
Attention篇(二)
主要是对《Attention is all you need》的分析
结合:http://www.cnblogs.com/robert-dlut/p/8638283.html 以及自己的一些东西
先是最基础的单元放缩点积注意力机制

放缩即为在点积注意力机制的基础上只是多除了一个(每个头的维度)起到调节作用(这里为什么除的是√dk?在原论文中指出,每个头点积之后变成0均值,方差为dk,为了使得变量保持同一量纲,因此对值进行缩放,通过z-score标准化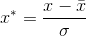 ,均值已为0相当于不减,除标准差,而方差变为了dk,故此处除的为√dk),使得内积不至于太大。这里使用的是self-attention.Scale部分是放缩,Mask部分是遮罩,在decoder部分才有用,是为了在解码时不看到未来的信息。
,均值已为0相当于不减,除标准差,而方差变为了dk,故此处除的为√dk),使得内积不至于太大。这里使用的是self-attention.Scale部分是放缩,Mask部分是遮罩,在decoder部分才有用,是为了在解码时不看到未来的信息。
随后是多头attention(Multi-head attention)结构如下图:
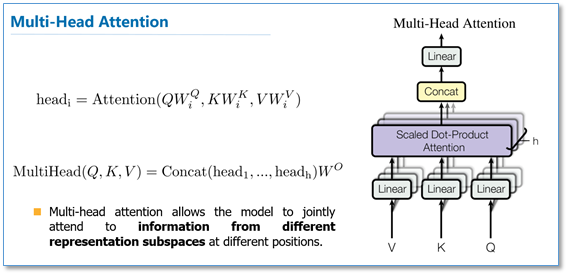
Query,Key,Value首先经过一个线性变换,然后输入到放缩点积attention,注意这里要做h次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数W是不一样的。然后将h次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。
为什么要先进行一次线性变换,因为使用的为多头,随后要进行头的划分。
使用多头的好处,不同的头能够提取到不同的信息。类似于CNN中为什么要使用多个卷积核,是为了能够从多个角度进行特征提取。
为什么使用self-attention?,一方面是因为其相较于CNN类的特征提取器能够获得更多的全局信息,相较于RNN类的特征提取器它能够实现并行,另一方面或许有更好的别的attention机制,使用它主要是因为它实现简单效果好效率高,所以广泛应用于需要通过海量数据来预训练语言模型的任务中。
那么在整个模型中,是如何使用attention的呢?如下图,首先在编码器到解码器的地方使用了多头attention进行连接,K,V,Q分别是编码器的层输出(这里K=V)和解码器中多头attention的输入。其实就和主流的机器翻译模型中的attention一样,利用解码器和编码器attention来进行翻译对齐。然后在编码器和解码器中都使用了多头自注意力self-attention来学习文本的表示。Self-attention即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。

其中黄色部分的Add是残差网络,Norm使用的为层次归一化(为什么这里使用的是Layer Normalization参考另一篇博客https://www.cnblogs.com/dyl222/p/12197187.html)。加入残差网络是因为Transformer是多层的防止出现网络退化。加入层次归一化的好处是能够一定程度的解决网络学习困难的问题,加快网络的收敛。
其中Feed Forword部分为
其中蓝色的部分是一个前馈的神经网络FFN(x)=relu(xW1+b1)W2+b2
Self-Attention和传统的soft-Attention的区别:
Self Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的依赖关系。但Self Attention不同,它分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。因此,self Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号