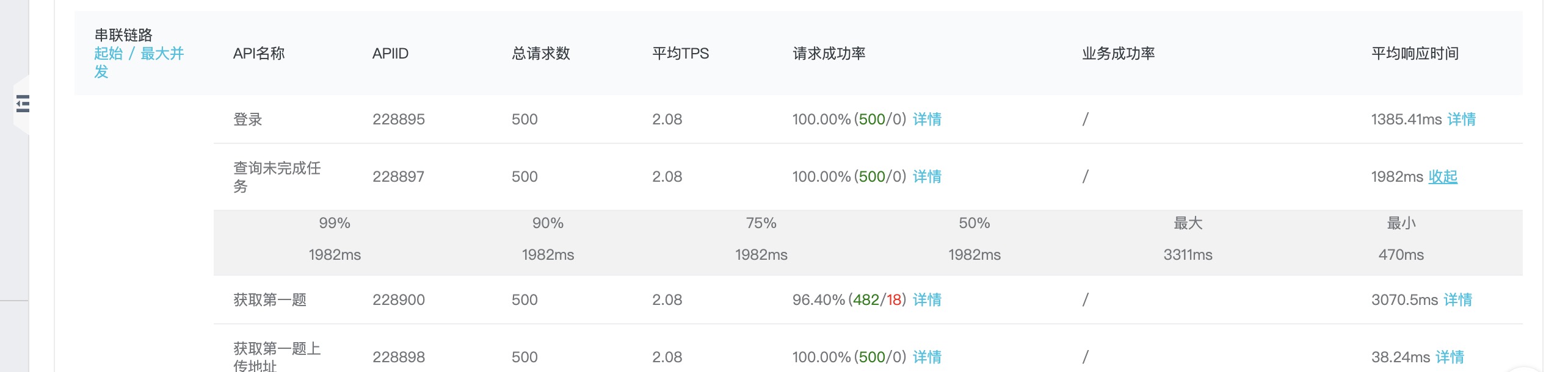
只有第2、3个接口的最大响应时间超过3秒:
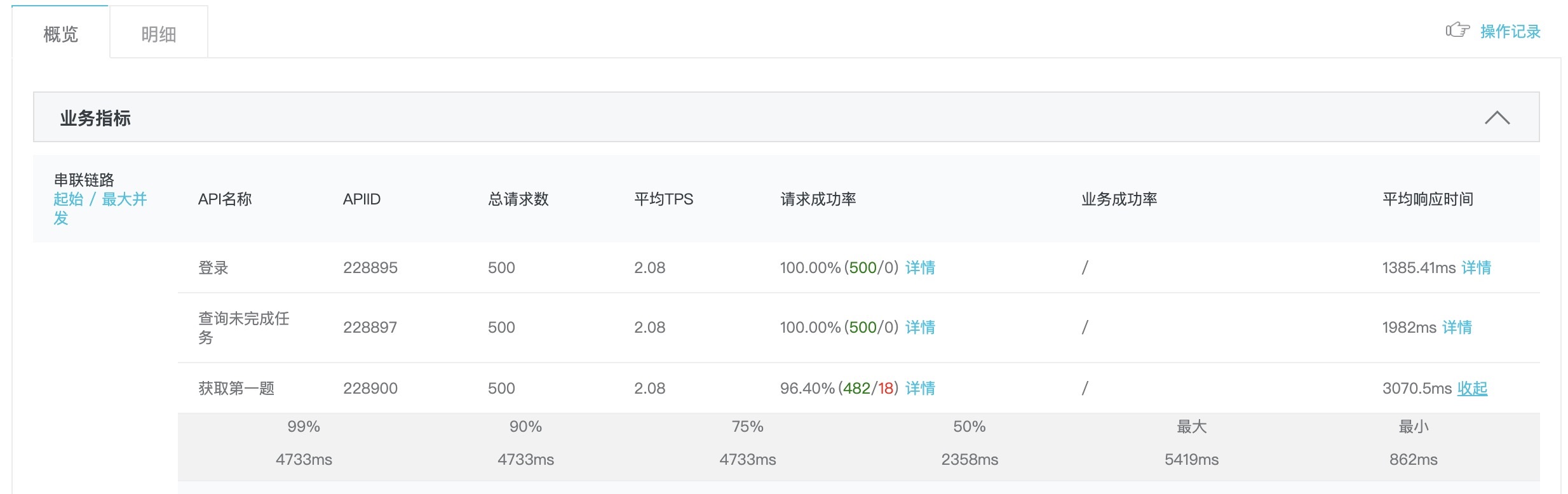
此时CPU峰值占用情况(上面是4核4G的应用服务器,下面是2核8G的数据服务器):
如何解决:
按预设的两台4核4G应用服务器,第2个接口ok。第三个接口时间过长是因为逻辑过于复杂,获取题目之前先进行了试卷初始化工作。把这个接口拆分为两个接口,ok。
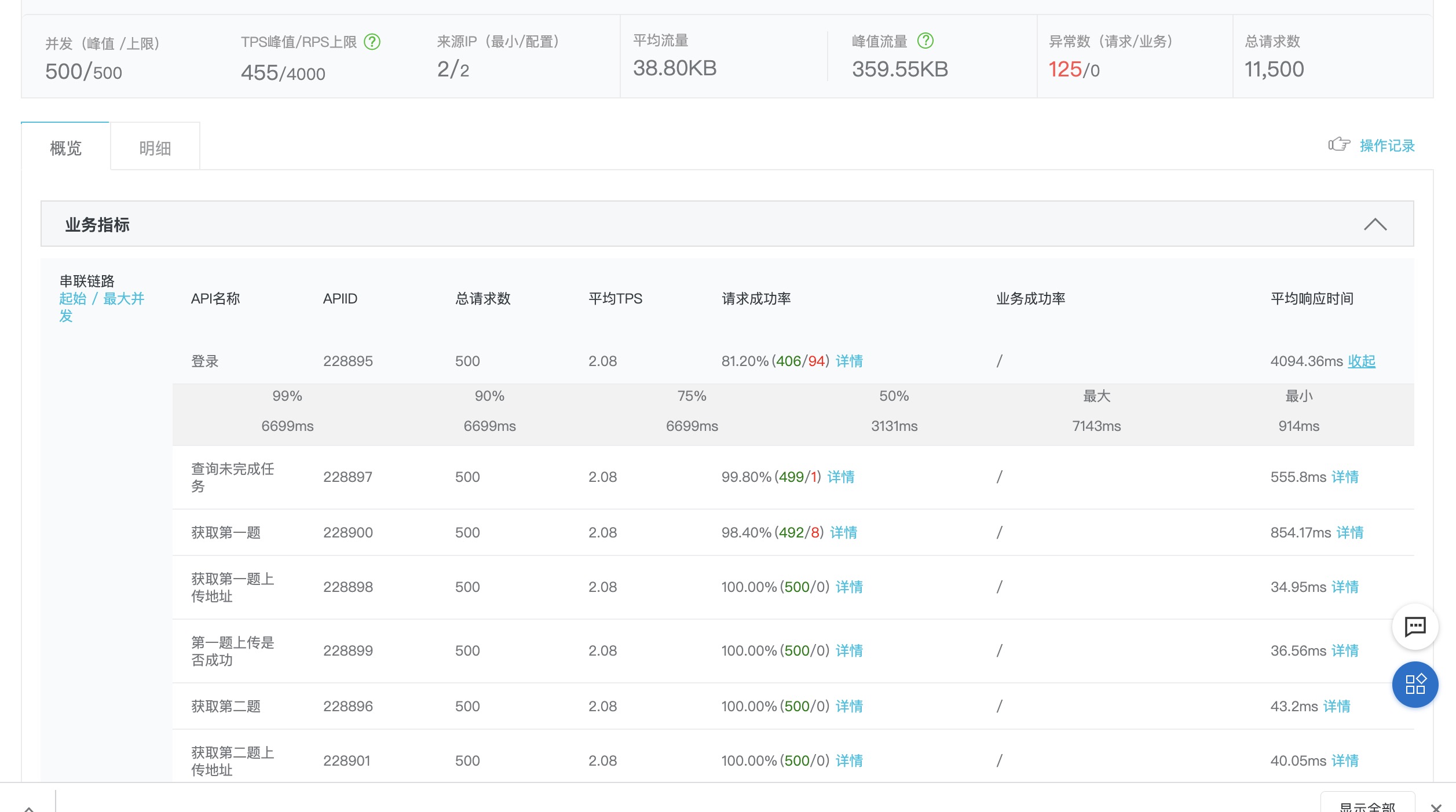
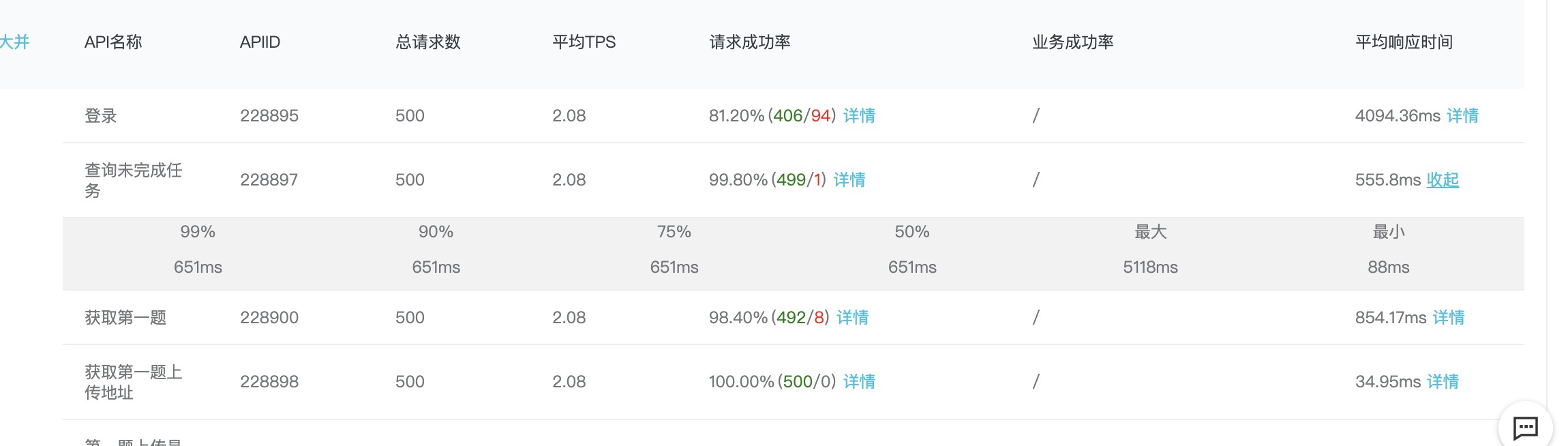
番外 - 验证一下listen的影响
单台4核4G应用服务器+单台2核8G数据服务器的情况下,把listen改回100看看对结果有多大影响:
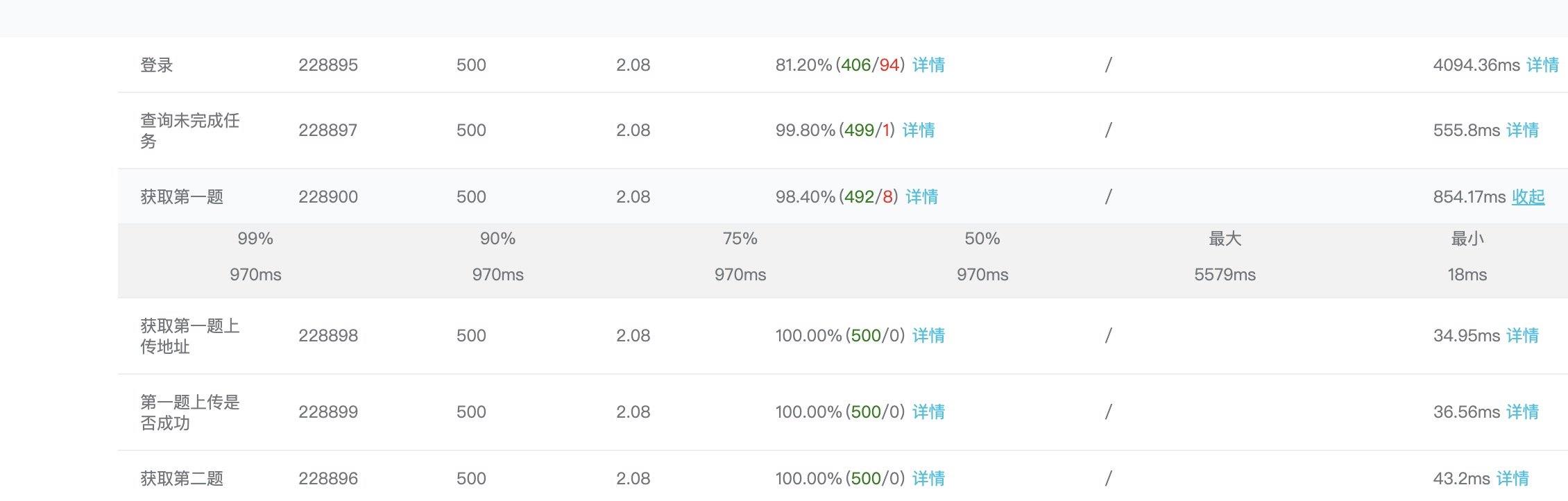
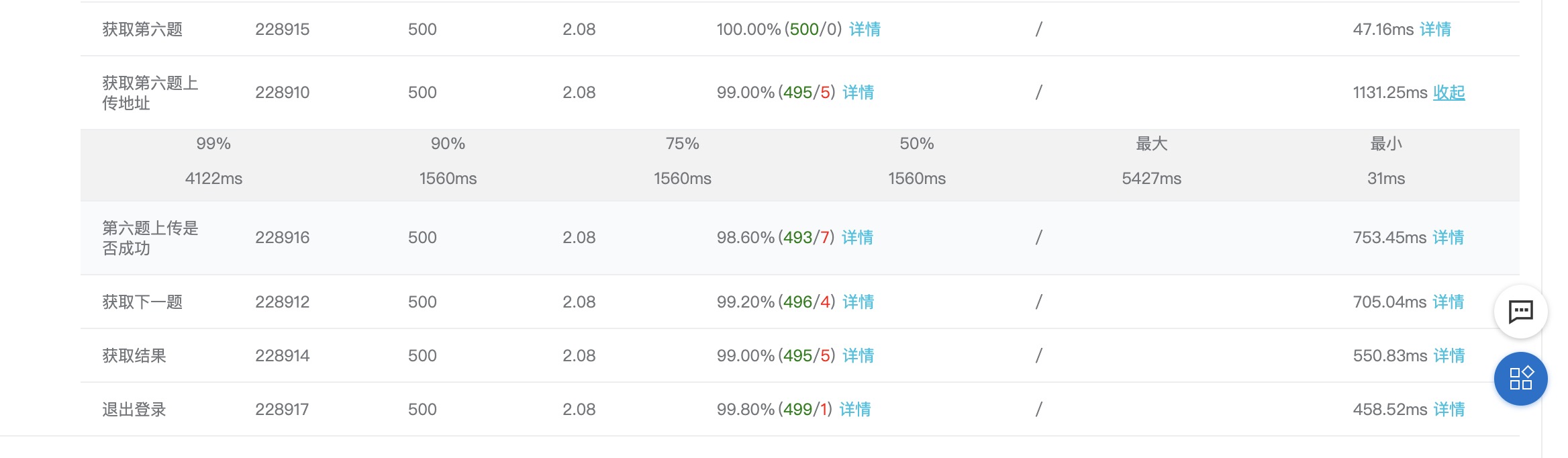
此外uwsgi日志中可查找到队列满的告警信息。
根据结果看listen的影响还是比较明显的,数值过小和Nginx的bargain太多而且不能充分调动每个worker的积极性。🤦♂️

 浙公网安备 33010602011771号
浙公网安备 33010602011771号