
分析聚类结果
简单实现了Bavota的模块划分算法。
论文有两篇:
Using structural and semantic measures to improve software modularization
Software remodularization based on structural and semantic metrics
方法是计算一个结合了结构和语义信息的相似度矩阵,根据某个阈值筛选出高相似度的边,最后找出连通分量,视为一个模块。
综合相似度矩阵由结构相似度矩阵和语义相似度矩阵混合而成。权重是一个参数。
下面比较不同设置下聚类结果的变化。
百分位数是指对所有顶点对相似度排序后,按名次百分比取对应位置的阈值。
| 语义信息权重 | 边阈值为0.94百分位数(94%的边被删除) | 边阈值为0.96百分位数(96%的边被删除) | 边阈值为0.96百分位数(96%的边被删除) | 边阈值为0.96百分位数与第n*3大的值之间较大者 |
| 1 |  |  |  |  |
| 0.8 | 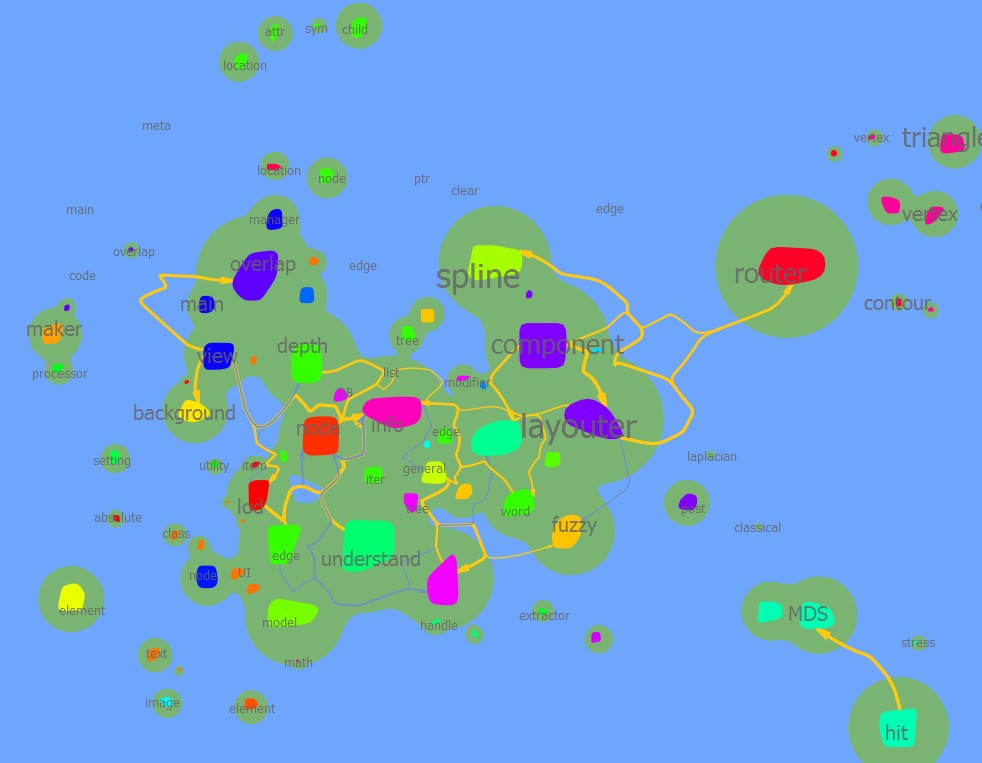 |  |  |  |
| 0.6 |  | 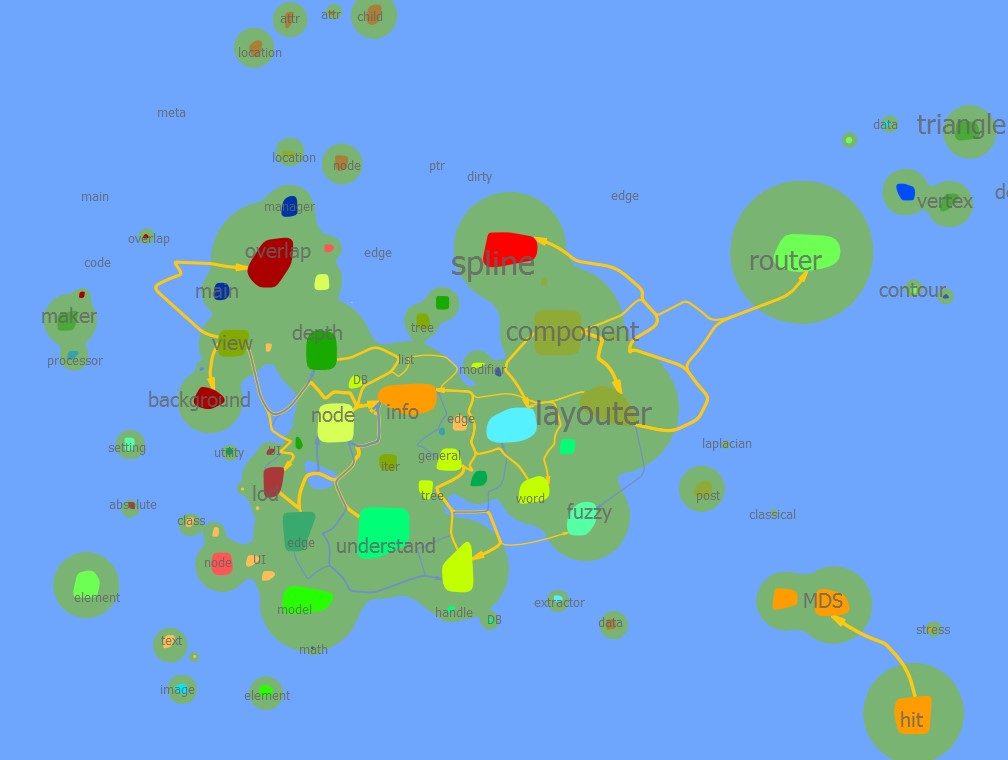 | 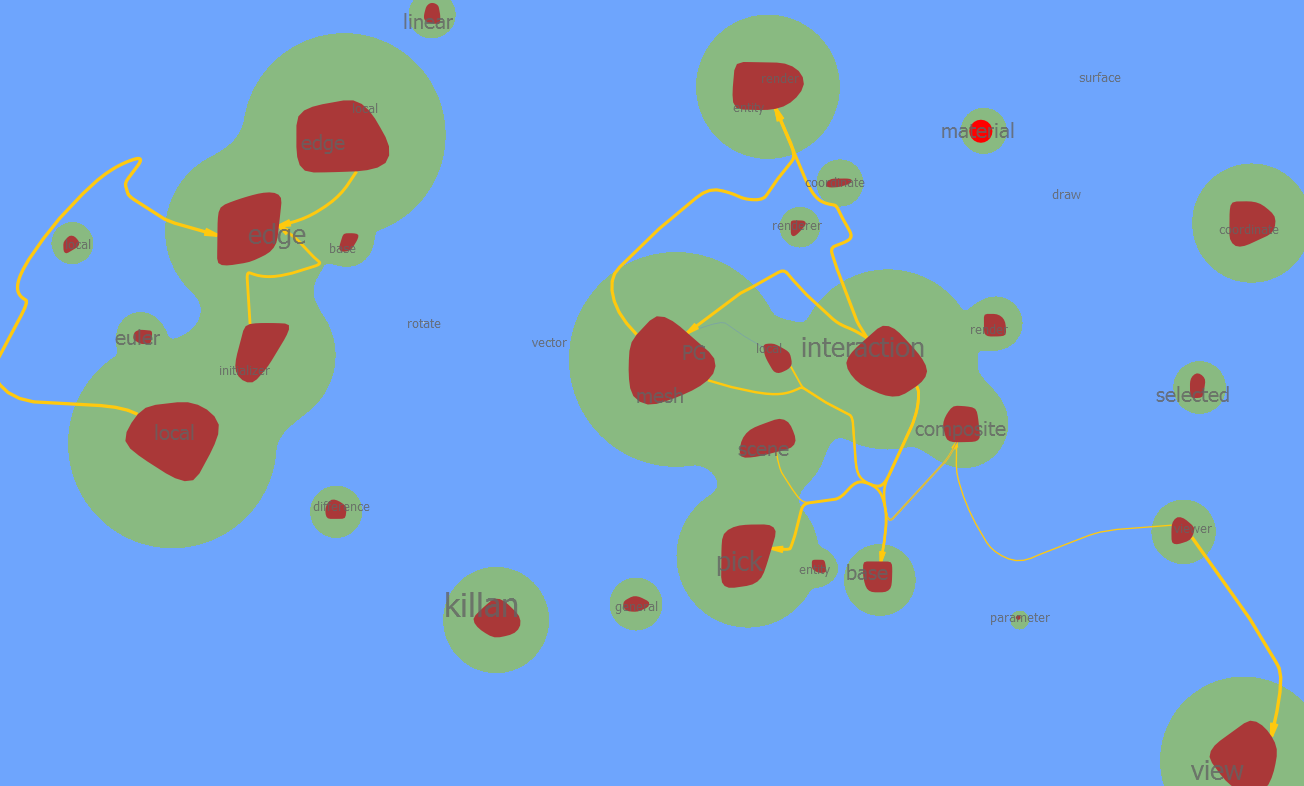 | |
| 0.4 |  |  此处spline componentlayouter layouter mds post processer等都被归为一类 |  | |
| 0.2 |  |  |  | |
| 0 |
结论是百分比阈值效果并不好,难以调节。
尝试改为固定阈值。
| 语义信息权重 | CodeView阈值=0.6 | CodeView阈值=0.7 | CodeView阈值=0.75 | GeometryProcess阈值=0.7 | GeometryProcess阈值=0.75 | Vega阈值=0.7 | Vega阈值=0.75 |
| 0.9 | 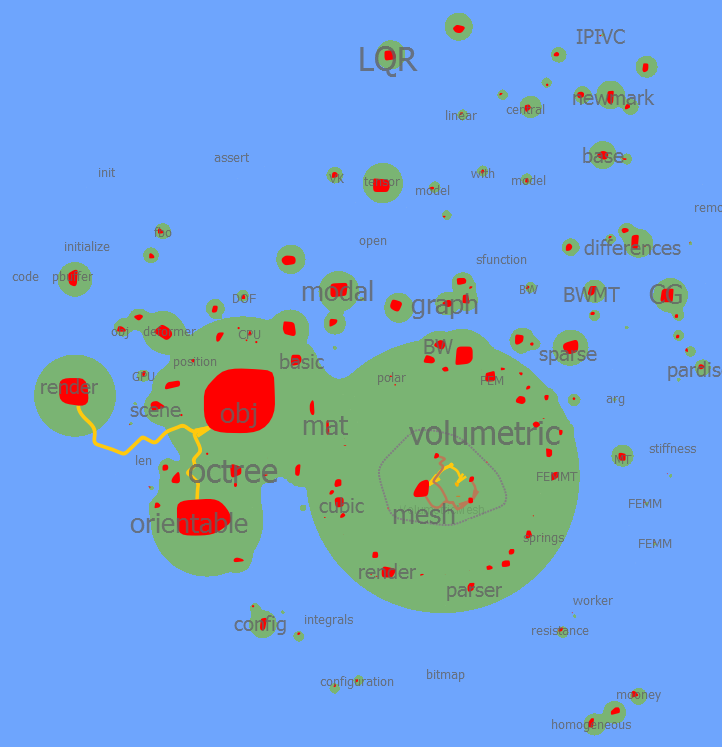 全部都聚成红色了 | ||||||
| 0.8 | 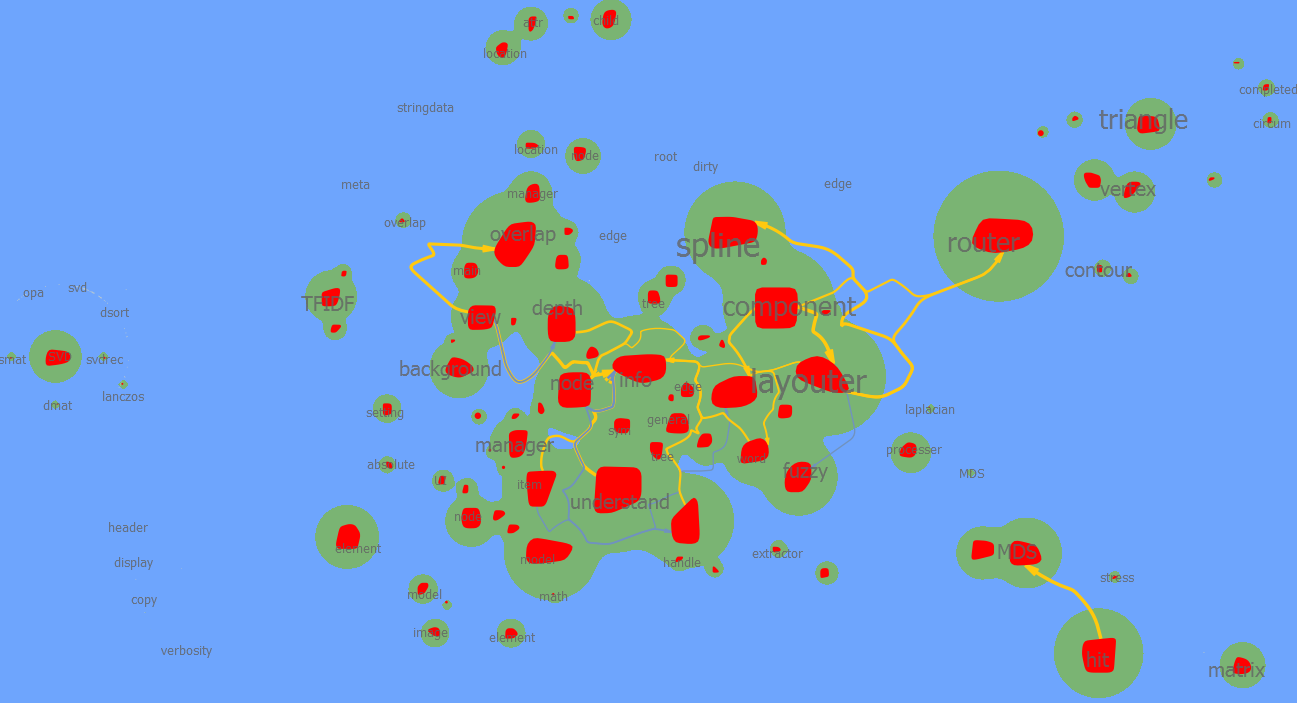 阈值太宽松,所有类都归为一类了 |  相比语义=0.8,阈值=0.6, overlap与symbolinfo分开了 backgroundrenderer 与textprocesser被合成一类 nodeUIItem与其他UIItem继续分开 |  属性方面:attr与其他部分分开 UI方面:uielement与各个uiitem成为一类 边方面:symboltree 与symboledge edgeuiitem symboledgeiter成为一类 |  自定义插值算法类、平台网格类被较好分割 |  平台类与右上角Qt属性类合并 网格类自成一类 自定义插值算法类仍然保持一致 蓝色为与Render相关的类,这些类之间没有依赖关系,可以看出语义权重增加的影响 |  opengl相关类自成一类 但红色类范围十分广泛,不知为何 |  开始呈现出有意义的划分。 右下角绿色点为弹性材质 右上角红色为求解器 左上角紫色为openGL相关 |
| 0.7 |  能够分开布局诸类,但节点属性类(***Attr)未能分开 | ||||||
| 0.5 | |||||||
语义信息权重增加时,总体相似度增加,满足阈值的边数增多,于是聚类个数减少。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号