

ZEN、ELECTRA、ALBERT
一、ZEN
目前,大多数中文预训练模型基本上沿用了英文模型的做法,聚焦于小颗粒度文本单元(字)的输入。然而,与英文相比,中文没有空格等明确的词语边界。这个特点使得很多文本表达中存在的交叉歧义也被带入了以字为序列的文本编码中,使得模型更难从单字的序列中学习到大颗粒度文本蕴含的语义信息,例如双字或者多字词的整体含义等。虽然通过大规模文本建模可以一定程度上区分不同上下文环境的语义,但是依然没有充分并显式地利用预训练和微调整语料中经常出现的词、短语、实体等更大颗粒度的信息。目前很多模型的解决方法依然是遵循传统BERT模型的遮盖(masking)策略,例如采用多层(词,短语等)遮盖策略来弥补这一缺陷。然而遮盖策略依然只是一种弱监督学习方法,用于学习词边界信息含有诸多问题。
它最大的创新在于输入除了字还有N-gram,把N-gram加在对应的字上,N-gram的向量编码是通过6层的Transformer获得的(作为前6层Transformer输入的一部分,共同训练主语言模型)。
网络结构图如下:
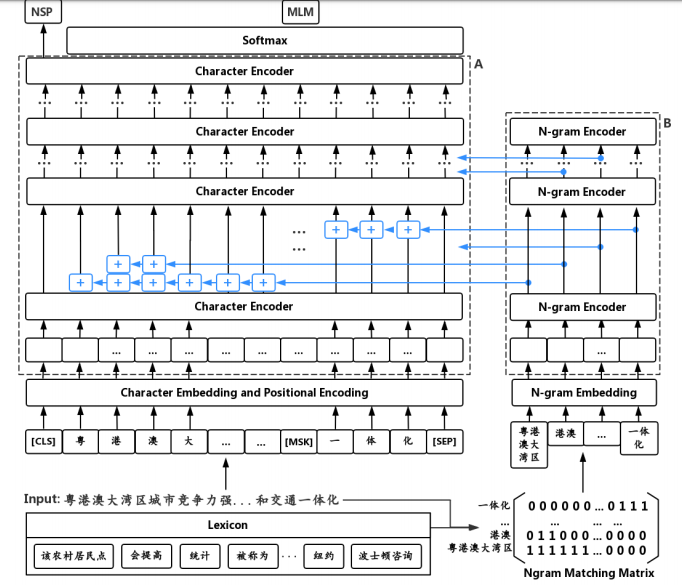
注意力会更多的关注在有效的n-gram。比如“波士顿”的权重明显高于“士顿”。对于有划分歧义的句子,n-gram encoder可以正确的关注到“速度”而不是“高速”。 更加有趣的是,在不同层次的encoder关注的n-gram也不同。更高层的encoder对于“提高速度”和“波士顿咨询”这样更长的有效n-gram分配了更多的权重。这表明,结合n-gram的方法的预训练,不仅仅提供给文本编码器更强大的文本表征能力,甚至还间接产生了一种文本分析的有效方法。(这样就可以更好的利用到词级别的信息,同时能够避免分词错误的影响。)
论文下载地址:https://arxiv.org/pdf/1911.00720.pdf
二、ELECTRA
它的全称是Efficiently Learning an Encoder that Classifies Token Replacements Accurately(有效的学习能够准确分类被替代Token的编码器)它最大的创新在于提出了新的预训练任务和框架,采用了类似于GAN的结构,但与其又有区别。

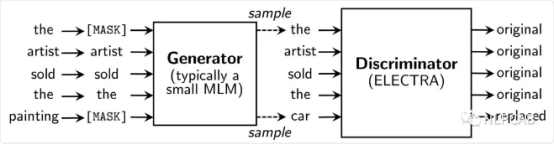
它的生成器和判别器都是由一个编码器组成,例如Transformer
先通过小MLM(生成器的大小在判别器的1/4到1/2之间效果是最好的。作者认为原因是过强的生成器会增大判别器的难度)对被MASK的Token进行生成,然后通过判别器对每个Token进行预测,预测是不是被Mask的词。判别器的目标是序列标注(判断每个token是真是假),两者同时进行训练,但判别器的梯度不会传给生成器,目标函数如下:
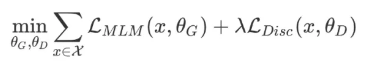
因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。另外要注意的一点是,在优化判别器时计算了所有token上的loss,而以往计算BERT的MLM loss时会忽略没被mask的token。作者在后来的实验中也验证了在所有token上进行loss计算会提升效率和效果
权值的共享
作者认为生成器对embedding有更好的学习能力,因为在计算MLM时,softmax是建立在所有vocab上的,之后反向传播时会更新所有embedding,而判别器只会更新输入的token embedding。最后作者只使用了embedding sharing。
BERT虽然对上下文有很强的编码能力,却缺乏细粒度语义的表示,token编码降维后的效果,可以看到sky和sea明明是天与海的区别,却因为上下文一样而得到了极为相似的编码。细粒度表示能力的缺失会对真实任务造成很大影响。
对抗神经网络在NLP中的应用成为了接下来研究的一个新的点。
论文下载地址:https://openreview.net/pdf?id=r1xMH1BtvB
三、ALBERT
它是基于Bert的改进。
改进一:
在BERT中,字embedding与encoder输出的embedding维度是一样的都是768。但是ALBERT认为,字级别的embedding是没有上下文依赖的表述,而隐藏层的输出值不仅包括了字本身的意思还包括一些上下文信息,理论上来说隐藏层的表述包含的信息应该更多一些,因此应该让H>>E,所以ALBERT的字向量的维度是小于encoder输出值维度的。
在NLP任务中,通常词典都会很大,embedding matrix的大小是V×E(其中V是字表的大小,它是一个很大的值,E是每个字向量的维度),如果和BERT一样让H=E(H是隐藏节点的个数),那么embedding matrix的参数量会很大,并且反向传播的过程中,更新的内容也比较稀疏。
因此ALBERT采用了一种因式分解的方法来降低参数量。首先把one-hot向量映射到一个低维度的空间,大小为E,然后再映射到一个高维度的空间,说白了就是先经过一个维度很低的embedding matrix,然后再经过一个高维度matrix把维度变到隐藏层的空间内,从而把参数量从O(V×H)(因为要使得字向量的维度和hidden_size的维度相等,保持相等时因为有个残差网络的直接相加,所以不得不使得字向量的维度设为H)降低到了O(V×E+E×H)(通过V×E维度的矩阵和E×H维度的矩阵相乘),当E<<H时参数量减少的很明显。
改进二:
对于预训练任务的改进。论文中指出预测下一句(NSP)任务相比于MLM而言过于简单,BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,主要原因是因为其任务过于简单。NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类似的效果。
ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP因为是在同一个文档中选的,其只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。
改进三:
作者提出预训练任务很难会过拟合,因此去除了dropout.
改进四:
跨层的参数共享:在ALBERT还提出了一种参数共享的方法,Transformer中共享参数有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数,同样量级下的Transformer采用该方案后实际上效果是有下降的,但是参数量减少了很多,训练速度也提升了很多。
论文下载地址:https://openreview.net/pdf?id=H1eA7AEtvS
中文版预训练好的模型:https://github.com/brightmart/albert_zh

