


Kafka安装和使用
Kafka官网镇楼:http://kafka.apache.org/
Kafka的官网相对其他集中消息中间件来说,个人认为是很详细和全面的,其实看再多别人写的博客,笔记啥的,都没有看官网好。
版本:kafka_2.12-2.2.0
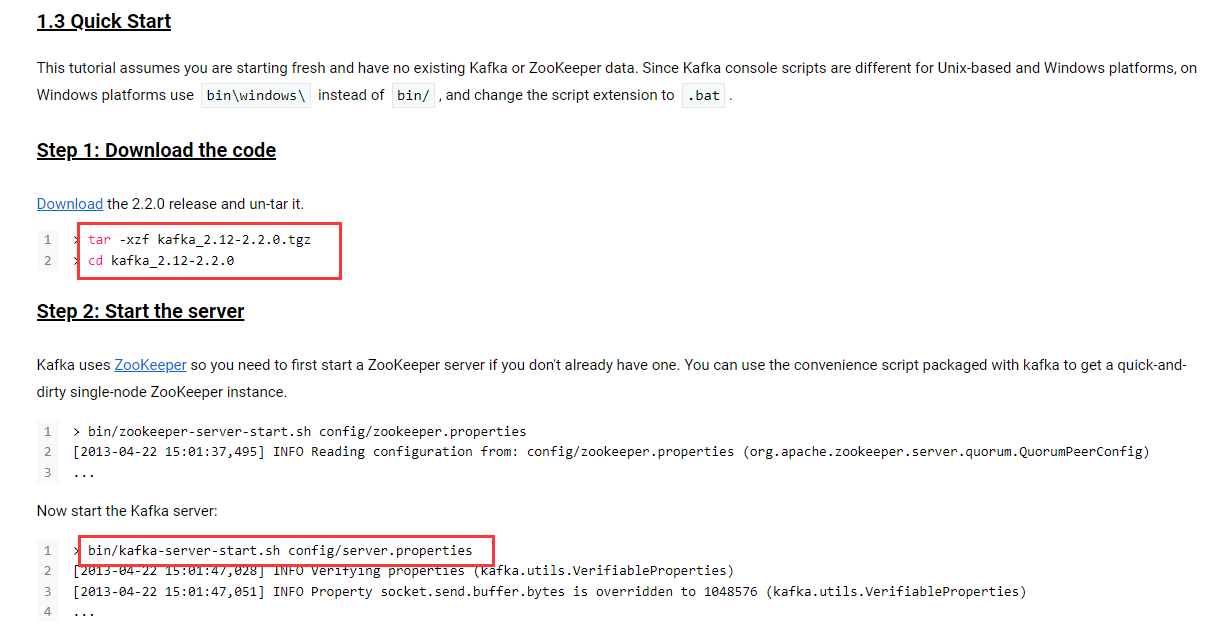
基本安装过程:链接 Quick Start
Kafka 是一款分布式消息发布和订阅系统,具有高性能、高吞吐量的特点而被广泛应用与大数据传输场景。它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会的一个顶级项目。kafka 提供了类似 JMS 的特性,但是在设计和实现上是完全不同的,而且他也不是 JMS 规范的实现。
Kafka 的应用场景
行为跟踪:kafka 可以用于跟踪用户浏览页面、搜索及其他行为。通过发布-订阅模式实时记录到对应的 topic 中,通过后端大数据平台接入处理分析,并做更进一步的实时处理和监控。
日志收集:日志收集方面,有很多比较优秀的产品,比如 Apache Flume,很多公司使用kafka 代理日志聚合。日志聚合表示从服务器上收集日志文件,然后放到一个集中的平台(文件服务器)进行处理。在实际应用开发中,我们应用程序的 log 都会输出到本地的磁盘上,排查问题的话通过 linux 命令来搞定,如果应用程序组成了负载均衡集群,并且集群的机器有几十台以上,那么想通过日志快速定位到问题,就是很麻烦的事情了。所以一般都会做一个日志统一收集平台管理 log 日志用来快速查询重要应用的问题。所以很多公司的套路都是把应用日志几种到 kafka 上,然后分别导入到 es 和 hdfs 上,用来做实时检索分析和离线统计数据备份等。而另一方面,kafka 本身又提供了很好的 api 来集成日志并且做日志收集。
一个典型的 kafka 集群包含若干 Producer(可以是应用节点产生的消息,也可以是通过Flume 收集日志产生的事件),若干个 Broker(kafka 支持水平扩展)、若干个 Consumer Group,以及一个 zookeeper 集群。kafka 通过 zookeeper 管理集群配置及服务协同。Producer 使用 push 模式将消息发布到 broker,consumer 通过监听使用 pull 模式从broker 订阅并消费消息,

基于kafka-clients的简单使用:

Kafka服务端
/**
* kafka 服务端
*/
public class MyKafkaServer extends Thread{
private final KafkaProducer<Integer,String> producer;//消息发送者
private final String topic;//主题
public MyKafkaServer(String topic) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"ip:9092");
properties.put(ProducerConfig.CLIENT_ID_CONFIG,"kafkaServertest");
//确认机制
//0:表示 producer 不需要等待 broker 的消息确认。这个选项时延最小但同时风险最大(因为当 server 宕机时,数据将会丢失)。
//1:表示 producer 只需要获得 kafka 集群中的 leader 节点确认即可,选择时延较小同时确保了 leader 节点确认接收成功。
//-1:需要 ISR 中所有的 Replica 给予接收确认,速度最慢,安全性最高,但是由于 ISR 可能会缩小到仅包含一个 Replica,所以设置参数为 all 并不能一定避免数据丢失。
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.IntegerSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//ProducerConfig.BATCH_SIZE_CONFIG 批量发送大小,默认大小是 16384byte,也就是 16kb,意味着当一批消息大小达到指定的 batch.size 的时候会统一发送
//ProducerConfig.LINGER_MS_CONFIG 时间间隔发送
//batch.size 和 linger.ms 这两个参数是 kafka 性能优化的关键参数,当二者都配置的时候,只要满足其中一个要求,就会发送请求到 broker 上
//ProducerConfig.PARTITIONER_CLASS_CONFIG 可以传自定义分区 如自定义KafkaPartition.class (分片的思想)
//消费者小于分区,肯定有消费者消费多个分区,如果多于分区,肯定有消费者消费不到,
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer, String>(properties);
this.producer = producer;
this.topic = topic;
}
@Override
public void run() {
String sendMessage = "sendMessage-";
for (int i = 0; i < 10; i++) {
int random = ThreadLocalRandom.current().nextInt(100);
sendMessage += random;
ProducerRecord<Integer, String> record = new ProducerRecord<>(topic,sendMessage);
Future<RecordMetadata> send = producer.send(record,(metadata, exception) ->
System.out.println(metadata.partition()));//异步发送,也可设置成同步
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new MyKafkaServer("topic").start();
}
}
kafka客户端
/**
* kafka 客户端
*/
public class MyKafkaConsumer extends Thread {
private final KafkaConsumer kafkaConsumer;//消息发送者
public MyKafkaConsumer(String topic) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip:9092");
//group.id consumer group 是 kafka 提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),
//它们共享一个公共的 ID,即 group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一
//个消费组内的一个 consumer 来消费.
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "kafkaDemo");
//消费者消费消息以后自动提交,只有当消息提交以后,该消息才不会被再次接
//收到,还可以配合 auto.commit.interval.ms 控制自动提交的频率。
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//auto.offset.reset=latest 情况下,新的消费者将会从其他消费者最后消费的offset 处开始消费 Topic 下的消息
//auto.offset.reset= earliest 情况下,新的消费者会从该 topic 最早的消息开始消费
//auto.offset.reset=none 情况下,新的消费者加入以后,由于之前不存在offset,则会直接抛出异常
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.METRICS_NUM_SAMPLES_CONFIG, "1000");
KafkaConsumer consumer = new KafkaConsumer(properties);
this.kafkaConsumer = consumer;
kafkaConsumer.subscribe(Collections.singleton(topic));
//指定分区
//TopicPartition topicPartition = new TopicPartition(topic, 0);
//kafkaConsumer.assign(Collections.singleton(topicPartition));
}
@Override
public void run() {
while (true) {
Duration duration = Duration.ofSeconds(1);
ConsumerRecords<Integer, String> consumerRecords = kafkaConsumer.poll(duration);
for (ConsumerRecord<Integer, String> consumerRecord : consumerRecords) {
System.out.println("kafka receive :" + consumerRecord.value());
}
}
}
public static void main(String[] args) {
new MyKafkaConsumer("topic").start();
}
}
服务端自定义Kafka分区
配置参数
@Slf4j
public class KafkaPartition implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
partitionInfos.forEach(partitionInfo -> log.info("分区:"+partitionInfo.toString()));
int num = 0;
if(StringUtils.isEmpty(topic)){//随机分区
num = ThreadLocalRandom.current().nextInt(partitionInfos.size());
}else{
num = Math.abs((key.hashCode())%partitionInfos.size());//hash值分区
}
return num;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
Kafka集成Springboot
application.properties文件配置:
kafka.consumer.servers=ip:9092
kafka.consumer.enable.auto.commit=true
kafka.consumer.session.timeout=6000
kafka.consumer.auto.commit.interval=100
kafka.consumer.auto.offset.reset=latest
kafka.consumer.group.id=test
kafka.consumer.concurrency=10
kafka.producer.servers=ip:9092
kafka.producer.retries=0
kafka.producer.batch.size=4096
kafka.producer.linger=1
kafka.producer.buffer.memory=40960
Kafka Producer
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${kafka.producer.servers}")
private String servers;
@Value("${kafka.producer.retries}")
private int retries;
@Value("${kafka.producer.batch.size}")
private int batchSize;
@Value("${kafka.producer.linger}")
private int linger;
@Value("${kafka.producer.buffer.memory}")
private int bufferMemory;
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
}
Kafka Consumer
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${kafka.consumer.servers}")
private String servers;
@Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit;
@Value("${kafka.consumer.session.timeout}")
private String sessionTimeout;
@Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval;
@Value("${kafka.consumer.group.id}")
private String groupId;
@Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.consumer.concurrency}")
private int concurrency;
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
return propsMap;
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(1500);
return factory;
}
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
实现消息发送和接受
@Slf4j
@RestController
@RequestMapping("/kafka")
public class KafkaController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping(value = "/send/{message}", method = RequestMethod.GET)
public void sendKafka(@PathVariable("message") String message) {
try {
log.info("kafka的消息={}", message);
kafkaTemplate.send("test", "key", message);
log.info("发送kafka成功.");
} catch (Exception e) {
log.error("发送kafka失败", e);
}
}
}
@Component
@Slf4j
public class Listener {
@KafkaListener(topics = {"test"})
public void listen(ConsumerRecord<?, ?> record) {
log.info("kafka的key: " + record.key());
log.info("kafka的value: " + record.value().toString());
}
}
=========================================================================================================================================
我只是一粒简单的石子,未曾想掀起惊涛骇浪,也不愿随波逐流
每个人都很渺小,努力做自己,不虚度光阴,做真实的自己,无论是否到达目标点,既然选择了出发,便勇往直前
我不能保证所有的东西都是对的,但都是能力范围内的深思熟虑和反复斟酌
