
NLP之CRF应用篇(序列标注任务)
1.CRF++的详细解析
完成的是学习和解码的过程:训练即为学习的过程,预测即为解码的过程。
模板的解析:
具体参考hanlp提供的:
http://www.hankcs.com/nlp/the-crf-model-format-description.html
Unigram和Bigram模板分别生成CRF的状态特征函数和转移特征函数。其中是标签,x是观测序列,i是当前节点位置。每个函数还有一个权值。
注意:一般定义CRF++的模板只定义Unigram即为CRF的状态特征函数(对于观测状态不同的组合即为其区别于HMM的观测独立性假设的地方,是对上下文的充分利用),一般只有一个单独的B,很多情况B模版只有一个“B”字符,此时就不考虑观测值,只有“前面一个token”对“当前token”的特征函数。(Only one bigram template ('B') is used. This means that only combinations of previous output token and current token are used as bigram features.)
crf++模板定义里的U01%x[row,col],即是特征函数的参数x.U代表Unigram,01只是一个用于作为标识的ID。方括号里的编号用于标定特征来源,row表示相对当前位置的行,0即是当前行;col对应训练文件中的列。
举个例子。假设有如下用于分词标注的训练文件:
北 N B
京 N E
欢 V B
迎 V M
你 N E
其中第3列是标签,也是测试文件中需要预测的结果,有BME 3种状态。第二列是词性,不是必须的。
特征模板格式:%x[row,col]。方括号里的编号用于标定特征来源,row表示相对当前位置的行,0即是当前行;col对应训练文件中的列。这里只使用第1列(编号0),即文字。
1)Unigram类型
每一行模板生成一组状态特征函数,数量是L*N 个,L是标签状态数。N是此行模板在训练集上展开后的唯一样本数,在这个例子中,第一列的唯一字数是5个,所以有L*N = 3*5=15。
例如:U01:%x[0,0],生成如下15个函数:
func1 = if (output = B and feature=U01:"北") return 1 else return 0
func2 = if (output = M and feature=U01:"北") return 1 else return 0
func3 = if (output = E and feature=U01:"北") return 1 else return 0
func4 = if (output = B and feature=U01:"京") return 1 else return 0
...
func13 = if (output = B and feature=U01:"你") return 1 else return 0
func14 = if (output = M and feature=U01:"你") return 1 else return 0
func15 = if (output = E and feature=U01:"你") return 1 else return 0
这些函数经过训练后,其权值表示函数内文字对应该标签的概率(形象说法,概率和可大于1)。
每个模板会把所有可能的标记输出都列一遍,然后通过训练确定每种标记的权重,合理的标记在训练样本中出现的次数多,对应的权重就高,不合理的标记在训练样本中出现的少,对应的权重就少,但是在利用模板生成转移特征函数是会把所有可能的特征函数都列出来,由模型通过训练决定每个特征的重要程度。
U05:%x[-1,0]/%x[0,0]表示一元复合特征,即当前行的第一列与其前一行的第一列的复合特征
假如我们训练的语料句子是:我是中国人(下标:-2,-1,0,1,2),我们考虑的当前位置为:“中”
U0--U4特征模板:表示某个位置与当前位置的信息之间的关系,比如说U00,就是指的“我”和“中”之间的联系
U5--U7特征模板:表示某三个位置与当前位置的信息之间的关系,比如说U05,就是指的“我”、“是”、“中”和“中”之间的联系
U8--U9特征模板:表示某两个位置与当前位置的信息之间的关系,比如说U08,就是指的“是”、“中”和“中”之间的联系
又如 U02:%x[-1,0],训练后,该组函数权值反映了句子中上一个字对当前字的标签的影响。
对某一个特征函数的具体解析:
func1 = if (output = B and feature="U02:那") return 1 else return 0
它是由U02:%x[0,0]在输入文件的第一行生成的点函数.将输入文件的第一行"代入"到函数中,函数返回1,同时,如果输入文件的某一行在第1列也是“那”,并且它的output(第2列)同样也为B,那么这个函数在这一行也返回1。
2)Bigram类型
与Unigram不同的是,Bigram类型模板生成的函数会多一个参数:上个节点的标签 。
生成函数类似于:
func1 = if (prev_output = B and output = B and feature=B01:"北") return 1 else return 0
这样,每行模板则会生成 L*L*N 个特征函数。经过训练后,这些函数的权值反映了上一个节点的标签对当前节点的影响。
每行模版可使用多个位置。例如:U18:%x[1,1]/%x[2,1]
字母U后面的01,02是唯一ID,并不限于数字编号。如果不关心上下文,甚至可以不要这个ID。
2.Bi-LSTM+CRF中CRF层的详细解析
https://blog.csdn.net/buppt/article/details/82227030
https://blog.csdn.net/bobobe/article/details/80489303
https://www.jianshu.com/p/97cb3b6db573
我们已知lstm的输出就是每个字标注的概率。假设lstm输出概率如下所示。这里为了方便,只写了 BMEO 4种标注结果。更多的话也是相同的。
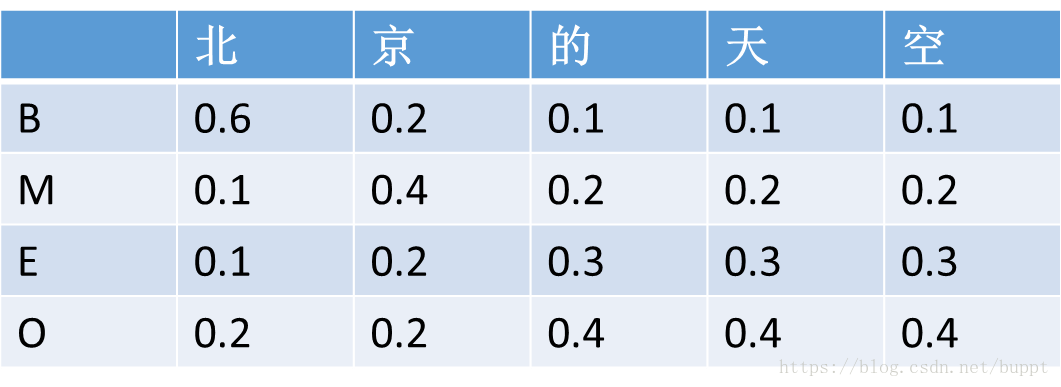
而crf首先在每句话的前面增加一个<start>字,在每句话的结尾增加一个<end>字。
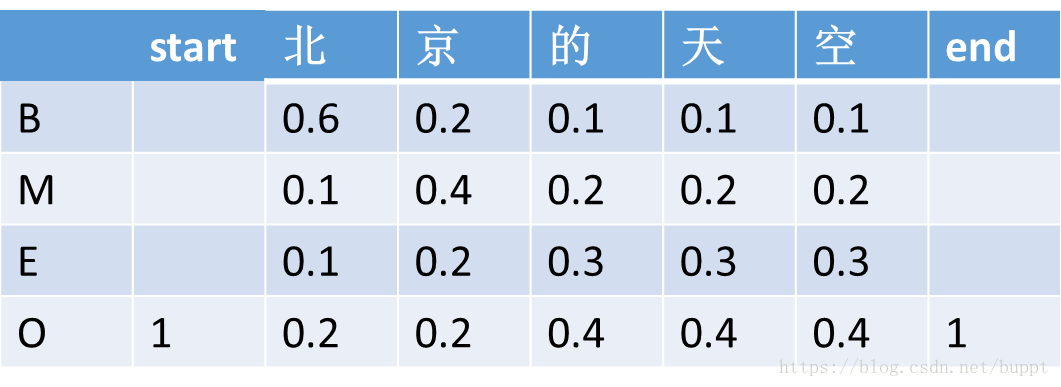
然后定义了一个转移矩阵,转移矩阵中的数值代表前面一个字标注结果到下一个字的标注结果的概率。比如下面矩阵中的第一行,代表的含义就是前一个字标注为start,下一个字标注为B 的概率是0.6,标注为O的概率就是0.4。这个矩阵是随机初始化的,里面的数值也是通过梯度下降自动更新的。
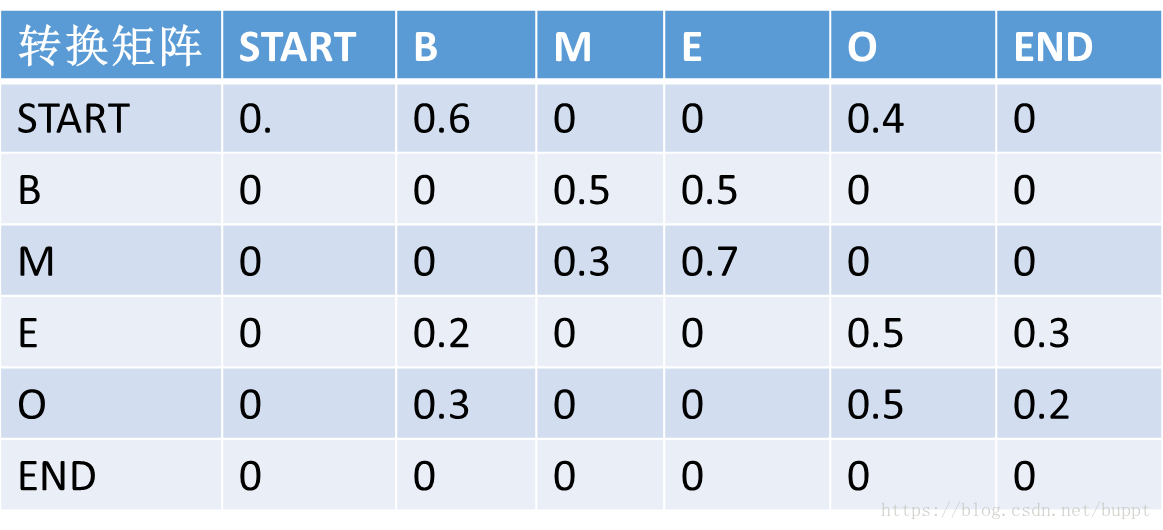
然后又定义了“路径”这个概念,一句话的每一种标注结果就代表一个路径。下图就代表两条路径。
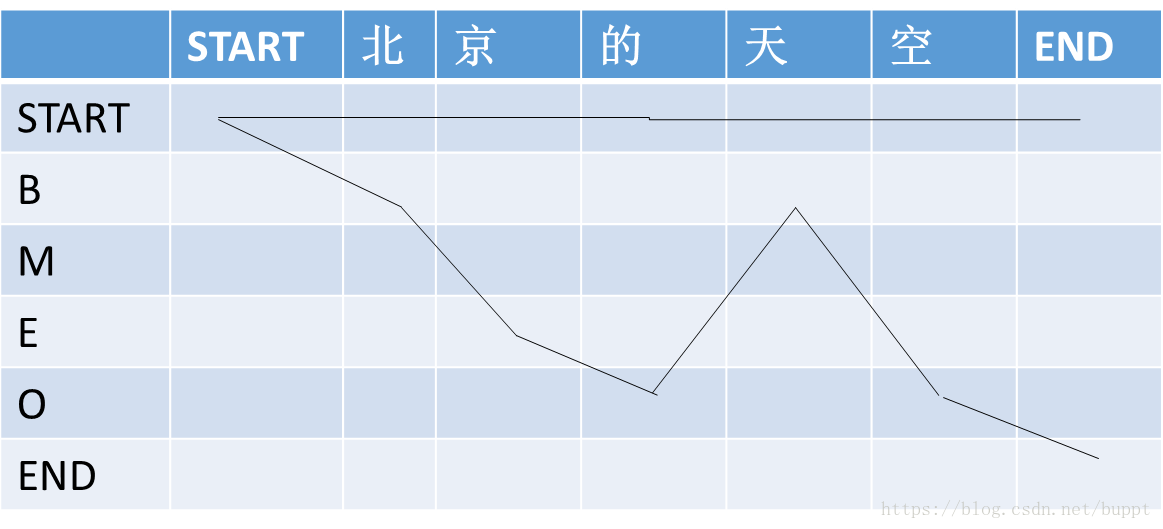
每条路径的分数 P=e^s
s = 初始分数 + 转换分数
初始分数 = 路径上lstm输出分数和
转换分数 = 路径上转换矩阵分数和
具体用数学公式进行如下表示:
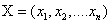
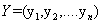
对于每一个序列输入,我们得到一个预测label序列,定义这个预测的得分为:
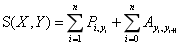
其中Pi,yi为第i个位置网络结构的预测输出为yi的概率,即为初始分数。Ayi,yi+1为从yi到yi+1的转移概率,即为转换分数。转移概率矩阵为(n+2)*(n+2),因为额外增加了一个开始位置和结束位置。这个得分函数S就很好地弥补了传统BiLSTM的不足。
由此可得每条路径的得分,我们的目标是使得正确的路径在所有路径中所占的概率最大化,因此可以用对数最大似然函数。

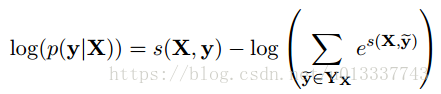
我们的目标是最大化上式,(即真实标记应该对应最大概率值),因为叫损失函数,所以我们也可以对上式取负然后最小化之,这样我们就可以使用梯度下降等优化方法来求解参数。在这个过程中,我们要最大化真实标记序列的概率,也就训练了转移概率矩阵A和BiLSTM中的参数。
BiLSTM+crf的预测
当模型训练完毕后,就可以去测试了。
预测的时候,根据训练好的参数求出所有可能的y序列对应的s得分(这里应该也可以利用维特比算法),然后取:
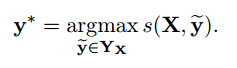 做为预测结果输出。
做为预测结果输出。
3.Bi-LSTM后加CRF的原因
具体参考:
https://blog.csdn.net/bobobe/article/details/80489303
双向lstm后接一个softmax层,输出各个label的概率。那为何还要加一个crf层呢?
我的理解是softmax层的输出是相互独立的,即虽然BiLSTM学习到了上下文的信息,但是输出相互之间并没有影响,它只是在每一步挑选一个最大概率值的label输出,最后的标注是各个序列位置标注的拼接,这样只是获得的局部最优解而没有考虑到全局。因此,就会导致所获得的标注出现不合规则的情况(如B-person后再接一个B-person的问题)。但是在加上CRF之后它是在所有可能的标注结果中选择整体概率做大的标注结果。每条可能标注的概率是lstm的输出概率和标注转换概率之和,这个转换概率是随机初始化的并能够通过训练进行更新,通过此方法能够得到的整体最优解通过还能够避免出现不合理标注的情况。
4.Bert+Bi-LSTM+CRF
“测试输入文本”
绝对位置信息为[0,1,2,3,4,5]
相对位置信息:以入为中心为[-3,-2,-1,0,1,2]
关于相对位置信息和绝对位置信息的介绍参考:https://zhuanlan.zhihu.com/p/92017824
对比bi-lstm依靠其循环机制,结合t 时刻的输入和前一时刻的隐层状态 计算出
,直接通过其顺序结构沿时间维度能够捕获相对和绝对位置信息。对于序列标注任务而言相对位置信息非常重要,例如:

(需要注意的是,相对位置是具有方向性的(Inc. 与 in 的相对距离为 -1,1854 与 in 的相对距离为 1)
而对于Bert而言,其Position-Encoding输入的为绝对位置信息,希望通过self-attention来获得相对位置信息,但是由于Q、K、V都需要先进行线性变换,使得Transformer无法获得相对位置信息。因此引入Bi-lstm是为了获得相对位置信息。
具体应用代码参考
https://blog.csdn.net/luoyexuge/article/details/84728649
个人的github:https://github.com/dylgithub/BERT-BiLSTM-CRF-NER (其中有三个txt文件提供更细致的使用细节描述)
5.CRF和Bi-LSTM+CRF优化目标的区别
对于CRF:在linear-CRF模型参数学习问题中,我们给定训练数据集X和对应的标记序列Y,K个特征函数fk(x,y),我们优化的目标是最大化条件概率Pw(y|x),以对数似然函数作为损失函数,通过梯度下降法求解模型参数wk。
对于Bi-LSTM+CRF:我们把每种可能的标记序列记为一条路径,每条路径的概率值得分一部分由softmax的输出概率值组成,另一部分由转移矩阵的概率值组成,我们优化的目标是使得正确的路径所对应的概率值得分在所有路径中所占的概率最大化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号