


Redis应用实践
一:Redis基本操作
基于RedisTemplate(Spring对操作Redis数据库的封装)对五种数据类型的操作
string类型 
适用场景:一般的key-value缓存,计数功能的缓存。
list类型 
适用场景: value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
hash类型 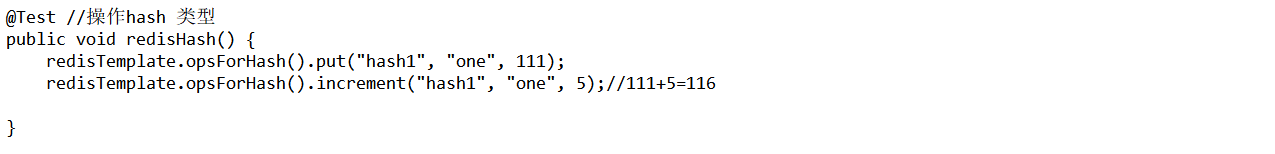
使用场景:使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
set类型 
使用场景: set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
zset类型 
使用场景: sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外,参照另一篇《分布式之延时任务方案解析》,该文指出了sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
常见的几个问题
(一)缓存和数据库双写一致性问题
获取缓存的基本流程: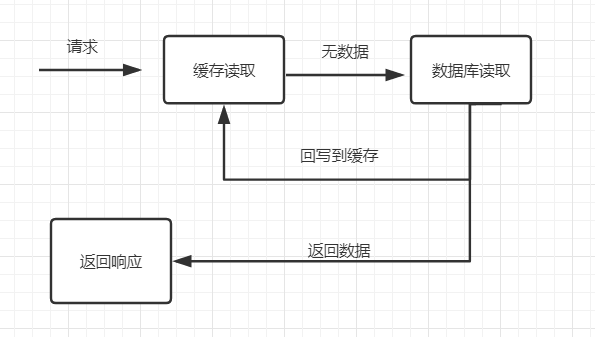
那么有几个问题出现:
1. 先操作缓存中的数据再更新数据库的数据
2. 修改数据库中的数据再操作缓存中的数据
3. 更新缓存还是让缓存失效
redis中的数据和数据库中的数据不可能保证绝对事务性,这个是毫无疑问的,所以在实际应用中,我们都是基于当前的场景进行权衡降低出现不一致问题的出现概率。更新缓存表示数据不但会写入到数据库,还会同步更新缓存,而让缓存失效是表示只更新数据库中的数据,然后删除缓存中对应的key。那么这两种方式怎么去选择?
1. 如果更新缓存的代价很小,那么可以先更新缓存,这个代价很小的意思是不需要很复杂的计算。
2. 如果是更新缓存的代价很大,意味着需要通过多个接口调用和数据查询才能获得最新的结果,那么可以先淘汰缓存。淘汰缓存以后后续的请求如果在缓存中找不到,自然去数据库中检索。
更新数据库和更新缓存这两个操作,是无法保证原子性的,所以我们需要根据当前业务的场景的容忍性来选择。也就是如果出现不一致的情况下,哪一种更新方式对业务的影响最小,就先执行影响最小的方案。
(二)缓存雪崩问题
缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常
1. 对缓存的访问,如果发现从缓存中取不到值,那么通过加锁或者队列的方式保证缓存的单进程操作,从而避免失效时并发请求全部落到底层的存储系统上,但是这种方式会带来性能上的损耗。
2. 将缓存失效的时间分散,降低每一个缓存过期时间的重复率。
3. 如果是因为缓存服务器故障导致的问题,一方面需要保证缓存服务器的高可用、另一方面,应用程序中可以采用多级缓存。
(三)缓存击穿问题
黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常
1. 如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。比如,”key” , “&&”。在返回这个&&值的时候,我 们的应用就可以认为这是不存在的key,那我们的应用就可以 决定是否继续等待继续访问,还是放弃掉这次操作。如果继续等待访问,过一个时间轮询点后,再次请求这个key,如果取到的值不再是&&,则可以认为这时候key有值了,从而避免了透传到数据库,从而把大量的类似请求挡在了缓存之中。
2. 根据缓存数据Key的设计规则,将不符合规则的key进行过滤采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的BitSet中,不存在的数据将会被拦截掉,从而避免了对底层存储系统的查 询压力。
=========================================================================================================================================
我只是一粒简单的石子,未曾想掀起惊涛骇浪,也不愿随波逐流
每个人都很渺小,努力做自己,不虚度光阴,做真实的自己,无论是否到达目标点,既然选择了出发,便勇往直前
我不能保证所有的东西都是对的,但都是能力范围内的深思熟虑和反复斟酌
