Jmeter测试报告图表说明
测试报告概述:
1.测试报告基本信息

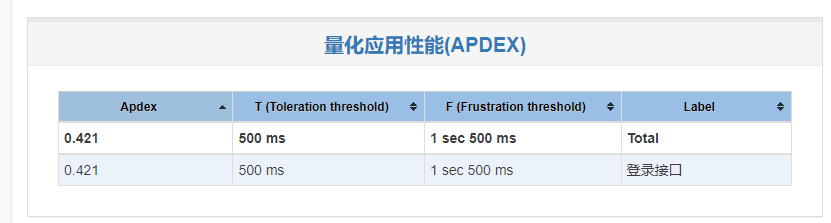
2.APDEX(Application Performance Index):应用程序性能满意度的标准,范围在 0-1之间,1表示达到所有用户均满意。
Apdex(Application Performance Index)是由Apdex Alliance联盟研究的一个开放的,用于衡量用户对应用性能满意度的量化标准。它是一个评分标准,范围在0-1之间(0代表没有用户满意,1代表所有用户满意),它为应用开发者提供了一个明确的衡量用户幸福和满意度的参考。
简单的说,是将一定时间段内收集的数据,根据应用的响应能力,转换成一个指数。根据Apdex评分规则,应用的响应能力可以分为3种:
满意:这代表响应时间少于时间值(T秒),说明用户很满意,可以充分的使用使用。
容忍:这代表响应时间大于T(精确的说,是在T~4T之间),用户感觉到性能不佳,但是还可以继续使用,说明这个响应时间是用户可以容忍的。
失望:这代表响应时间超过4T,并不可接受,用户可能因此放弃继续使用,说明用户很失望。
应用的拥有者可以灵活定义T值。
Apdex评分公式:
Apdex 指数 =( 满意数量 + 0.5 * 可容忍数量 ) / 总样本数
0 代表没有满意用户,1则代表所有用户都满意。
总体来说,Apdex评分是一个衡量服务级别和用户满意度的重要标准,侧面衡量了企业业务的增长性。此外,这些值更容易解读,不像传统的平均响应时间和吞吐量的值,它们不能精确的解释执行缓慢的事务以及对用户满意度的影响。
JMeter在bin目录reportgenerator.properties文件保存了所有关于图形化HTML报告生成模块的默认配置:

jmeter.reportgenerator.apdex_satisfied_threshold:定义Apdex评估中满意的阈值(单位ms)500ms
jmeter.reportgenerator.apdex_tolerated_threshold: 定义Apdex评估中可容忍的阈值1500ms
jmeter.reportgenerator.apdex_per_transaction基于正则表达式或sample名来定制每一个Transaction的APDEX阀值,如上图samples12
Apdext = (Satisfied Count + Tolerating Count / 2) / Total Samples
执行完后生成如下报告。
Apdex评分示例:
在2分钟的时间内,主机将处理200个请求。Apdex阈值T = 0.5秒(500毫秒)。该值是任意的,由用户选择。
500毫秒内处理了170个请求,因此被分类为“满意”。
在500毫秒至2秒(2000毫秒)之间处理了20个请求,因此将其分类为允许。
其余10个未正确处理或花费了超过2秒的时间,因此将其归类为“沮丧”。
得到的Apdex的得分是0.9: (170 + (20/2))/200 = 0.9。
3.性能摘要:请求成功和失败的占比

4.统计,类似于聚合报告。统计表在一个表中提供每个事务的所有指标的摘要,包括3个可配置的百分位数。Statistics: 数据分析,基本将 Summary Report 和 Aggrerate Report 的结果合并。和聚合报告差不多。

TPS计算方法:
1、普通计算方法
计算公式:TPS= 总请求数 / 总时间
按照需求所示,在2019年第32周,有4.13万的浏览量,那么总请求数,我们可以认为估算为4.13万(1次浏览都至少对应1个请求)
总请求数 = 4.13 万请求数 = 41300 请求数
总时间:由于不知道每个请求的具体时间,我们按照普通方法,我们可以按照一周的时间进行计算,总时间 = 1天 = 1 * 24 小时 = 24 * 3600 秒
套入公式可得:TPS = 41300请求数/24*3600秒 = 0.48请求数/秒
结论:按照普通计算方法,我们在测试环境对相同的系统进行性能测试时,每秒能够发送0.48请求就可以满足线上的需要
2、二八原则计算方法
二八原则就是指80%的请求在20%的时间内完成
计算公式 : TPS = 总请求数 80% / (总时间20%)
**按照公式进行计算:TPS = 41300 * 0.8请求数 / 24*3600*0.2秒 = 1.91 请求数/秒
**结论:**按照二八原则计算,在测试环境我们的TPS只要能达到1.91请求数每秒就能满足线上需要。二八原则的估算结果会比平均值的计算方法更能满足用户需求。
3、按照业务数据进行计算
计算模拟用户正常业务操作(稳定性测试)的并发量:
根据这些数据统计图,可以得出结论:
大部分订单在8点-24点之间,因此系统的有效工作时长为16个小时
从订单数量统计,8-24点之间的订单占一天总订单的98%左右(40474个)
结合二八原则计算公式 : TPS = 总请求数 80% / (总时间20%)
需要在测试环境模拟用户正常业务操作(稳定性测试)的并发量为:TPS = 40474 * 0.8请求数 / 16*3600*0.2秒 = 2.81 请求数/秒
计算模拟用户峰值业务操作(压力测试)的并发量:
根据这些数据统计图,可以得出结论:
订单最高峰在在21点-22点之间,一小时的订单总数大约为8853个
计算压力测试的并发数:TPS = 峰值请求数/峰值时间 * 系数
需要在测试环境模拟用户峰值业务操作(压力测试)的并发量为:
TPS = 8853 请求数 / 3600秒 * 3(系数) = 7.38 请求数/秒
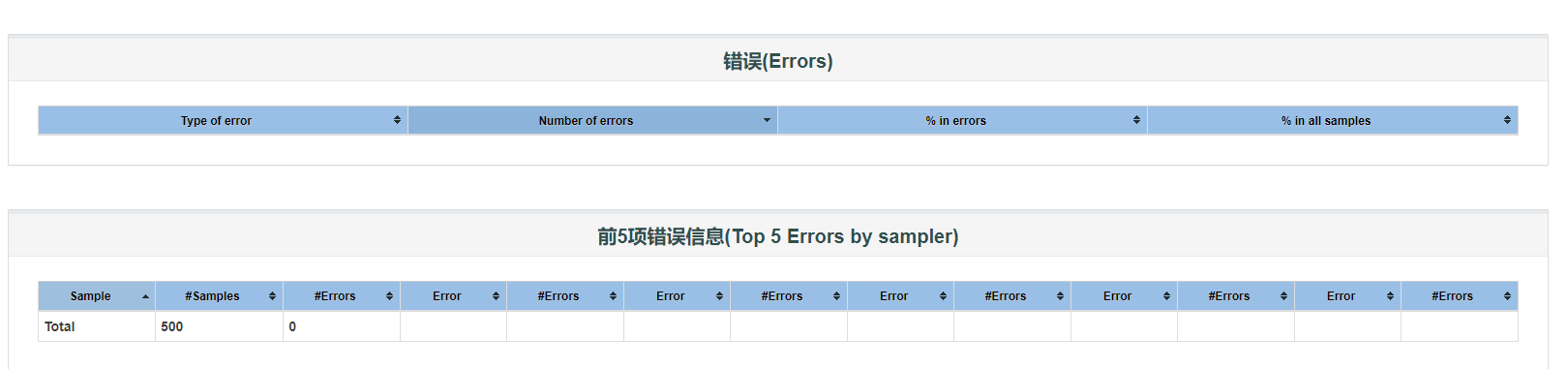
5.错误相关。
错误表提供了所有错误及其在总请求中所占比例的摘要。Errors: 错误情况,依据不同的错误类型,将所有错误结果展示。
前5个错误(按Sampler列出)表为每个Sampler(默认情况下不包括Transaction Controller)提供前5个错误:Top 5 Errors by sampler:Top5错误信息采样
6.charts:对测试报告的图表进行说明:
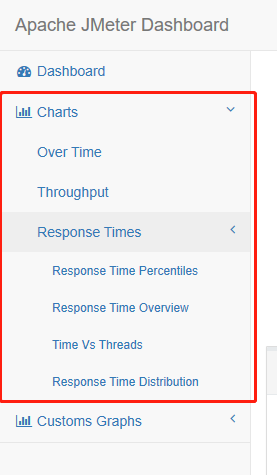
over time 类:
一共有 6 个图表:
- Response times Over Time
- Response times Percentiles Over Time
- Active Threads Over Time
- Bytes throughput Over Time
- Latencies Over Time
- Connect Time Over Time
对应Jmeter监听器的元件:
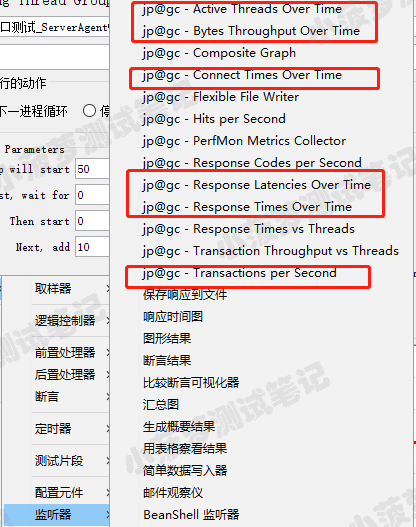
1.response times over time:该图表展示的主要是每个样本的平均响应时间,单位为ms;X轴表示的是系统运行的时刻,Y轴表示的是响应时间,F(X,Y)表示系统随着时间的推移,系统的响应时间的变化,可以看出响应时间稳定性。
- 脚本运行期间,不同事务(请求)的响应时间变化趋势图
- 包括事务控制器样本结果
- 重点:可以根据响应时间和变化和TPS以及模拟的并发数变化,判断性能拐点的范围
- 一条线代表一个事务(请求)
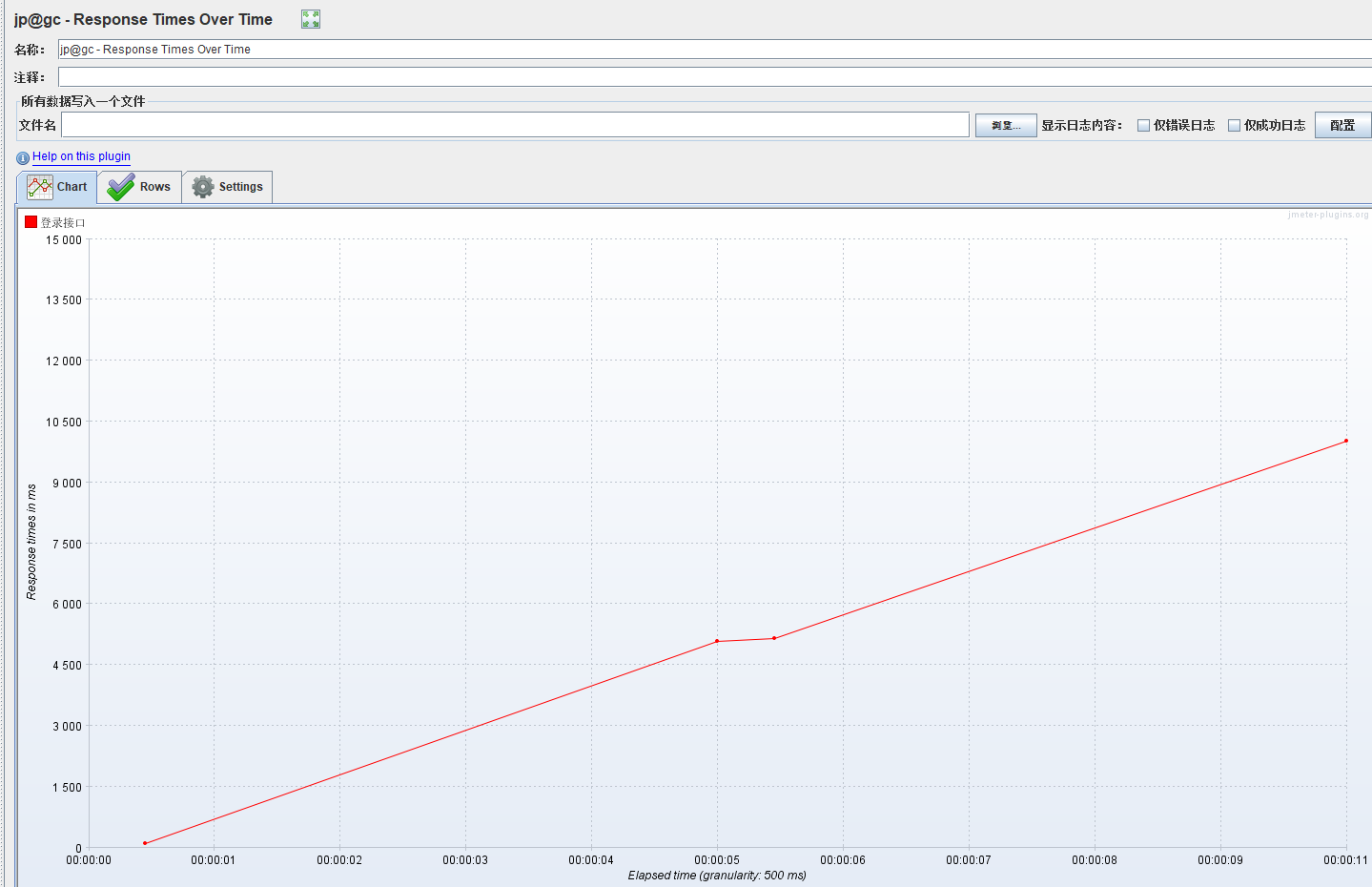
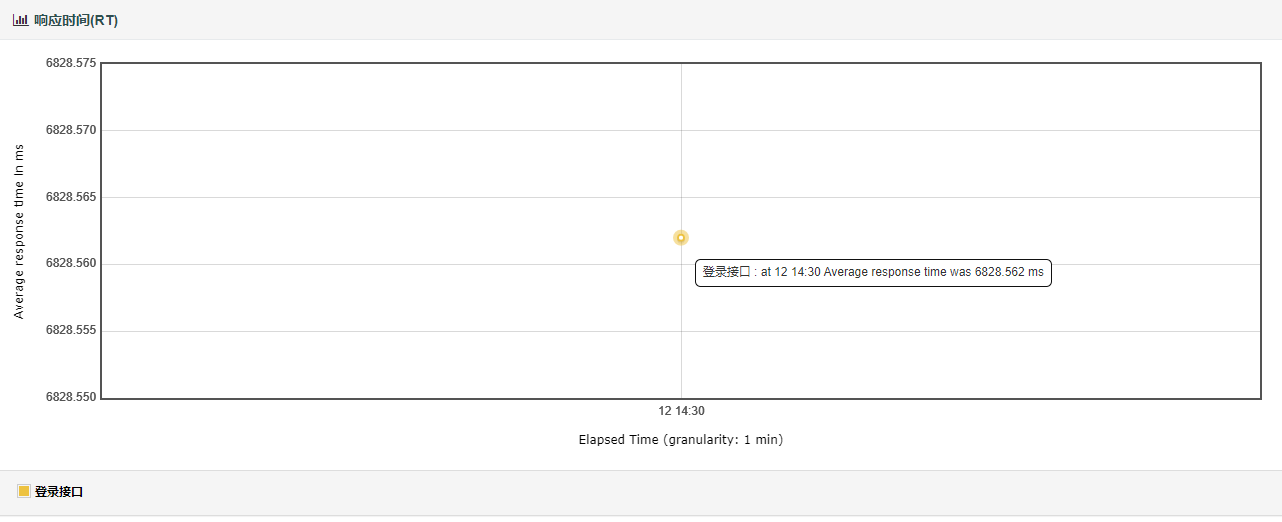
分析:登录这个请求的平均时间是6.28秒
2.response time percentiles over time(successful response):该图表展示的主要是不同百分比对应的响应时间值。(对应response time percentiles)
其中x轴表示百分比,y轴表示响应时间值。整个场景中,任意一点(p,value)表示的意义为:p百分比时的响应时间值是多少。但是自动生成的报告中,只展示了90%,95%,99%,最大和最小百分比的值。下图是两者的对比。
- 脚本运行期间,成功的请求的响应时间百分比分布图
- 可理解为聚合报告对应的指标(图二)
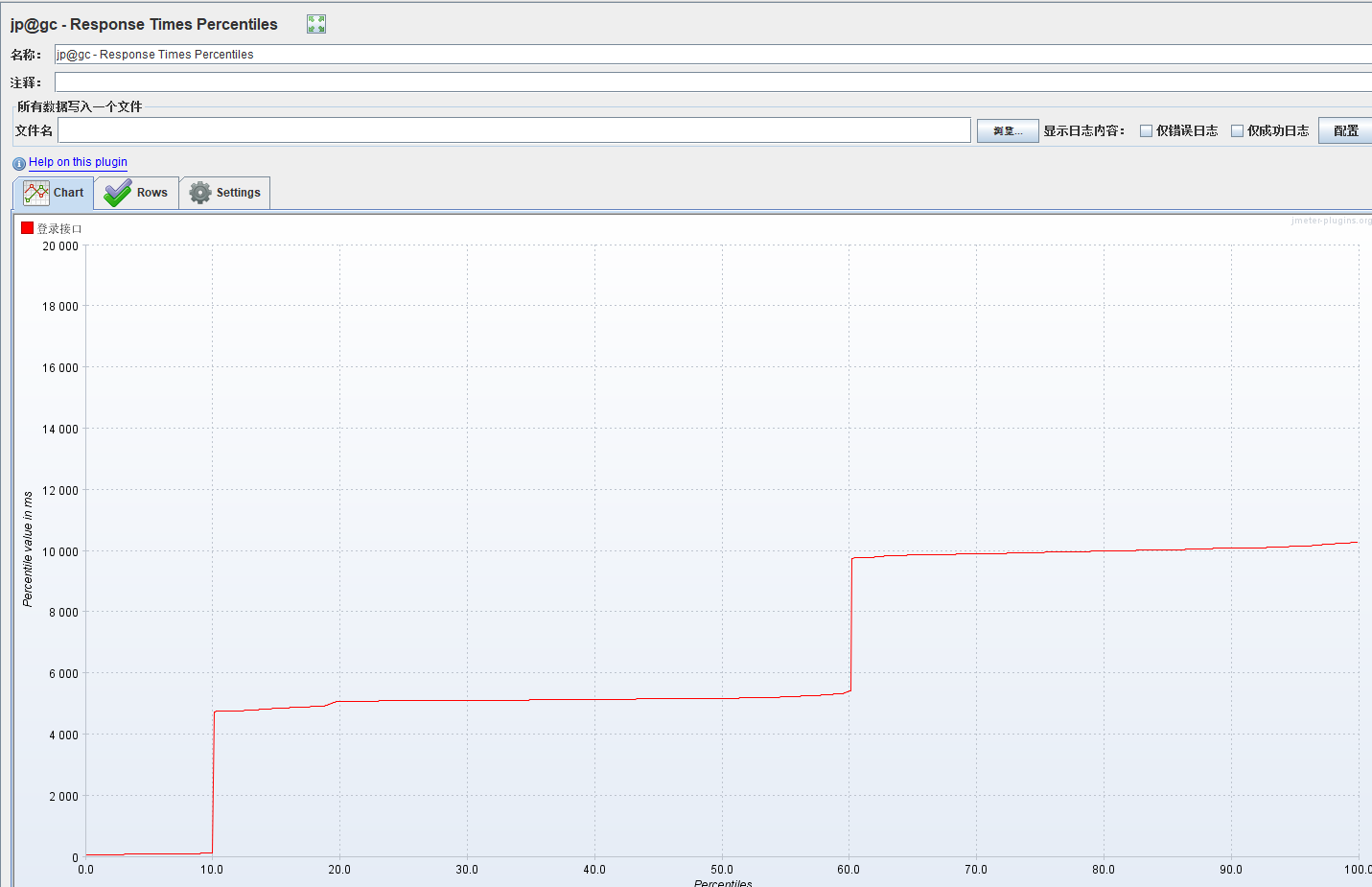
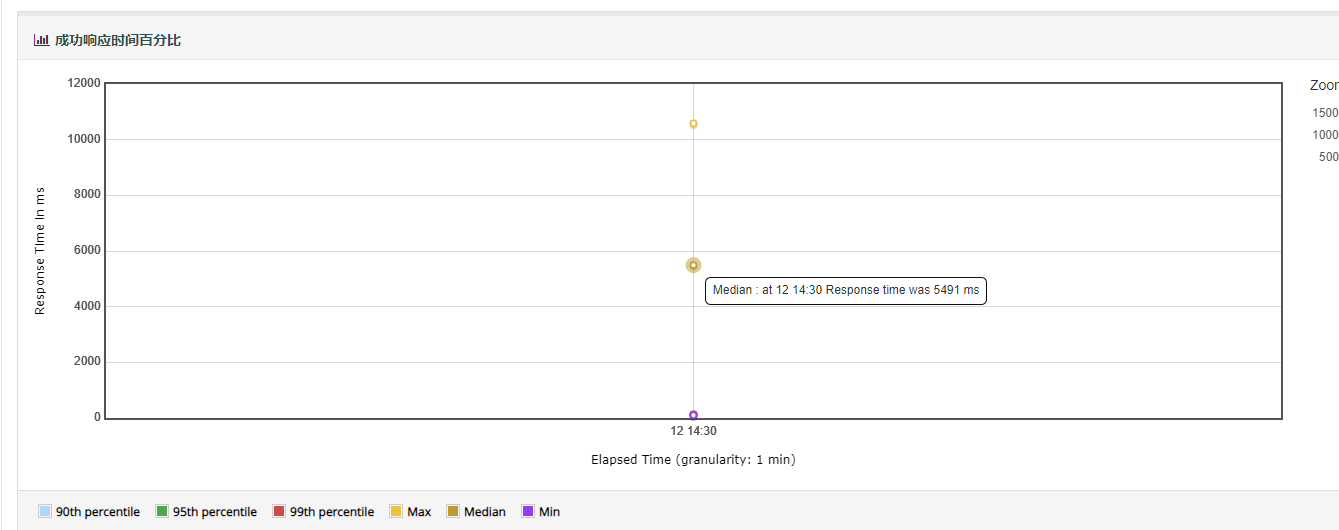
3.active threads over time:主要展示的是在执行测试的过程中,随时间变化,每个每个线程组中共有多少个活跃的线程数。横坐标是毫秒,纵坐标是活动线程数,也就是并发数。
线程数就是我们设置是虚拟用户数,可以理解为1个线程,就是一个虚拟用户。
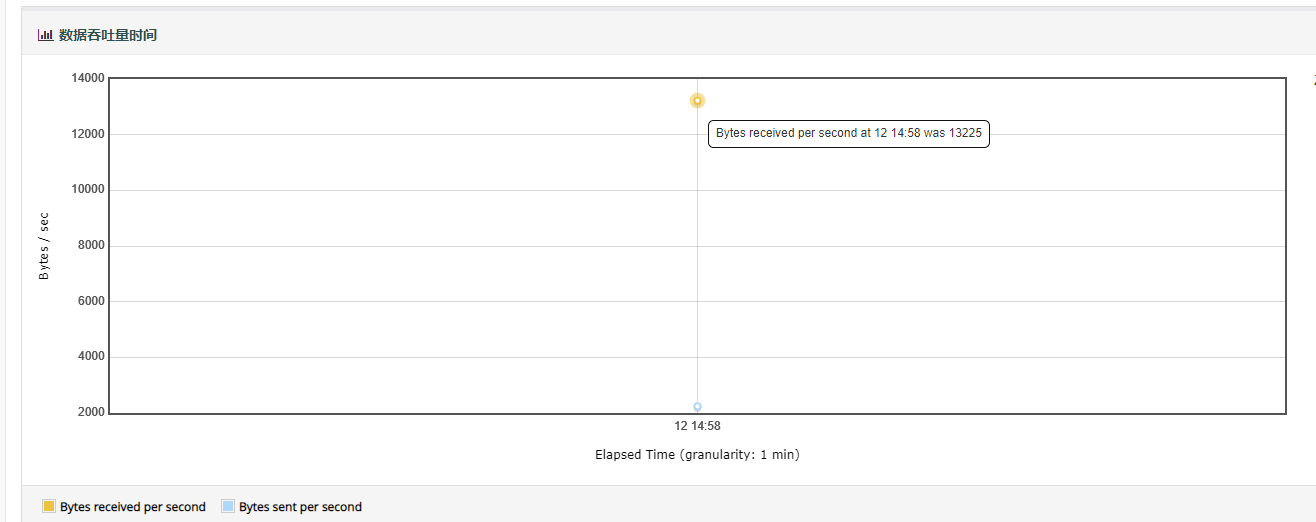
4.bytes throughput over time:主要展示的是在负载测试期间,每秒接收和发送的字节数。
- 脚本运行期间,吞吐率变化趋势图
- 在容量规划、可用性测试和大文件上传下载场景中,吞吐量是很重要的一个监控和分析指标
- 会忽略事务控制器样本结果
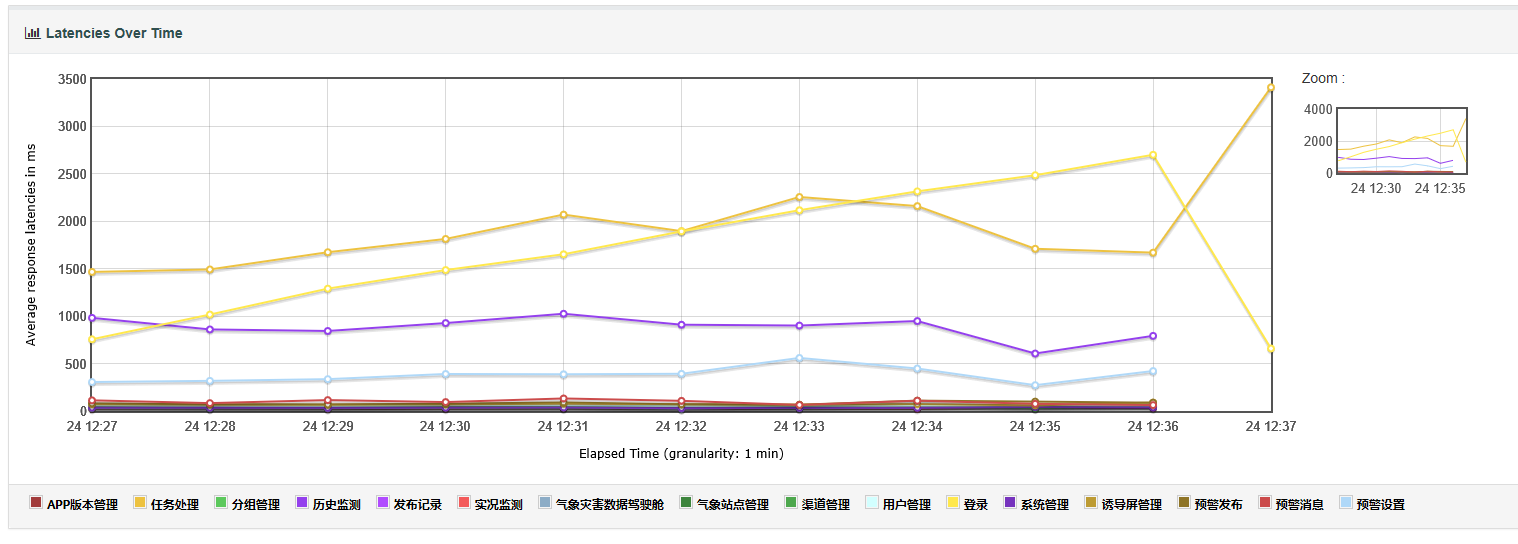
5.latencies over time:主要展示的是负载测试期间的响应延迟时间,延迟时间指的是请求结束到服务器开始响应的这段时间。随着时间的推移系统的响应等待时间的变化,也是系统随着时间推移,系统效率的变化。
- 脚本运行期间,发送一个完整的请求所需时间的变化趋势图
- 可理解理解成:从发送请求到收到第一个响应所花费的时间
- 包括事务控制器样本结果

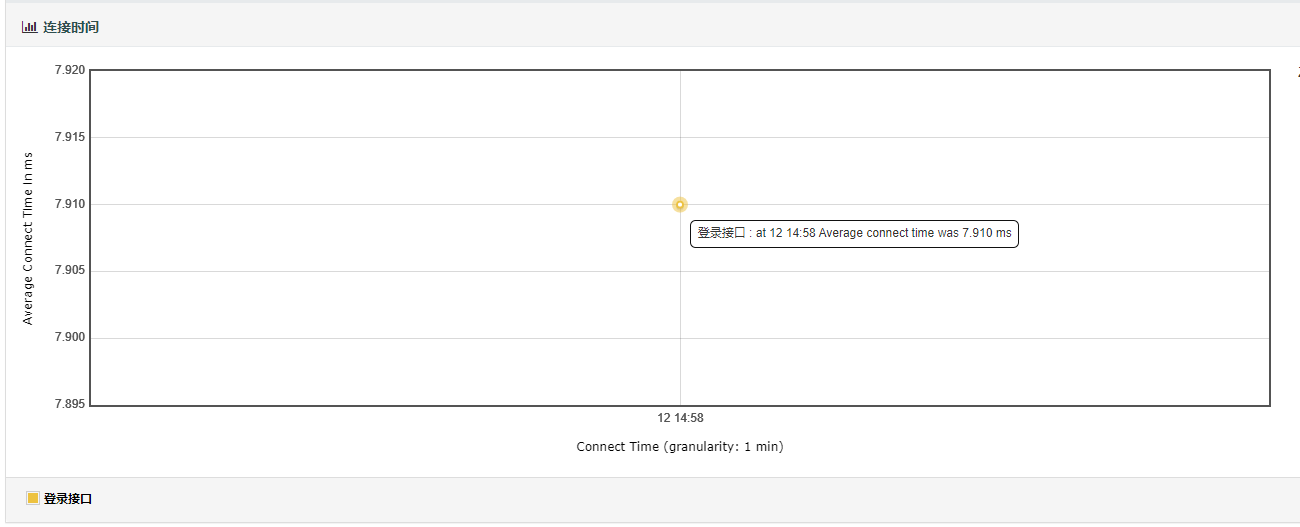
6.connect time over time:主要展示的是在负载测试期间发送请求后与服务器建立连接的平均时间。
- 脚本运行期间,事务(请求)建立连接所花费的平均时间变化趋势图
- 包括 SSL 三次握手的时间
- 当出现链 Connection Time Out 的错误时,Connect Time 就会等于链接超时时间
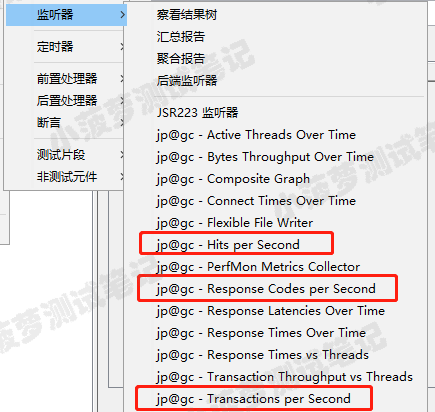
throughput类:
一共有 6 个图表:
- Codes Per Second
- Transactions Per Second
- Total Transactions Per Second
- Response Time Vs Request
- Latency Vs Request
对应的Jmeter监听元件:
1.hits per second:图表展示的是测试期间每秒产生的请求服务器的数量;动态监听单位时间的点击率,也就是触发的请求数。其中横坐标是运行时间,纵坐标是HPS值。
是指在一秒钟的时间内用户对Web页面的链接、提交按钮等点击总和。它一般和TPS成正比关系,是B/S系统中非常重要的性能指标之一。在接口测试中,HPS和TPS基本一致。

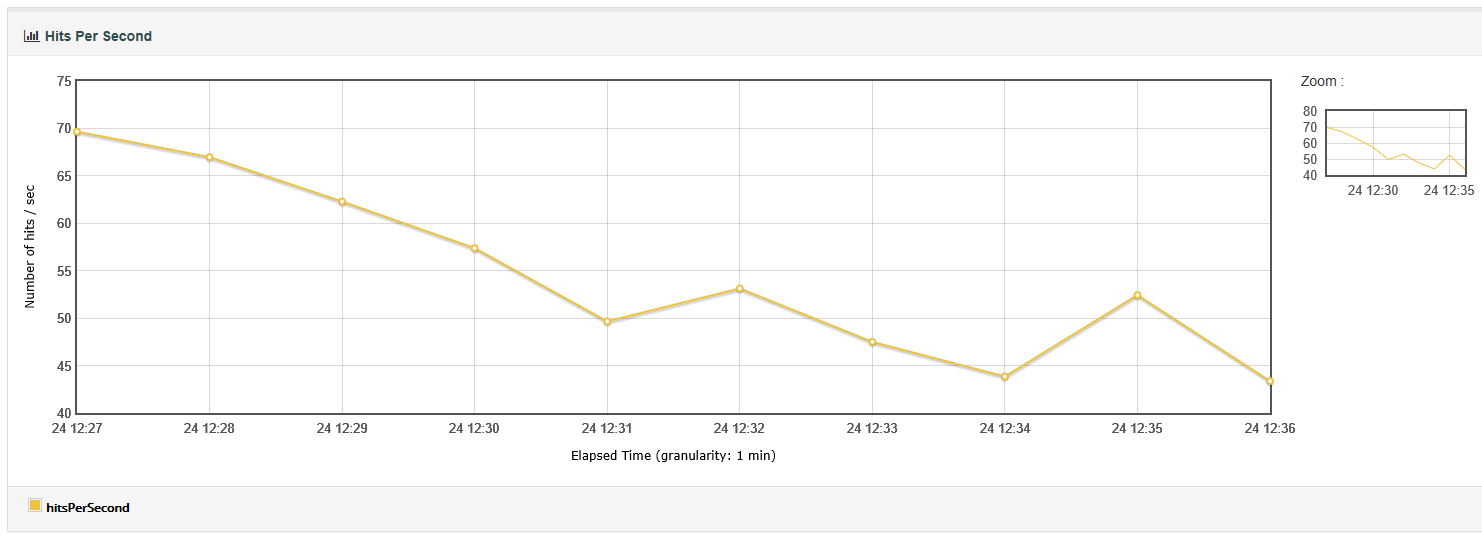
分析:如果点击率波动较大,且不能持续上升。就说明性能很不稳定。
2.codes per second: 图表展示的是测试期间请求每秒返回的响应code的数量。这里说的code,是指请求的status,如200,404,504,502等。表明Jmeter测试期间,
随着时间的推移返回的响应码,从中我们可看到测试期间在哪个时间段内出现了错误。就可以分析在该时间内系统的什么环境因素,导致的错误。

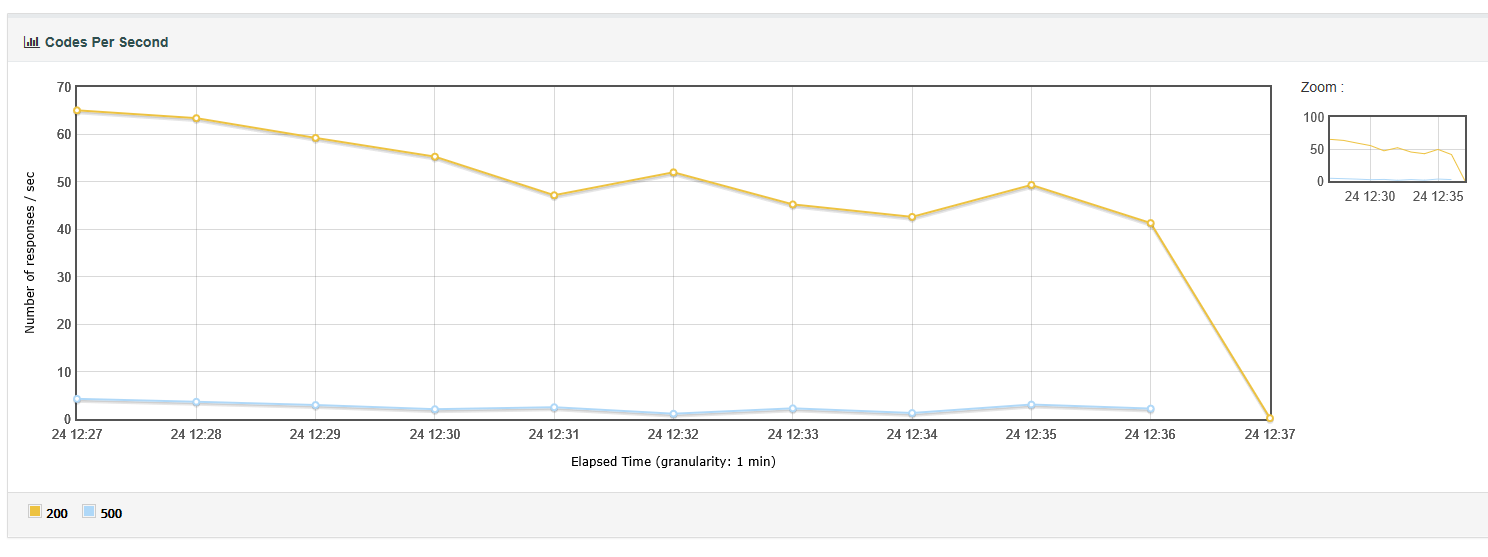
分析:从中我们可看到测试期间在哪个时间段内出现了错误。就可以分析在该时间内系统的什么环境因素,导致的错误。
3.transactions per second:图表展示的是每秒内完成的业务数量(包括成功和失败的)。(最重要)
每秒事务数,在性能测试中非常重要的一个指标,我们在聚合报告里面能看到最后的测试结果TPS值。
TPS(Transaction per Second)定义:
tps是Transaction per Second的缩写,也就是事物数/秒。它是软件测试结果的测量单位,一个事物是指一个客户机向服务器发送请求饭后服务器做出反应的过程。
客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用时间和完成的事物数,最终利用这些信息来估计得分。
TPS(Transaction per Second)作用:
反映了系统在同一时间内处理业务的最大能力,这个数据越高,说明处理能力越强,描述(看到系统的TPS随着时间的变化逐渐变大,而在不到多少分钟的时候系统
每秒可以处理多少个事物。这里的最高值并不一定代表系统的最大处理能力,TPS会受到负载的影响,也会随着负载增加而逐渐增加,当系统进入繁忙期后,TPS会有所下降。)
而在几分钟以后开始出现少量的失败事物)
TPS(Transaction per Second)局限性:
1、tps是从客户端角度审视服务器处理能力,并不是说TPS可以达到什么程度就能支持多少并发(例如:一个业务100个交易,另一个业务10个交易)。
2、TPS = 脚本运行期间所有事物总数 / 脚本运行时长,如果使用集合点策略,在脚本执行前的等待时间过程中,服务器没有处理事务,那么这个时候的TPS和理想中的结果不一致。
3、限制TPS的原因:服务器本身性能、代码结构、客户端施加的压力以及网卡等。
TPS(Transaction per Second)与响应时间的关系:
1、TPS和响应时间在理想状态下的额定值。如果20个入口,并发数只有10的时候,TPS就是10,而响应时间始终都是1,说明并发不够,需要增加并发数达到TPS的峰值。
2、如果增加到100并发,则造成了线程等待,引起平均响应时间从 1 秒变成 3 秒,TPS也从20下降到9;TPS和响应时间都是单独计算出来的,两者不是互相计算出来的。
3、响应时间和TPS在宏观上是反比的关系,但是两者之间没有直接关系。
TPS(Transaction per Second)在性能测试中的作用:
1、一个系统的吞吐量(承压能力)与request 对CPU的消耗、外部接口、IO等紧密关联。单个request对CPU消耗越高,外部系统接口、IO营销速度越慢,系统吞吐能力越低,反之越高。
2、系统吞吐量几个重要参数:TPS、并发数、响应时间(TPS = 并发数 / 平均响应时间)
3、利用TPS计算系统最高日吞吐量;
4、找出系统最高TPS和日PV,这两个要素有相对比较稳定的关系。
5、通过压力测试或者经营评估,得出最高TPS,然后跟进1的关系,计算出系统最高日吞吐量。例如:B2B中文和淘宝对客户群不一样,这两个客户群的网络行为不应用,他们之间的TPS
和PV关系比例也不一样。
6、淘宝
A)淘宝的TPS和PV之间关系通常为,最高TPS:PV大约为 1:11*3600(相当于按最高的TPS访问11个小时,这个是商品详情的场景,不同的应用场景会有一些不同)B2B中文站
B)B2B的TPS和PV之间的关系不同的系统不同的应用场景比例变化比较大,粗略估计在1:8个小时左右的关系(09年对offerdateil的流量分析数据)。旺铺和offerdetail这两个比例相差很大,
可能是因为爬虫占得比例比较高的原因导致的。
在淘宝环境下,假设我们压力测试出的TPS为100,那么这个系统的日吞吐量=100*11*3600=396万
这个是在简单(单一url)的情况下,有些页面,一个页面有多个request,系统的实际吞吐量还要小。
TPS(Transaction per Second)与其他性能指标的关系:
TPS和并发虚拟用户数(U_concurrent)、Loadrunner读取的交易响应时间(T_response)之间有以下关系(稳定运行情况下):TPS=U_concurrent / (T_response+T_think)。
TPS(Transaction per Second)总结:
1、利用并发用户数、期望响应时间,可以计算出TPS。
2、TPS只是用来计算的是期望值,性能测试过程中的TPS无法单独作为性能指标。
3、TPS数据方位理论值赢在10-100之间,低于10和高于100都说明系统存在瓶颈点。
4、利用TPS与平均事物响应时间进行对比,可以分析事物数码对执行时间的影响。例:当压力加大,点击率/tps曲线如果变化缓慢或者有平坦趋势,很有可能是服务器开始出现瓶颈。
5、TPS是从客户端角度审视服务器处理能力,不能证明TPS可以达到什么程度就能支持多少并发,两者没有必然联系。
6、TPS会受到负载的影响,也会随着负载的增加而逐渐增加,当系统进入繁忙期后,TPS会有所下降。
- 每秒事务数,即 TPS
- 衡量系统处理能力的重要指标
- 包括事务控制器样本结果
X轴表示访问结束的时刻,Y轴表示访问量,F(X,Y)表示在某个结束时刻,一共有多少的访问量结束访问。
其意义是应用系统每秒钟处理完成的交易数量。一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。依据经验,应用系统的处理能力一般要求在10-100左右。不同应用系统的TPS有着十分大的差别,一般需要通过性能测试进行准确估算。

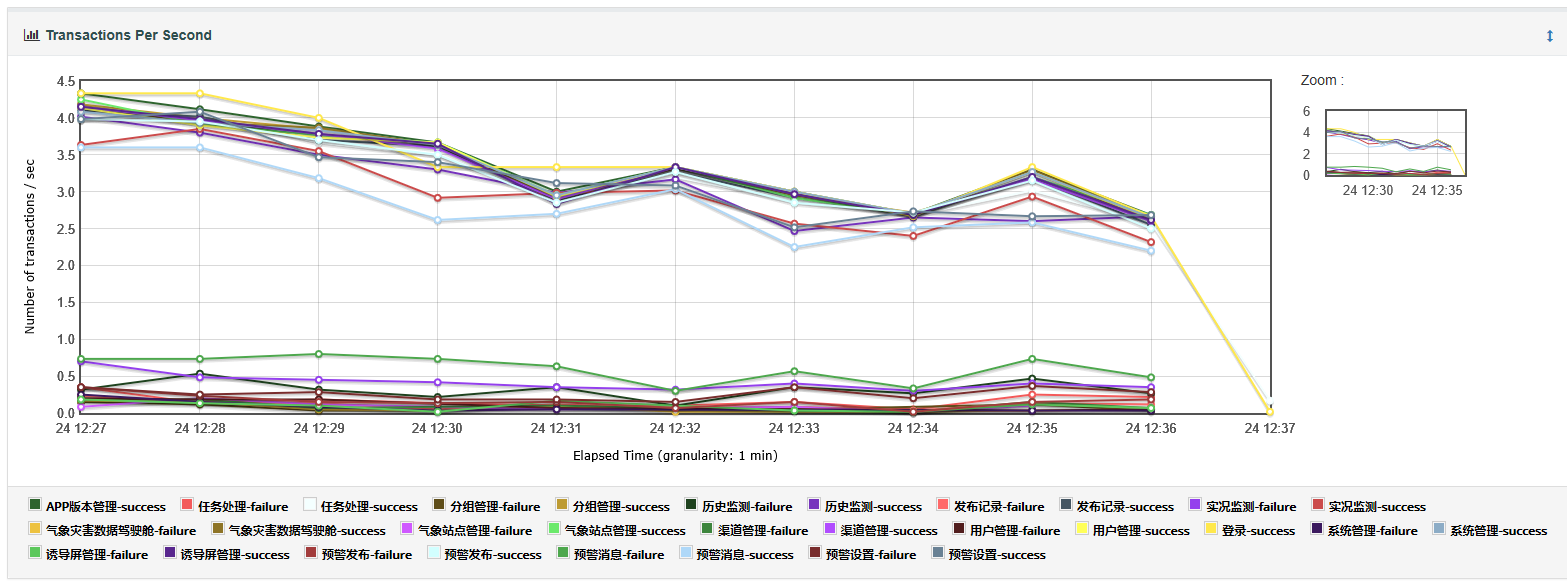
该接口图表分析:最高每秒事务处理数为98,最低事务处理数为10,基本在80-95之间浮动。
指标分析:TPS越高,系统处理能力越强
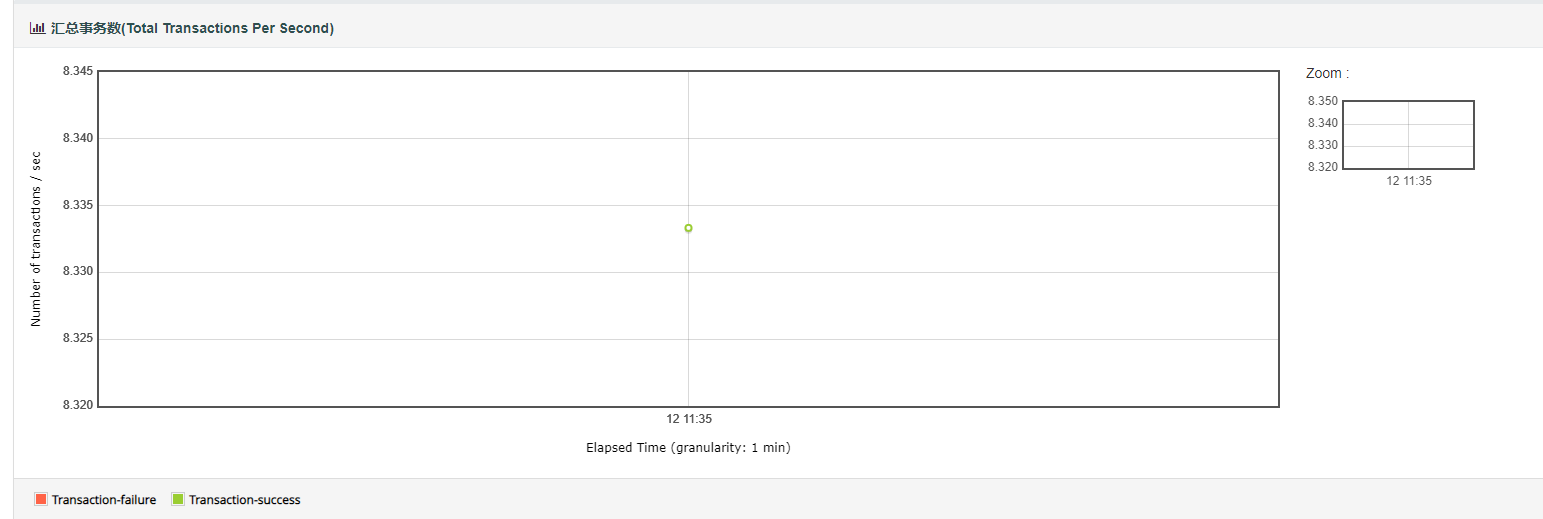
4.Total Transactions Per Second
此表为TPS的汇总所得,可以用于获得多交易脚本的总TPS,但要注意若添加事务控制器则也会增加相应的TPS。
5.response time VS request:图表展示的是不同请求数对应的响应时间值。每秒所有事务量,包含成功和失败的事务。中位响应时间点请求的成功或失败数。即响应时间和请求数对比关系,
如果请求数量太小就只有一些散点。此表能够观察系统响应时间随TPS的改变的离散程度。

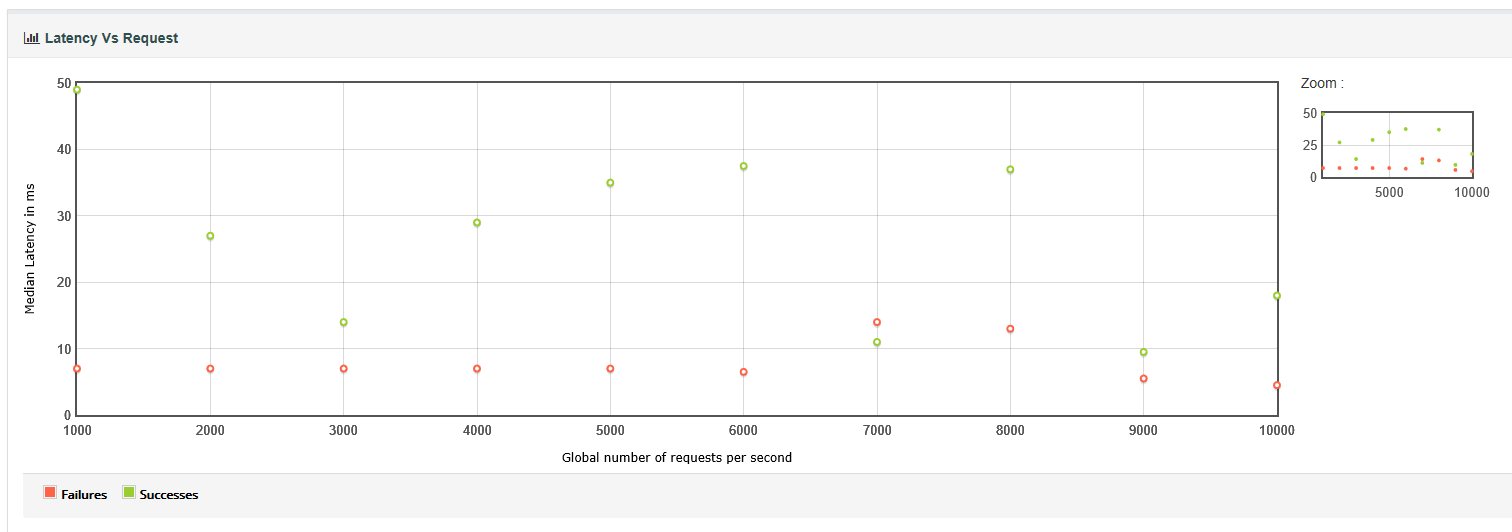
5.latency VS request:图表展示的是不同的请求数对应的响应延时。即完成一个完整的请求所需平均时间与每秒请求数的关系图。响应时间点请求的 成功/失败 数。每秒发送多少个请求时,所对应的平均(中位)响应时间。
response times类:
一共有4个图表:
- Response Time Percentiles
- Response Time Overview
- Time Vs Threads
- Response Time Distribution
1.response Time percentiles:图表展示的是不同的响应时间所对应的占比,图中x轴表示百分比,y轴表示响应时间值,图中任意一点(p,value)表示的意义为:p占比对应的响应时间的值。如50%的请求响应时间为500ms等。
- 响应时间百分比分布图
- 响应时间在某个百分比范围内的请求在所有请求数中所占的比率,相比于平均响应时间,这个值更适合用来衡量系统的稳定性。
-
通过之前压测数据中所有响应时间统计分析所展示的。可以更详细看出自己所需要了解的百分线用户的响应时间。
![]()
![]()
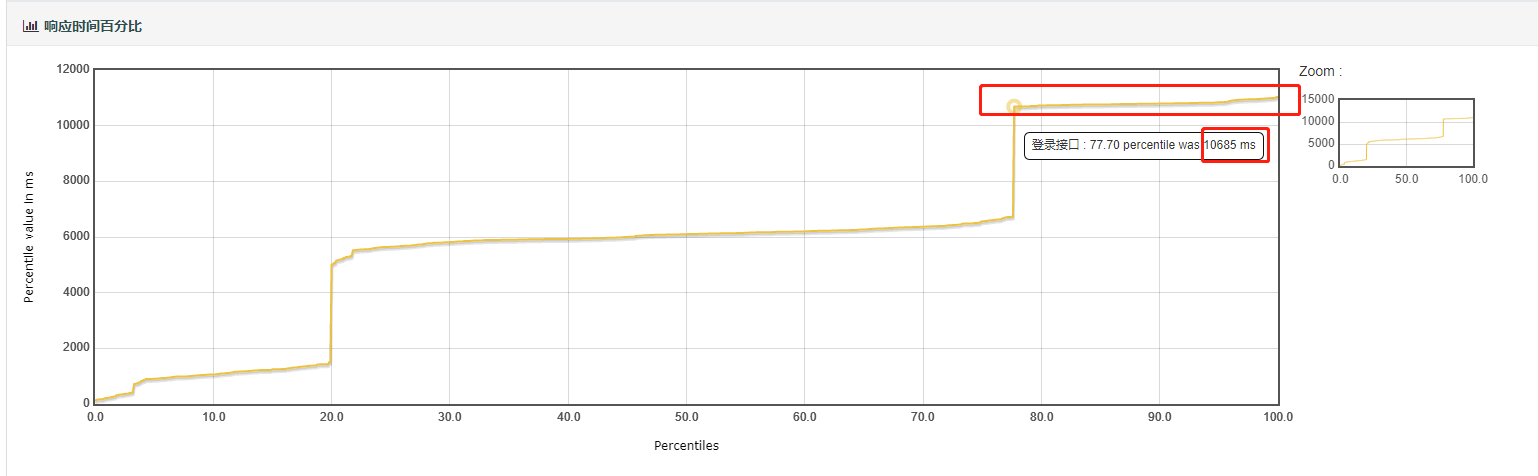
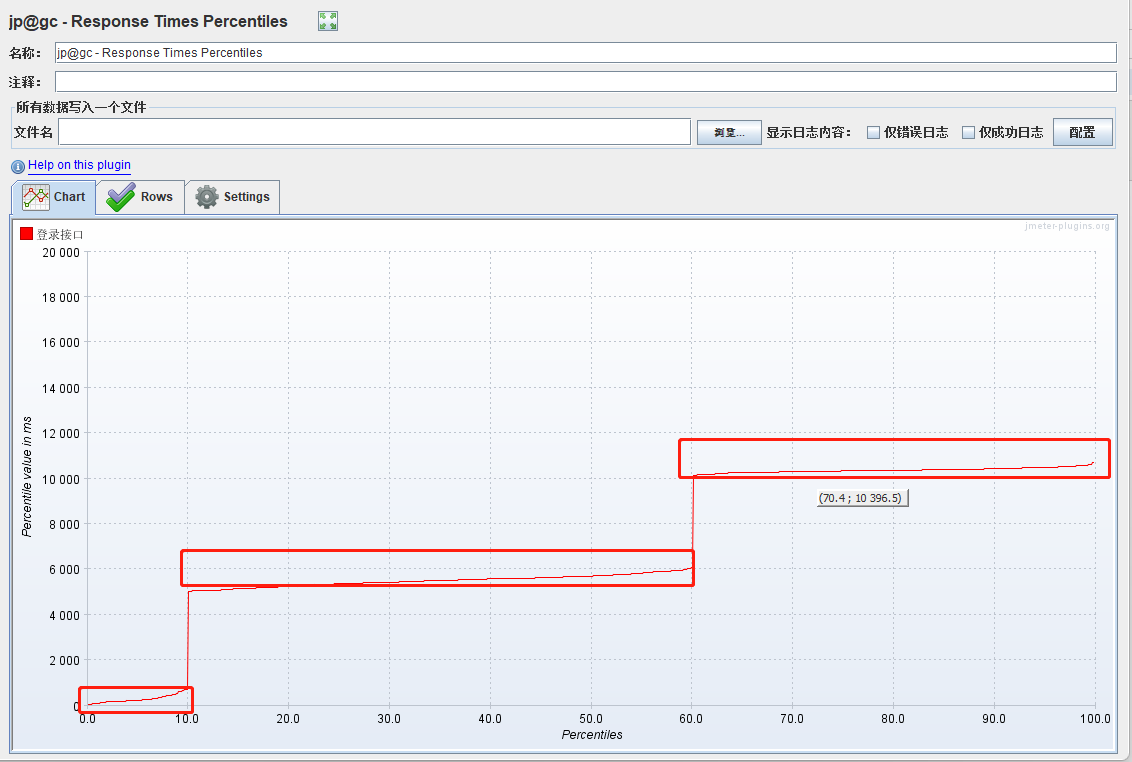
分析:样本是500,一秒启动。响应时间0- 705ms的请求只占10%(50个),5066-6123ms的占50%(250个),10081-10749的占40%(200个)。
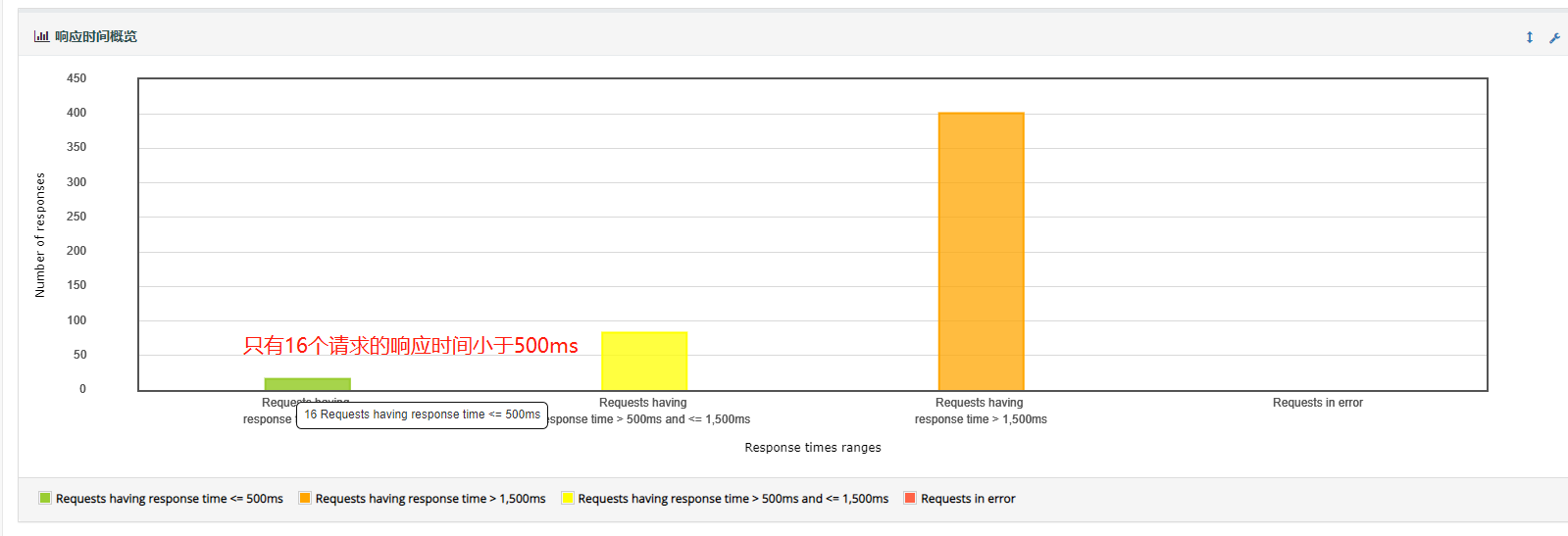
2.response Time overview:图表主要展示了不同请求的响应时间的柱状图。按照不同的响应时间来进行划分。响应时间概述图。显示交易整体分布,横坐标所绘制的区间和我们最开始看到的APDEX应用程序性能指数中划分的区间一致。
- 响应时间分布图
- 展示落在各个平均响应时间区间的请求数情况
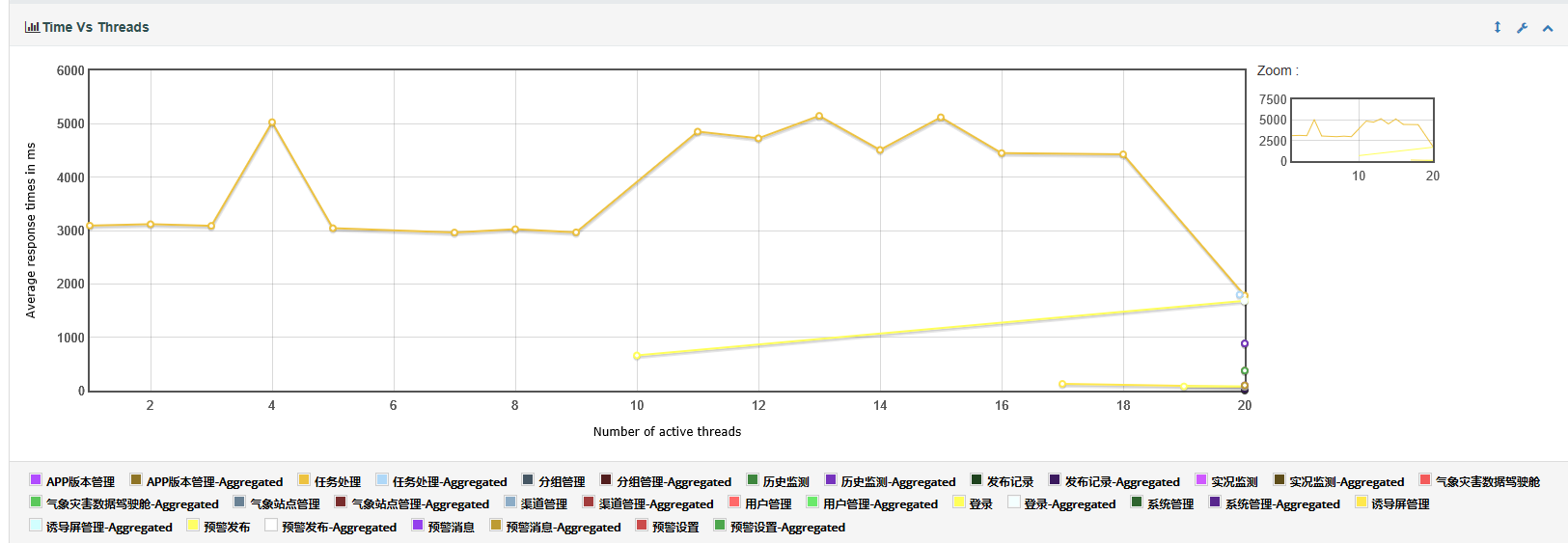
3.time vs threads:图表展示了不同线程数并发时的响应时间的变化趋势。(各个线程平均响应时间,实际中看运行拐点来定为性能瓶颈的参考值)其中横坐标是活动的线程数(也就是并发数),纵坐标是响应时间(单位是毫秒)
-
- 平均响应时间和线程数(并发数)的对应变化曲线
- 可以通过这个对应的变化曲线来作为确定性能拐点的一个参考值
- 平均响应时间和线程数的对应变化曲线。即活跃线程数和响应时间对比关系,这块如果请求数据较少的话就会造成结果不是十分明显
- 响应时间用户数, X轴表示的是活动线程数,也就是并发访问的用户数,Y轴表示的是响应时间,F(X,Y)表示在某种并发量的情况下,系统的响应时间是多少。

4.response Time distribution:图表主要展示响应时间的分布图,x轴表示响应时间,y轴表示响应数。响应时间分布。各交易响应以响应时间为区间的分布图。
- 响应时间分布图
- 不同响应时间区间内,成功响应数是多少
- F(X,Y)表示系统在某种响应时间内的响应次数是多少,如果在响应时间短的地方,响应次数多,说明系统的效率比较高。
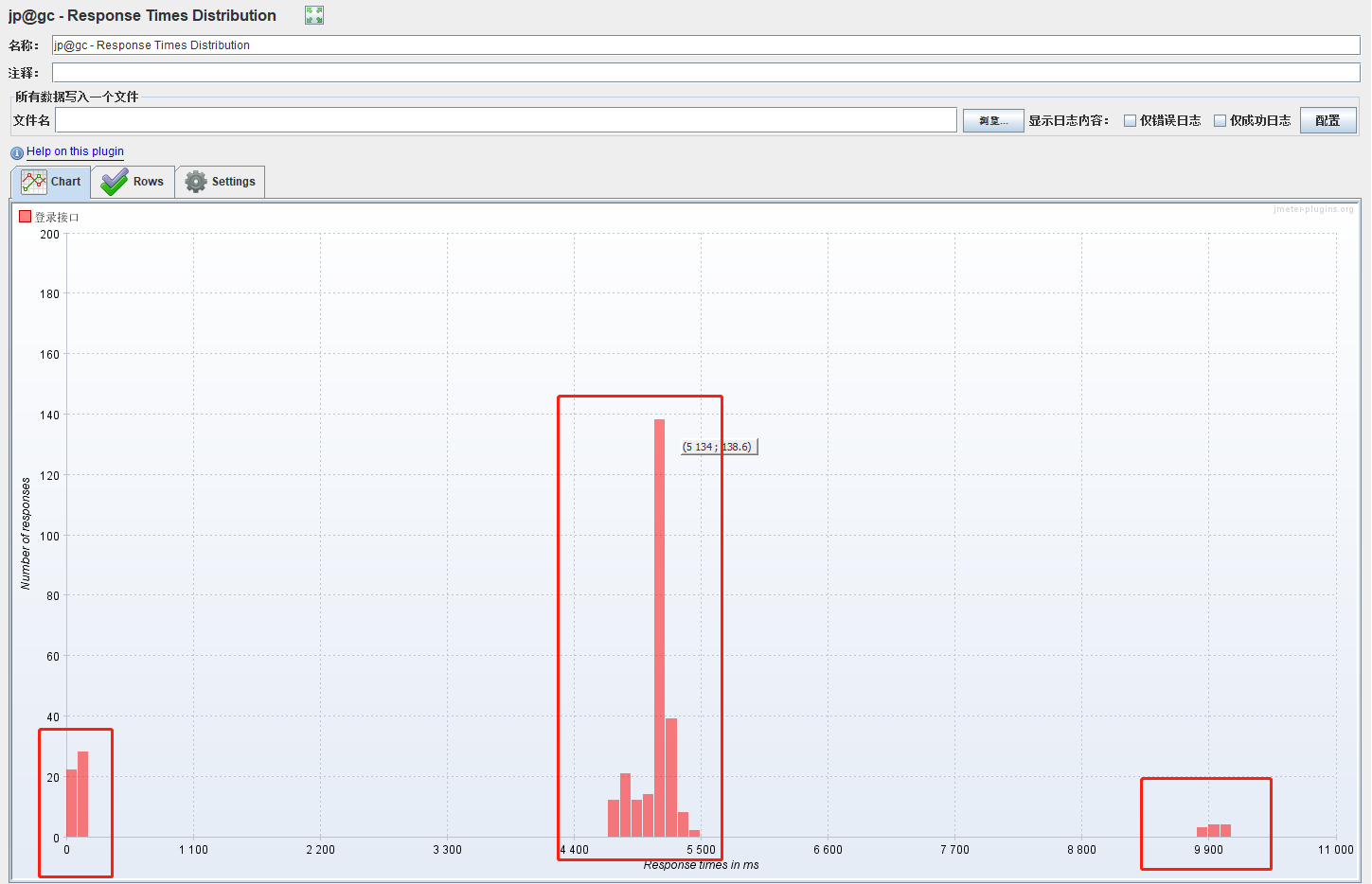
分析:响应时间主要集中在3个区间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号