

NLP中的数据增强
相关方法合集见:https://github.com/quincyliang/nlp-data-augmentation
较为简单的数据增强的方法见论文:https://arxiv.org/pdf/1901.11196.pdf
论文中所使用的方法如下:
1. 同义词替换(SR: Synonyms Replace):不考虑stopwords,在句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。(同义词其词向量可能也更加接近,在使用词向量的模型中不一定有用)
2. 随机插入(RI: Randomly Insert):不考虑stopwords,随机抽取一个词,然后在该词的同义词集合中随机选择一个,插入原句子中的随机位置。该过程可以重复n次。
3. 随机交换(RS: Randomly Swap):句子中,随机选择两个词,位置交换。该过程可以重复n次。
4. 随机删除(RD: Randomly Delete):句子中的每个词,以概率p随机删除。(类似于神经网络中的dropout)
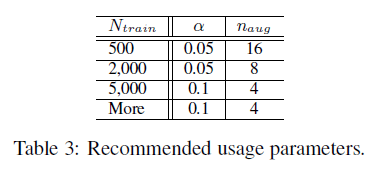
第一列是训练集的大小,第三列是每个句子生成的新句子数,第二列是每一条语料中改动的词所占的比例。
相关实现见:https://github.com/zhanlaoban/eda_nlp_for_Chinese
还有些如打乱句子的顺序,随机进行Mask,相比于直接复制能够加入一些噪声,以防止过拟合。
还有些通过神经网络进行数据增强的方法,但是代价相对较高,同时效果也不一定会好。
相关讨论见:https://www.zhihu.com/question/305256736?sort=created
不同的数据增强方式不能确切的说谁强谁弱,对于NLP任务而言,一切从数据出发,需要结合具体任务进行检验。

