Jmeter相关术语及图表
1.并发用户数
并发,即为同时出发,从应用系统架构层面来看,并发意为单位时间内服务器接收到的请求数。客户端的某个具体行为包括了若干个请求,因此,并发数被抽象理解为客户端单位时间内发生给服务器端的请求,而客户端的业务请求一般为用户操作行为,因此,并发数理解为并发的用户数,而这些用户是虚拟的,又可称为虚拟用户。
并发数,广义来讲,是单位时间内同时发送给服务器的业务请求,不限定具体业务类型。狭义来讲,是单位时间内同时发送给服务器的相同的业务请求,需限定具体业务类型。
用户数:
1.系统用户数:软件系统注册是用户总数(user表里的数据)。他直接影响着磁盘空间大小,磁盘满和空对系统的查询有影响。(没有经过初始化的性能环境 = 没有作用的环境,因为没有和性能环境一致,制造那么多的用户量。)
2.在线用户数;某段时间内访问的用户数,这些用户数只是在线,不一定同时在做某一件事情。和内存有更大关系,要保持登录状态,session有关,保存在内存中。
3.并发用户数:某段时间同时向软件系统提交请求的用户数,场景不一定是同一个。(严格并发:同样的时刻在做同一件事情(双11抢购),广义并发是:你点你的,我点我的,不一定同时点一个按钮)
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。与吞吐量相比,并发用户数是一个更直观但也更笼统的性能指标。实际上,并发用户数是一个非常不准确的指标,因为不同的使用模式会导致不同用户在单位时间发出不同数量的请求。以网站系统威力,假设用户只有注册后才能使用,但注册用户并不是每时每刻都在使用该网站,因此具体一个时刻只有部分注册用户同时在线,在线用户就在浏览网站时花很多时间阅读网站上的信息,因而具体一个时刻只有部分用户同时向系统发出请求。这样,对于网站系统我们会有三个关于用户数的统计数字:注册用户数、在线用户数和同时发请求用户数。由于注册用户可能长时间不登陆网站,使用注册用户数作为性能指标会造成很大的误差。而在线用户数和同事发请求用户数都可以作为性能指标。相比而言,以在线用户作为性能指标更直观些,而以同时发请求用户数作为性能指标更准确些。
平均并发用户数的计算:C=nL/T 不绝对是这样
C是平均的并发用户数辆,n是平均每天的访问用户数(login session),L是一天内用户从登陆到退出的平均时间(login session的平均时间),T是考察时间长度(一天内多长时间有用户使用系统)
并发用户数峰值计算:C~=C+3*根号C
2.响应时间:从用户发出请求到用户接收到从服务器返回结果整个过程所耗费的时间。(N1+N2+N3+N4)也就是服务器处理时间+网络传输时间
响应时间是指系统对请求作出响应的时间。直观上看,这个指标与人对软件性能的主观感受是非常一致的,因为它完整地得记录了整个计算机系统处理请求的时间。由于一个系统通常会提供许多功能,而不同功能的处理逻辑也千差万别,因而不同功能的响应时间也不尽相同,甚至同一功能在不同输入数据的情况下响应时间也不相同。所以,在讨论一个系统的响应时间时,人们通常是指该系统所有功能的平均时间活着所哟功能的最大响应时间,当然,往往也需要对每个或每组功能讨论其平均响应时间和最大时间。
对于单机的没有并发操作的应用系统而言,人们普遍认为响应时间是一个合理且准确的性能指标。需要指出的是,响应时间的绝对值并不能直接反应软件的性能的高低,软件性能的高低实际上取决于用户对该响应时间的接受程度。对于一个游戏软件来说,响应时间达到3秒就完全难以接受了。而对于编译系统来说,完整编译一个较大规模软件的源代码可能需要几十分钟甚至更长时间,但这些响应时间对于用户来说是可以接受的。
1.用户客户端呈现时间
2.请求/响应数据网络传输时间
3.应用服务器处理时间
4.数据库系统处理时间
对于一个web系统,普遍接受的响应时间标准为2(非常好的)/5(可以接受的)/8(上限)秒。
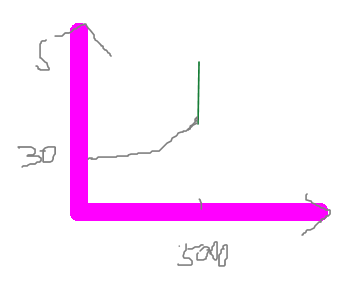
比如这个例子,并发数到了5000,响应时间忽然出现了拐点,就要分析什么原因导致的,看看做了什么。
· 
3.吞吐量:单位时间内处理的客户端请求数量,直接体现服务器的性能承受能力。
吞吐量是指系统在单位时间内处理请求的数量。对于无并发的应用系统而言,吞吐量与响应时间成严格的反比关系,实际上此时吞吐量就是响应时间的倒数。前面已经说过,对于单用户的系统,响应时间(活着系统响应时间和应用延迟时间)可以很好地度量系统的性能,但对于并发系统,通常需要用吞吐量作为性能指标。
对于一个多用户的系统,如果只有一个用户使用时系统的平均响应时间是t,当你有n个用户使用时,每个用户看到的响应时间通常并不是n x t,而往往比n x t小很多(当然,在某些特殊情况下也可能比n x t大,甚至大很多)。这是因为处理每个请求需要用到很多资源,由于每个请求的处理过程中有许多不走难以并发执行,这导致在具体的一个时间点,所占资源往往并不多。也就是说在处理单个请求时,在每个时间点都可能有许多资源被闲置,当处理多个请求时,如果资源配置合理,每个用户看到的平均响应并不随用户的增加而线性增加。实际上,不同系统的平均响应时间随用户数增加而增长的数独也不大相同,这也是采用吞吐量来度量并发系统的性能的主要原因。一般而言,吞吐量是一个比较通用的指标,两个具有不同用户数和用户数使用模式的系统,如果其最大吞吐量基本一致,则可以判断两个系统的处理能力基本一致。

从业务角度来看:吞吐量可以用:请求数/秒,页面数/秒,人数/天 或者 处理业务数/小时 等单位来衡量用 请求数/秒 或者 页面数/秒来衡量。
从网络角度来看:吞吐量可以用:字节/秒来衡量。字节数/天。
每秒事务数(TPS)和每秒查询数(QPS)归属吞吐量,区别在于TPS\QPS描述服务器具体性能处理能力。
对于交互式应用来说,吞吐量的指标反应的是服务器承受的压力,他能够说明系统的负载能力。

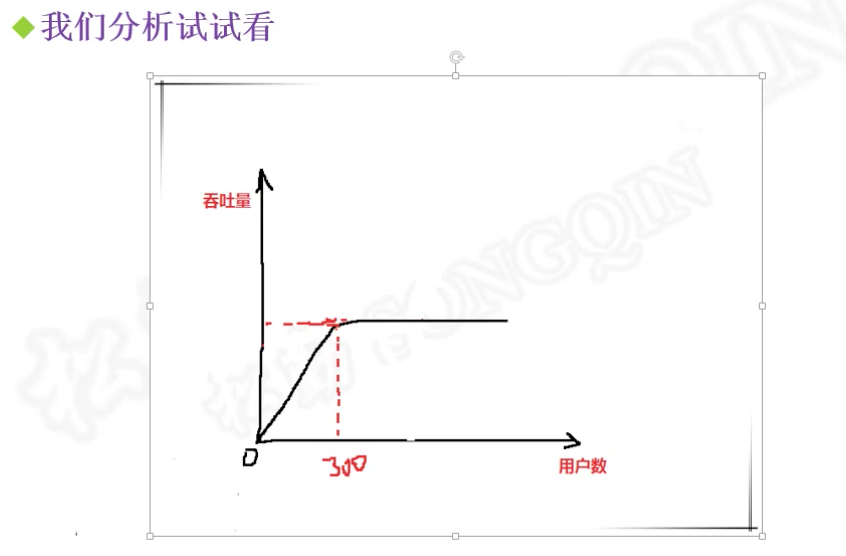
这个就是到了300就不会在增加,相当于饱和了(要看看是内存满了,还是cpu,还是磁盘),300就是头(相当于水满了,再加水也进不去杯子里面了),后面是一条平平的,可能就是网络的问题(比较多)引起的,要增加带宽了,因为丢包了。如果是波浪线,可能是内存满了,和磁盘一直交换,那么可能需要增加服务器。如果是一会上来一会下去,可能就是cpu一会占用一会释放。
4.业务成功率(错误率):系统在负载情况下,失败交易的概率。错误率=(失败交易数/交易总数)*100%

1.不同系统对错误率要求不同,但一般不超过千分之五。(但是不是绝对的)
2.稳定性较好的系数,其错误率应该由超时引起,即为超时率。
5.TPS:每秒事务数(每秒服务器处理的业务数量),接着3来讲,因为是换成了每秒。tps=并发数/平均响应时间(所有的响应时间加起来/次数)。 每秒完成多少个业务功能。
事务就是业务,业务就是客户操作的功能。比如,商城,用户可以搜索商品,这就是一个业务,也是一个事务。事务,可大(购物)可小(搜索)。
事务:业务站在代码角度的统称,也可以理解为一段或者多段代码。
平均相应时间=所有的响应时间加起来/次数


6.QPS: Query Per Second 每秒查询数:每秒服务器能处理的请求数量(衡量web服务器处理能力一个重要指标)。(比如,百度查询一个,在network显示的发送了多少个requests就是每秒查询数 )
每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准,在因特网上,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。(看来是类似TPS,只是应用于特定场景的吞吐量)
应用:控制服务器每秒处理指定请求数(如:控制服务器达到每秒60QPS,服务器的性能各项性能指标是否正常)。每秒发送了多少个请求,通常在负载,压力测试时用来模拟用户的业务背景压力。
和点击数的区别: 一个是发送的资源,一个是请求(不一定是资源)。
7.思考时间
Think Time:从业务角度来看,这个时间指用户进行操作时,每个请求之间的时间间隔。
在做性能测试时,为了模拟这样的时间间隔,引入了思考时间这个概念,来更加真实的模拟用户的操作。
性能计数器:是描述服务器或操作系统性能的一些数据指标
比如:内存
CPU
磁盘等资源使用率等
8.点击数:点击数是衡量web服务器处理能力的一个重要指标。
1.点击数不是通常一般人认为的访问一个页面就是一次点击数,点击数是该页面包含的元素(如:图片,链接、框架等)向web服务器发出的请求数量。比如,我点击百度的百度一下,发出去36个请求资源文件数量(比如css,js,图片等),这个就是数量。(指的是,在页面上点击以后,浏览器往服务器发送http请求资源的请求数量。)
2.通常我们也用每秒点击次数(Hits per Second)指标来衡量web服务器的处理能力。注意:只有web项目才有此指标。
9.资源利用率:系统各种资源的使用情况,一般用“资源的使用量/总的资源可用量*100%”形成资源利用率的数据
提示:通常,没有特殊需求的话,
1)建议CPU(处理器)不高于80%;(+-5)
2)内存不高于80%,所有软件的运行都是靠内存来加载数据。
3)磁盘不高于90%,
4)网络不超过80%,带宽
1.场景设置为500个线程,启动时间为500s,相当于每秒启动1个线程
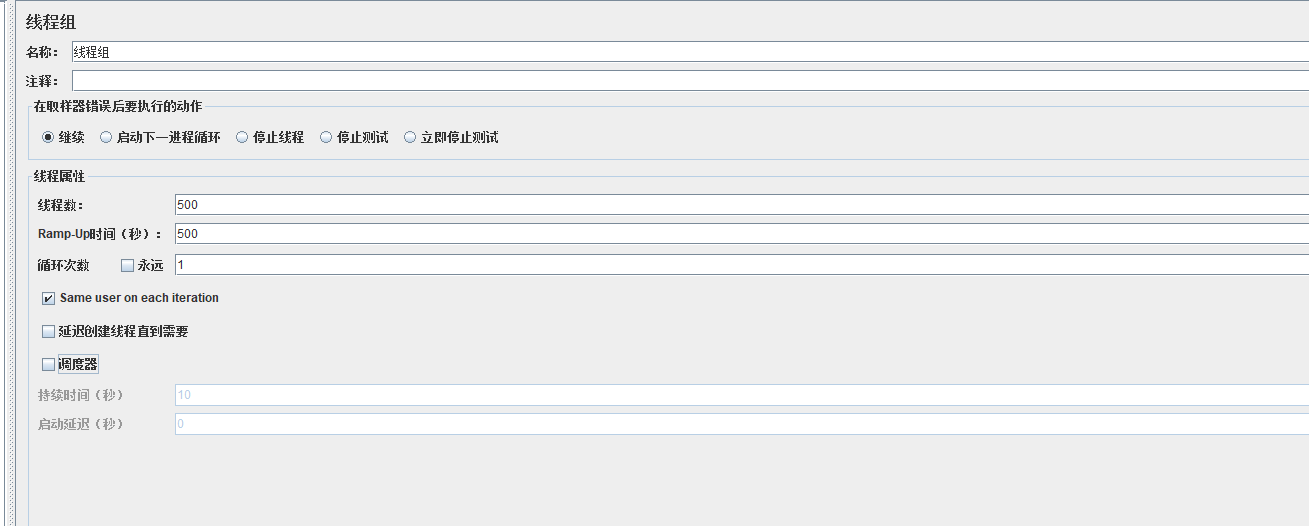
-
取样器错误后要执行的动作
继续:遇错误继续执行,不影响场景运行。默认为继续,常用。
Start Next Thread Loop:执行下次循环,当前循环剩余sampler不再执行。
停止线程:停止当前线程,其他线程继续执行。
停止测试:执行完剩余线程后停止测试。
Stop Test Now:立即停止所有线程。
-
线程属性
线程数:即并发数,如图设置为500并发
Ramp-Up Period (in seconds):并发用户加载时间,如图设置为500s,执行时500s内要加载500并发数
循环次数/永远:填写具体数字,即为并发执行循环次数,一次场景下来,请求的数量=线程数*循环次数;选择永远,则一直执行下去,除非手工停止。
Delay Thread creation until needed:延迟线程创建,直到需要时才创建。
调度器:勾选后,调度器配置项设置生效,可设置场景持续执行时间、延迟启动时间、启动时间、结束时间。
持续时间:场景持续执行的时间
启动延迟:延迟多久执行
场景运行时间包含:持续时间+线程加载时间+循环执行的时间
场景设置为300个线程,启动时间为600s,相当于每个场景每秒启动0.5个线程
3.cmd中执行性能测试:jmeter -n -t D:\soft\apache-jmeter-5.3\Script\HTTP.jmx -l D:\soft\apache-jmeter-5.3\bin\report\report.jtl -e -o D:\soft\apache-jmeter-5.3\bin\report_11
(1)-n 设置命令行模式。
(2)-t 执行运行脚本路径。
(3)-l 指定结果文件路径。
(4)-e 设置测试完成后生成报表。
(5)-o 指定生成的报表文件夹路径,文件夹必须为空或者不存在。
4.自动执行测试
为了减少外部环境的干扰,选择在深夜多次压测取平均值作为结果,使用windows的定时任务功能定时启动bat脚本调用jmeter命令。
(1) 写一个bat脚本
不仅仅是要运行命令,还需要保存测试报告,保存为run.bat放在D盘下。
脚本如下参考:
@echo off if %time:~0,2% GTR 9 (SET curtime=%date:~0,4%-%date:~5,2%-%date:~8,2%-%time:~0,2%-%time:~3,2%) else (SET curtime=%date:~0,4%-%date:~5,2%-%date:~8,2%-%time:~1,1%-%time:~3,2%) D: cd D:\jmeter_script mkdir report%curtime% cd D:\soft\apache-jmeter-5.2.1\bin jmeter -n -t D:\jmeter_script\test001.jmx -l D:\jmeter_script\report%curtime%\report.csv -e -o D:\jmeter_script\report%curtime%\report > D:\jmeter_script\report%curtime%\OutputLog%curtime%.txt
5. 常用图表分析
汇总图:为测试中的每个不同命名的请求创建一个表行。这与聚合报告类似,只是它使用更少的内存。
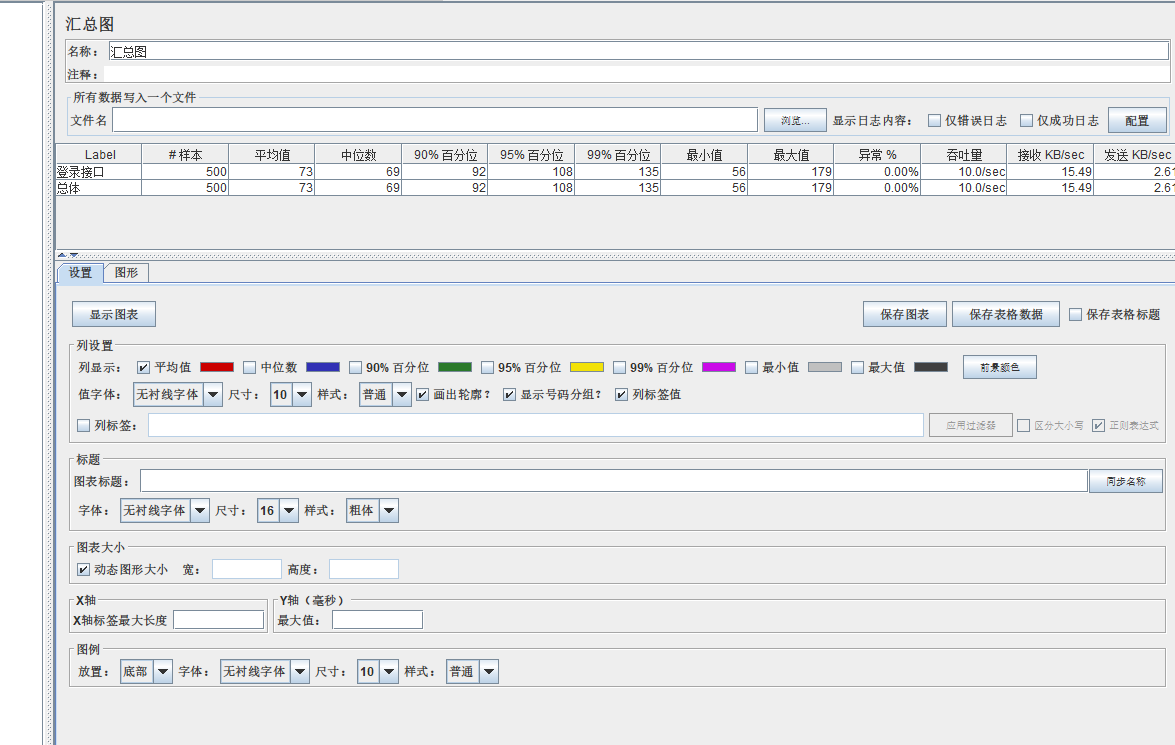
参数说明:
>> Label:取样器别名,如果勾选Include group name,则会添加线程组的名称作为前缀
>> # Samples(样本):取样器运行次数,表示这次测试中一共发了多少个请求
>> Average:请求(事务)的平均响应时间(单位:毫秒),默认是单个Request的平均响应时间,当使用了Transaction Controller时,也可以以Transaction为单位显示平均响应时间
>> Min:请求的最小响应时间
>> Max:请求的最大响应时间
>> Std. Dev:响应时间的标准方差
>> Error %:事务错误率,出现错误的请求数/请求总数百分比值
>> Throughput:吞吐量 也就是TPS,服务器在一定时间范围内处理的请求数,在报告中其实是指吞吐率,表示每秒完成的请求数(request per second)
>> received KB/sec:每秒从服务器接受的数据
>> sent KB/sec:每秒从客户端发送到服务器的数据
指标:错误率越低越好,吞吐量越大越好
添加线程组---Concurrency Thread Group:逐渐梯度加压
Concurrency Thread Group提供了用于配置多个线程计划的简化方法
该线程组目的是为了保持并发水平,意味着如果并发线程不够,则在运行线程中启动额外的线程
和Standard Thread Group不同,它不会预先创建所有线程,因此不会使用额外的内存
Concurrency Thread Group是个更好的选择,因为它允许线程优雅地完成其工作
Concurrency Thread Group提供了更好的用户行为模拟,因为它使您可以更轻松地控制测试的时间,并创建替换线程以防线程在过程中完成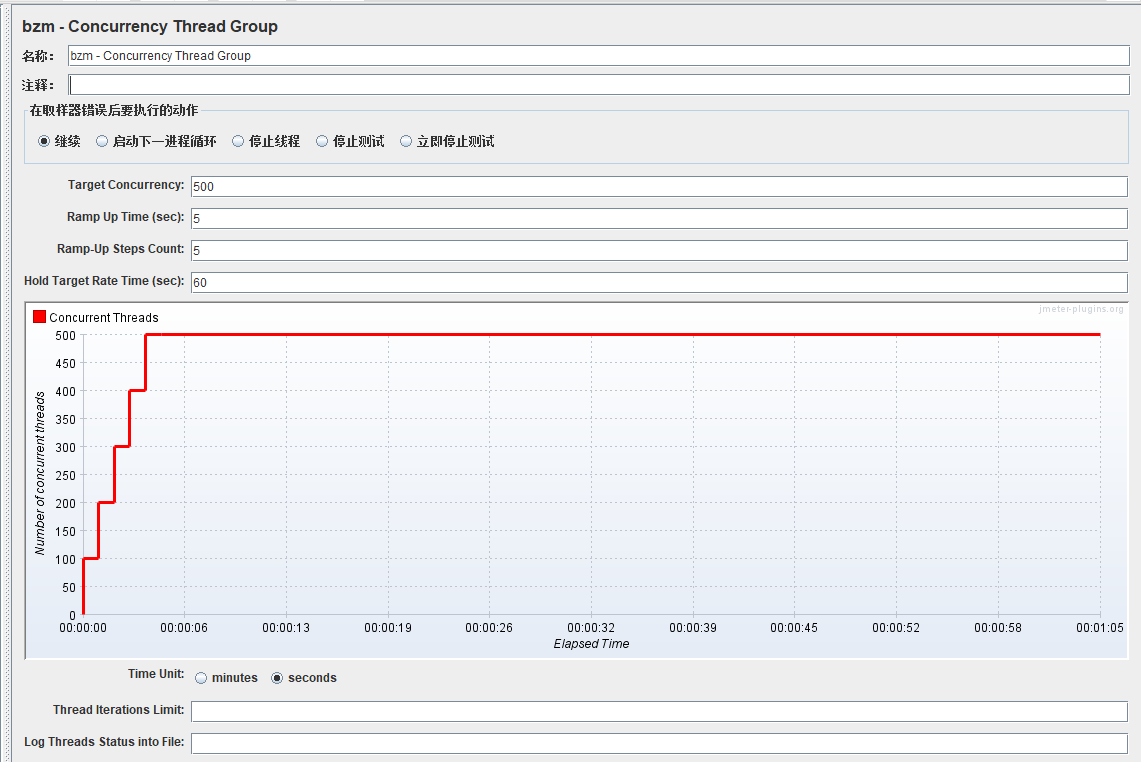
- Target Concurrency:目标并发(线程数)
- Ramp Up Time:启动时间;若设置 1 min,则目标线程在1 imn内全部启动
- Ramp-Up Steps Count:阶梯次数;若设置 6 ,则目标线程在 1min 内分六次阶梯加压(启动线程);每次启动的线程数 = 目标线程数 / 阶梯次数 = 60 / 6 = 10
- Hold Target Rate Time:持续负载运行时间;若设置 2 ,则启动完所有线程后,持续负载运行 2 min,然后再结束
- Time Unit:时间单位(分钟或者秒)
- Thread Iterations Limit:线程迭代次数限制(循环次数);默认为空,理解成永远,如果运行时间到达Ramp Up Time + Hold Target Rate Time,则停止运行线程【不建议设置该值】
- Log Threads Status into File:将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件);
截图的场景解释:设置目标并发是500,5秒内启动,在这5秒内启动5次,所以每一次启动100个线程。到达500个线程后,再运行60秒,最后释放
特别注意点:
- Target Concurrency只是个期望值,实际不一定可以达到这个并发数,得看上面的配置【电脑性能、网络、内存、CPU等因素都会影响最终并发线程数】
- Jmeter会根据Target Concurrency的值和当前处于活动状态的线程数来判断当前并发线程数是否达到了Target Concurrency;若没有,则会不断启动线程,尽力让并发线程数达到Target Concurrency的值
-
持续负载运行结束后,所有线程瞬时释放
添加线程组----Ultimate Thread Group:逐渐梯度加压及阶梯减压
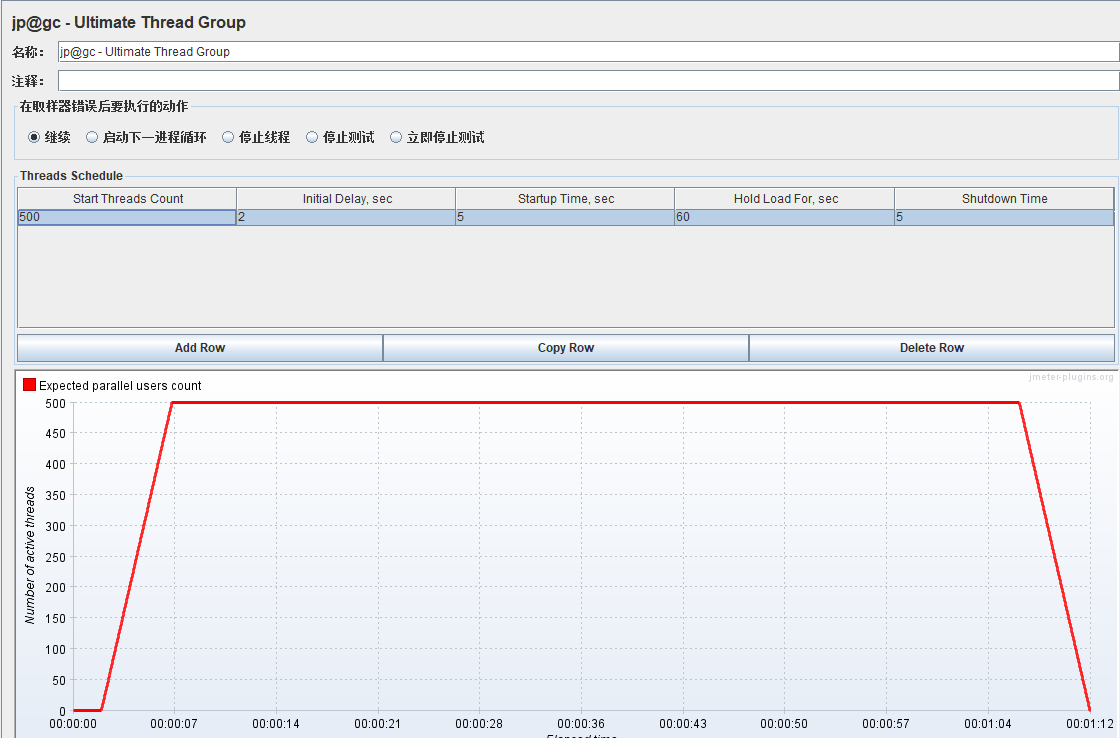
Start Threads Count:启动多少线程
Initial Delay,sec:延迟多少秒开始启动线程
Startup Time,sec:启用{Start Threads Count} 个线程花费多少秒
Hold Load For,sec:线程全部启动完成后再持续运行多少秒,在此期间,每个线程请求完一遍后会再次发起相同的请求,若有思考时间,则会间隔设定的思考时间后再发起
Shutdown Time:在多少秒内将 {Start Threads Count} 个线程全部停掉
关注点是阶梯式并发线程
截图场景解释:延迟2秒启动,然后5秒内启动500个线程,持续运行60秒后,5秒内释放进程
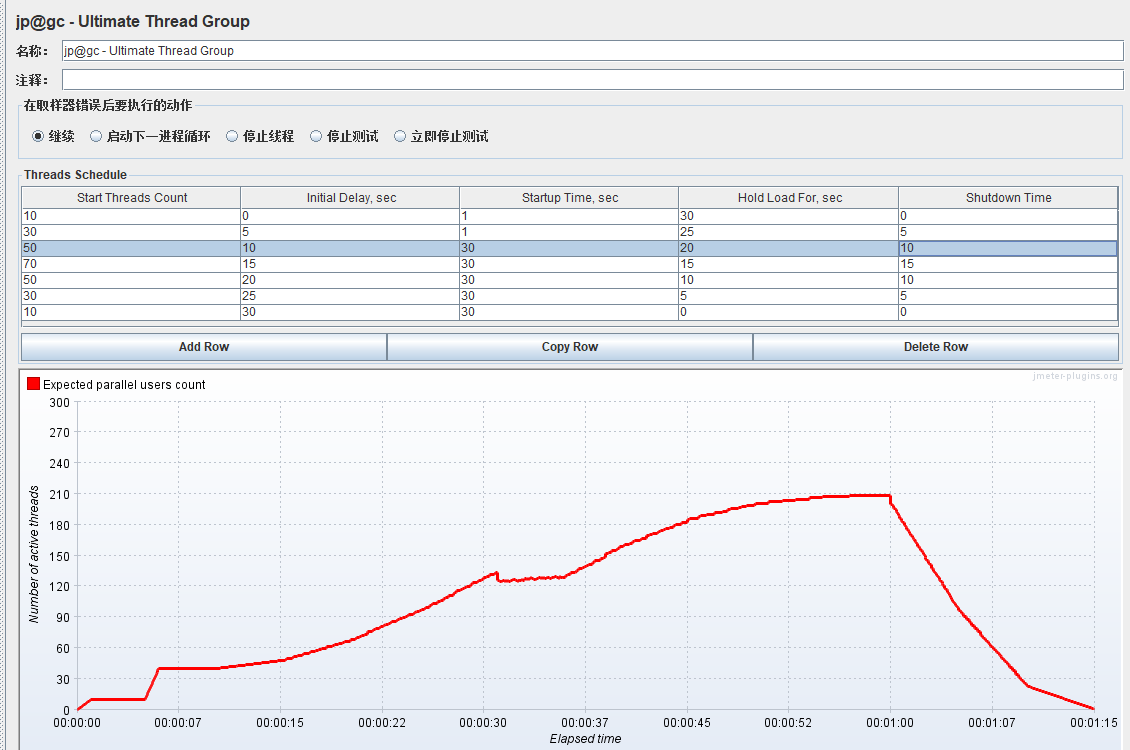
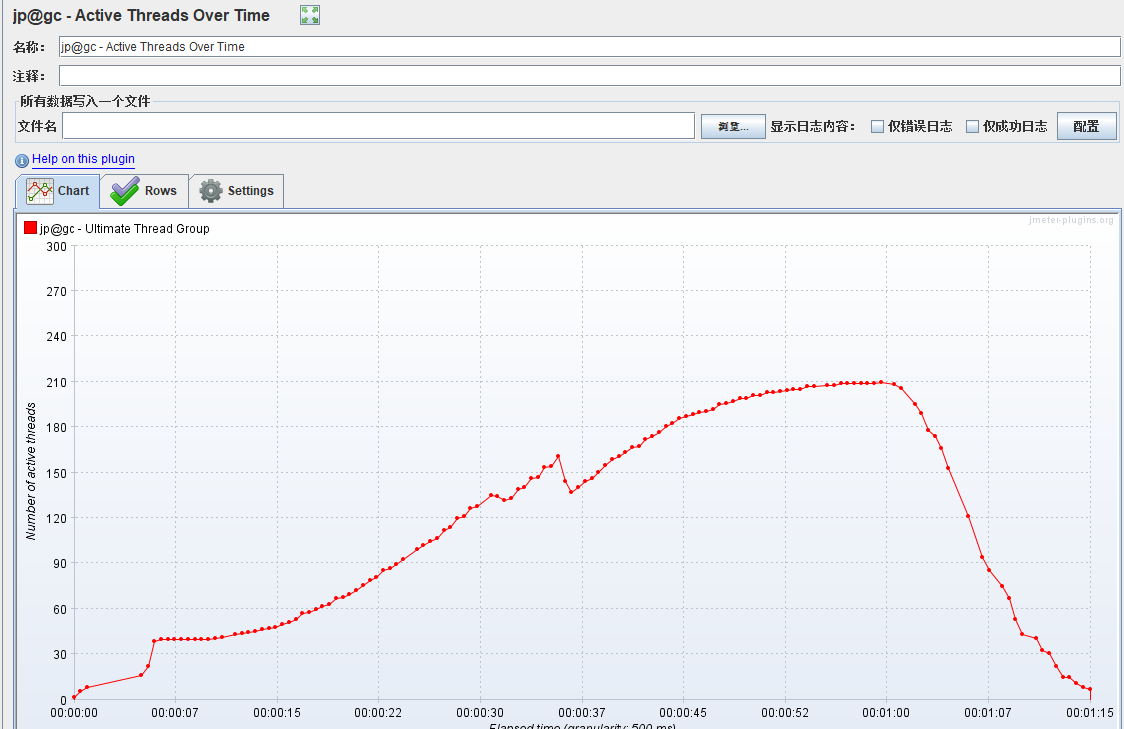
此时,运行后为了确保线程组的变化运行轨迹,添加一个Active Threads Over Time用来查看随时间变化的活动线程:(添加路径:线程组添加监听器jp@gc - Active Threads Over Time)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号