一、背景
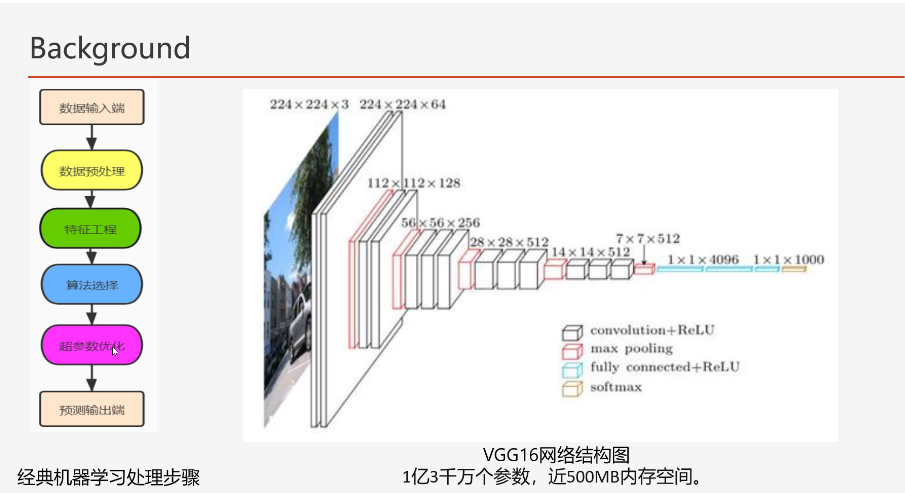
左侧描述经典的数据处理和机器学习流程。
中间的数据预处理、特征工程、算法选择、超参数优化四个步骤,有很多参数,很复杂,如何自动处理?
二、Introduction

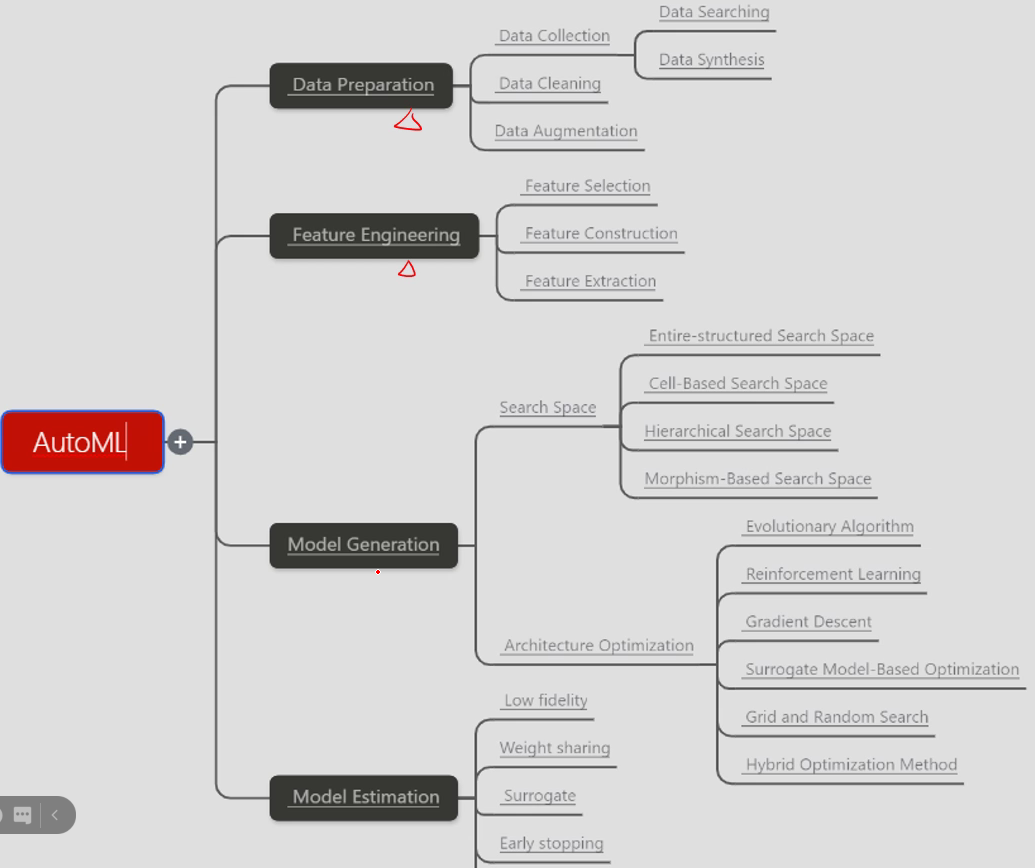
自动将四个步骤进行自动化处理
主要流程有以下四部分:

- 数据预处理:数据收集、数据清洗、数据增广等
- 特征工程: 特征选择、提取和特征构建
- 模型生成:分为搜索空间和架构优化。
- 模型评估: 可能生成很多模型,但是不可能将所有的模型都跑一遍,会很耗时,那么如何评估模型是一个很重要的部分。
下面会分别介绍几个部分。
三、数据预处理
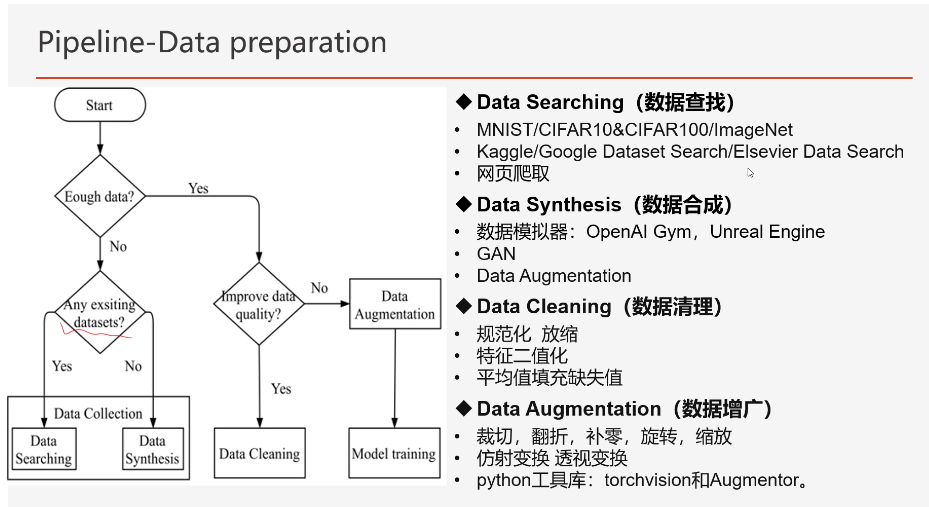
数据合成:可以利用数据增广来进行数据合成
如果数据合成的不太理想,还需要数据清理,比如数据的规范化、放缩、特征二值化(将所有数据归纳为0or1,)
数据增广是增强模型的鲁棒性,前提是保证数据的标签是不变的,例如做猫和狗的类型识别,对数据旋转的操作的时候标签不会改变,则可以用数据增广时候的旋转操作。
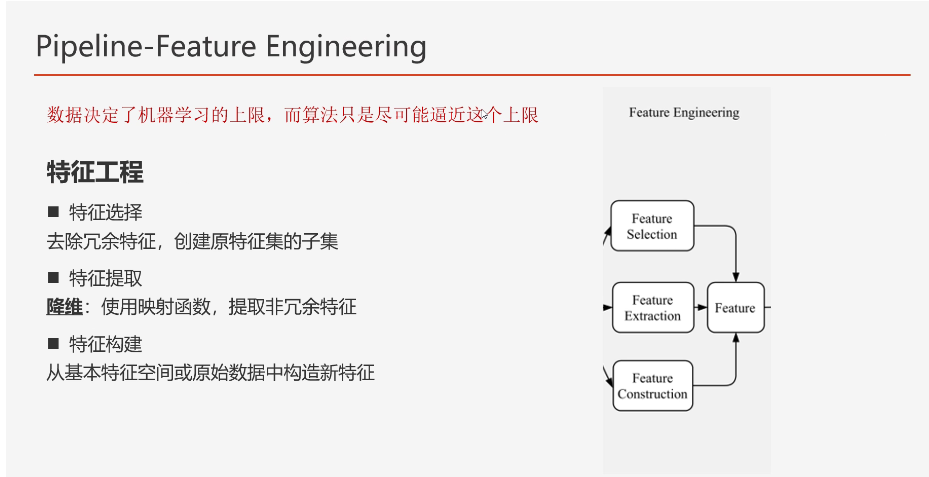
四、特征工程
五、NAS

5.1 搜索空间
分为整体结构、基于Cell的结构
(1)整体结构的网络搜索
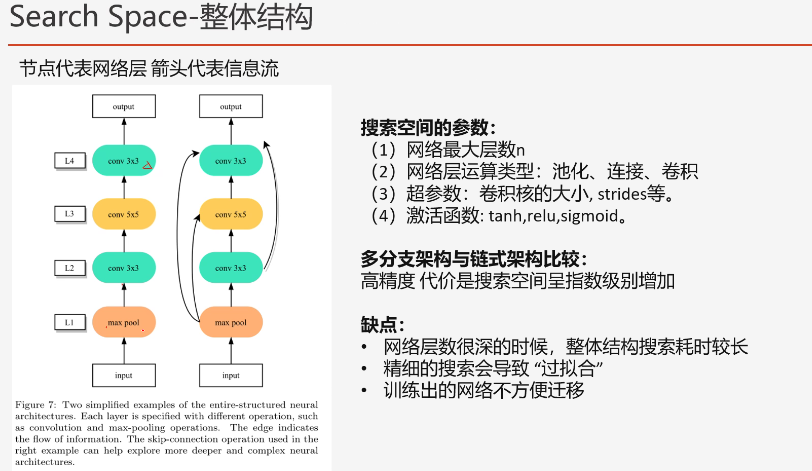
(2)基于Cell的结构

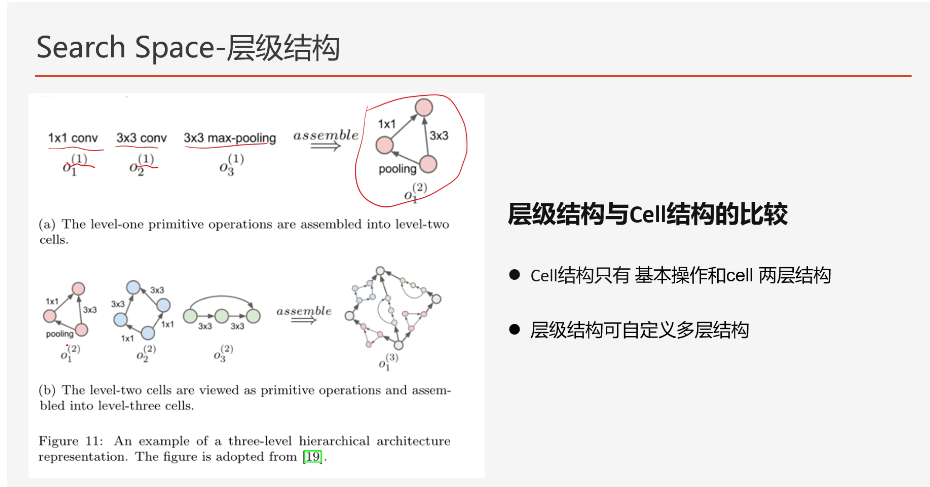
(3)层级结构
通过第一次的结构结合形成第二层的结构,然后形成第三层的结构...
灵活性更强、拓扑结构可以更复杂
(4)基于形态的结构
前三种是从无到有的生成模型,第四种是有一个基础网络,想办法把这个网络变得更好,比如将深度扩充。宽度延伸,使得网络的精度更高
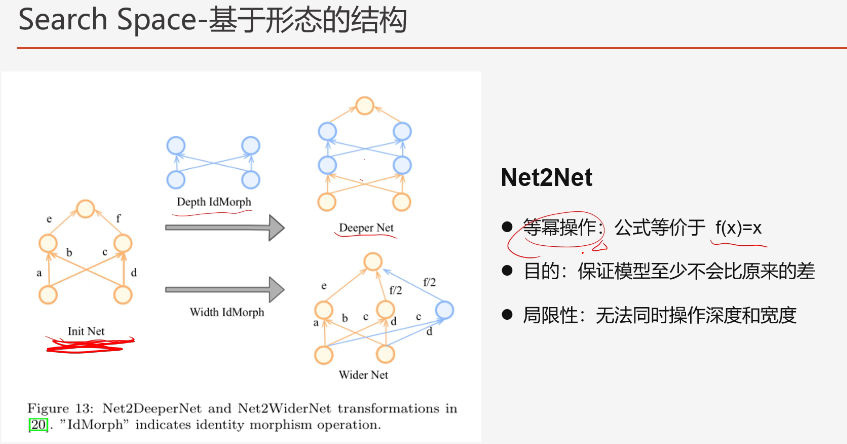
也有论文可以同时加深深度和宽度、或者加入自定义的网络。
5.2 网络优化
通过四种搜索空间的方式,可以选择出比较想要的网络架构,然后通过模型优化将参数优化到最佳,可以优化的方法入下:

(1)进化算法

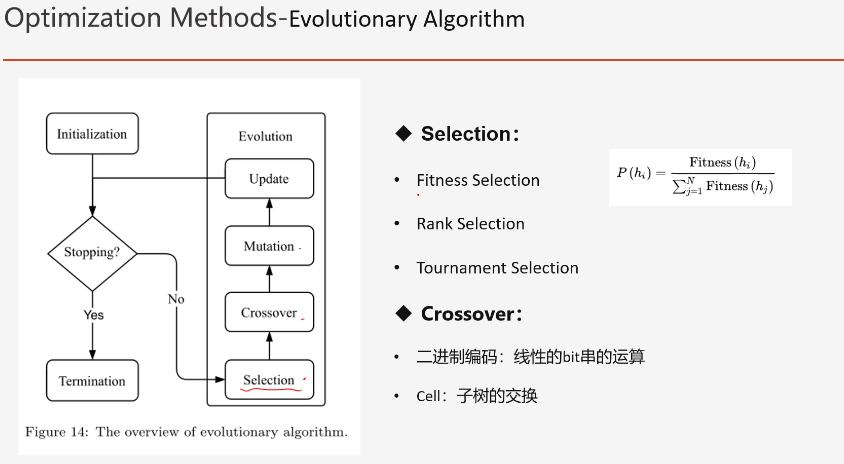
有很多网络层,我们用很多1bit的数据看网络的节点是否是连接的,如果全部是1则是全连接。
这些连接的编码0/1是最简单的编码方式,是直接编码。
间接编码:例如cell搜索空间结构,直接将cell插入一个cell 相当于是一个树的结构。
然后选择:
与基于选择类似,
- 首先选择:比如有竞赛选择等等;
- 然后再杂交:比如bit串的运算等等;
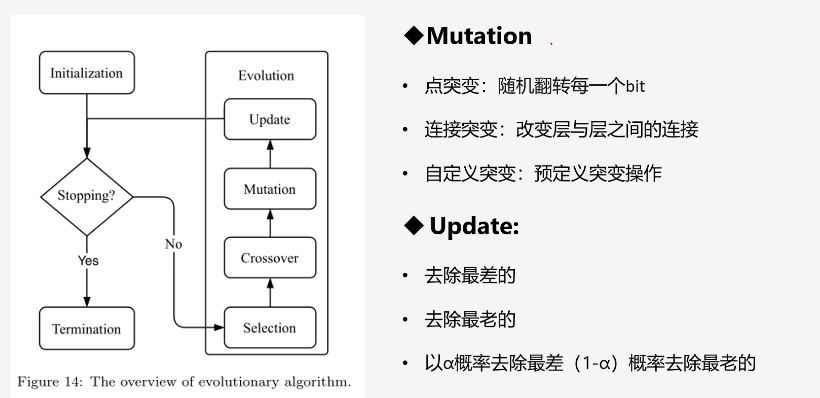
- 然后变异:点突变、连接突变、自定义突变;
- 最后更新:突变以后会有特别特别多的网络,会进行删减,方法是:去除最老或者最差的等等。
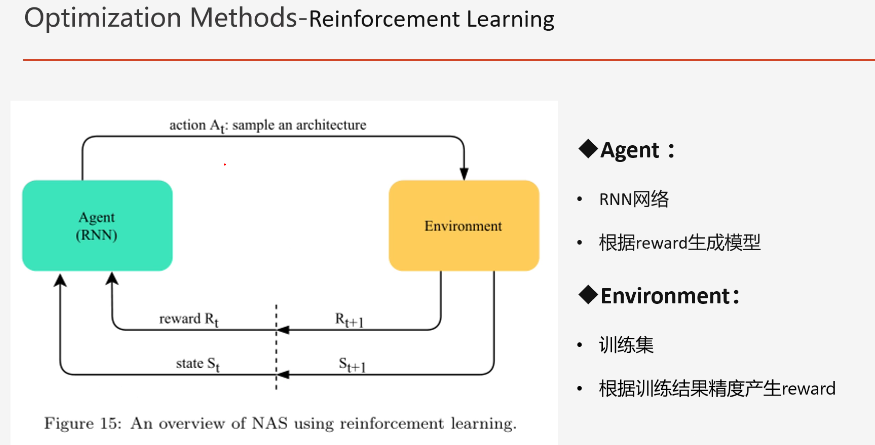
(2)基于强化学习的优化
用强化学习的策略来更新网络
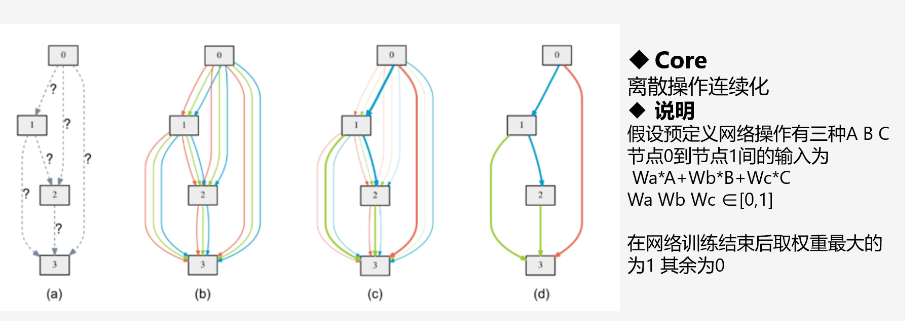
(3)基于梯度下降的优化
离散连续化后进行梯度下降
(4)网格或随机搜索
参数分为:重要参数和不重要参数来获取。
先使用大粒度查找,然后用小粒度的在一定最优的范围内进行查找最有的节点。

(5)基于模型的优化算法
是对超参数进行优化:
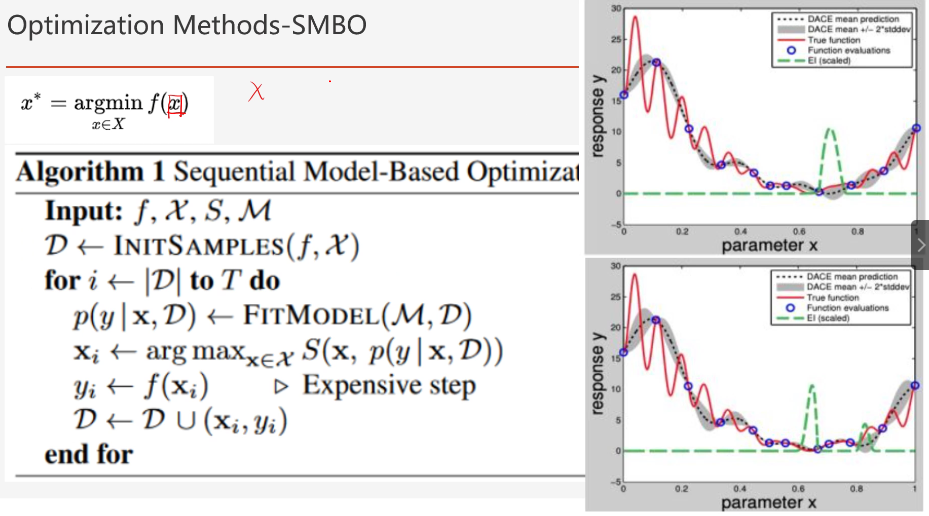
找到超参数x和损失函数之间的关系。
最常见的是基于贝叶斯优化:
其中f()是需要找到的对应的函数 xi是输入的超参数,yi是损失函数的度量。
图中的红色的曲线:是想要查找到的x和loss之间的关系,是未知的。

六、模型评估

七、 总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号