Python数据类型及方法整理大全
前言:主要是对Python数据类型做一个整理,部分知识点源于《python3程序开发指南(第二版)》
一、Python的关键要素
1.1 要素1:数据类型
int类型
str类型
组合数据类型:
元组
列表
字典
集合
组合数据类型的区别:
1.形式不一样:列表是[]形式,元组()形式,字典、集合是{}形式
2.可变不可变:列表、字典、集合可变,元组不可变
3.哈希不可哈希:列表、字典、集合不可哈希,字符串str、数字、元组tuple可哈希
可哈希的数据类型,即不变的数据结构 (字符串、整数、元组)
不可哈希的数据类型,即可变的数据结构 (字典dict,列表list,集合set)
4.有序无序:列表、元组有序,字典、集合无序
5.集合的元素,字典的key必须是可哈希的
6.集合中的元素都是不重复的,元组和列表可以重复
7.支持的内置方法不同
二、数据类型
组合数据类型是对象,因此每种数据类型都有自己的方法。Python所有变量实际上是对象引用
2.1 标识符与关键字
Python的关键字

Python标识符命名规范:
- 由字符(A~Z 和 a~z)、下划线和数字组成,但不能以数字开头;
- 不能以python中的关键字命名;
-
- 2.1. 不能与Python关键字同名
-
- 2.2 不能与Python内置数据类型(如int/float/list/str/tuple)同名
-
- 2.3. 不能与Python内置函数名与异常名作为标识符名
- Python中的标识符中,不能包含空格、@、% 以及 $ 等特殊字符。
- Python 中,标识符中的字母是严格区分大小写的,相同单词大小格式不同代表意义不同,如:
-
- number = 0
-
- Number = 0
-
- NUMBER = 0
- 变量名命名要有意义,最好见名知意,提高代码可读性
- 推荐使用大小驼峰型(GuessAge或guessAge)和下划线(guess_age)来命名;
- 常量通常使用大写来定义
- Python 语言中,以下划线开头的标识符有特殊含义,例如:
-
- 以单下划线开头的标识符(如 _width),表示不能直接访问的类属性,其无法通过 from...import* 的方式导入;
-
- 以双下划线开头的标识符(如__add)表示类的私有成员;
-
- 以双下划线作为开头和结尾的标识符(如 __init__),是专用标识符。
因此,除非特定场景需要,应避免使用以下划线开头的标识符。
2.2 Integral类型
内置Integral类型:int、浮点类型(浮点数、复数、十进制数字)、布尔值,True表示1,False表示0
2.2.1 整数
- 图:数值型操作与函数

2.3 字符串
字符串可以使用引号创建,python中字符串是不可变对象。字符串是一个有序的字符的集合,一对单,双或三引号中间包含的内容称之为字符串,其中三引号可以由多行组成
2.3.1字符串转义
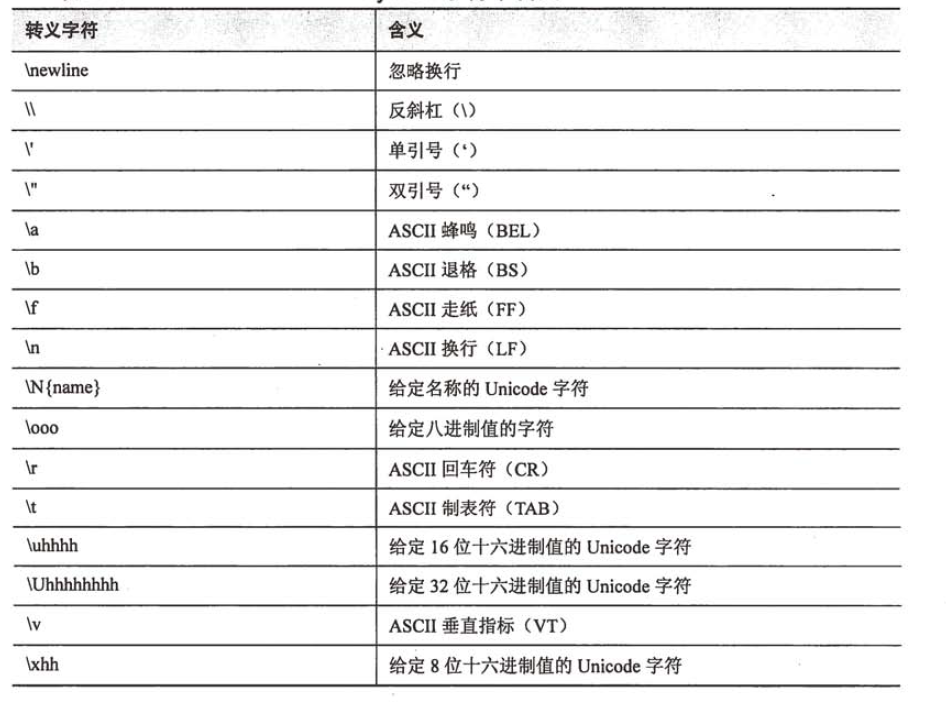
2.3.2 字符串运算符

2.3.3 字符串格式化
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
2.3.4 字符串操作方法
字符串可以取切片(通过索引、步长值取值)
语法格式:
- seq = "abcdefg"
- [:] 提取从开头(默认位置0)到结尾(默认位置-1)的整个字符串
- seq[start]
如: seq[1],取第二个字符“b”
3. [start:] 从start 提取到结尾
4. [:end] 从开头提取到end - 1
5. seq[start:end]
如: seq[1:3] 包含上边界不包含下边界,因此取值为"bc"
如: seq[1:] 取值从第二个字符至结尾:"bcdefg"
6. seq[start:end:step] 如seq[1:4:2]步长值为2,因此取值"bd"
7. 负索引:-1表示最后一个字符
seq可以是任意序列,比如列表、字符串或元组,start、end、step必须是整数,
字符串常用方法

2.3.5 string模块

2.4 元组
所谓元组的不可变指的是元组所指向的内存中的内容不可变。
2.4.1 元组的内置方法
2.4.2 访问元组
元组可以使用下标索引来访问元组中的值
#!/usr/bin/python3
tup1 = ('Google', 'Runoob', 1997, 2000)
print (tup1[0])
print (tup2[1:5])
2.4.3 修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合,如下实例:
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。# tup1[0] = 100
#创建一个新的元组,可进行元组合并
tup3 = tup1 + tup2
print (tup3)
2.4.4 删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup = ('Google', 'Runoob', 1997, 2000)
del tup
2.4.5 元组运算符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | TRUE | 元素是否存在 |
| for x in (1, 2, 3): print (x,) | 1 2 3 | 迭代 |
2.5 列表
2.5.1 列表方法

2.5.2 列表内涵
列表内涵是一个表达式,也是一个循环,该循环有一个可选的,包含在方括号中的条件,作用是为列表生产数据选项,并且可以使用条件过滤掉不需要的数据项。
列表内涵最简单的形式如下:
[item for item in iterable]
上面的语句将返回一个列表,其中包含iterable中的每个数据项,在语义上与list(iterable)是一致的。有两个特点使得列表内涵具有更强大的功:一个是可以使用表达式,另一个是可以附件条件,由此带来如下两种实现列表内涵的常见语法格式:
[expression for item in iterable]
[expression for item in iterable if condition]
第二种 相当于
temp=[]
for item in iterable:
if condition:
temp.append(item)
例子1:指定生成闰年方式
leaps=[]
for year in range(1900,1940):
if(year%4==0 and year%100!=0)or (year%400==0)
leaps.append(year)
使用列表内涵
leaps=[y for y in range(1900,1940) if(y%4==0 and y%400!=0) or(y%400=0)]
例子2:计算50以内的和
print(sum([i for i in range(1,51)]))
print(sum(range(1, 51)))
例子3:计算九九乘法表
s = [(x, y, x*y) for x in range(1, 10) for y in range(1,10) if x>=y]
2.6 集合
Python提供两种内置的集合类型:可变的set类型,固定的frozenset类型。
集合特性:
1.集合元素必须是可哈希即不可变数据类型(比如float,frozenset,int,str,touple)
2.集合元素是无序的,不能使用索引、切片取值
只有可哈希运算的对象可以添加到集合中,所有固定的数据类型(比如float,frozenset,int,str,touple)都是可哈希运算的,可以添加到集合中。内置的可变数据类型(比如list,dictset)都是不可哈希的,因为其哈希值会随着包含项数的变化而变化,因此,这些数据类型都是不能添加到集合中的。
集合是0个或多个对象引用的无序组合,这些对象所引用的对象都是可哈希运算的。几个是可变的,但由于其中的项是无序的,因此没有索引位置,不能分片或按步距分片。
2.6.1 集合方法与操作符
| 语法 | 描述 |
| s.add(x) | 将数据项x添加到集合s中(如果s中未包含x) |
| s.clear() | 清楚集合s中的所有数据项 |
| s.pop() | 返回并移除已集合s中一个随机项,如果s为空集,就会产生KeyError |
| s.remove(x) | 从集合s中移除数据项x,如果s中不包含x,就会产生KeyError |
| s.discard(x) | 如果数据项x存在于集合s中,就移除该数据项,参见set.remove() |
| s.copy() | 返回集合元素的浅拷贝 |
| s.difference(t) s-t | 返回一个新集合,其中包含在s中但不在集合t中的所有数据项 |
| s.difference_update(t) s-=t | 移除每一个在集合t但不在集合s中的项 |
| s.union(t) s|t | 返回新集合,包含s中所有数据项以及在t中不在s中的数据项 |
| s.update(t) s|=t | 将集合t中每个s中不包含的数据项添加到集合s中 |
2.6.2 集合内涵
集合内涵是一个表达式,也是一个带有可选条件(包含在花括号中)的循环,与列表内涵类似,也支持两种语法格式
{expression for item in iterable}
- {expression for item in iterable if condition}
- 我们可以使用上面语法过滤,下面给出一个实例:
- Html = {x for x in files if x.lower().endswith(('.htm','.html'))} 意思是集合html只存放那些以.htm或.html结尾的文件名这里不区分大小写
2.7 映射类型
字典特性:
1.key是可哈希运算的对象即(比如float,frozenset,int,str,touple)
- 2.字典的键是不能重复的,独一无二
- 3.字典是无序的,不能通过索引取切店
4. 字典是可变的
字典的方法:
| 语法 | 描述 |
| d.clear() | 从dict d中移除所有项 |
| d.copy() | 返回dict d的浅拷贝 |
| d.fromkeys(s,v) | 返回一个dict,字典的键为序列s中的所有项,值为None或v |
| d.get(k) | 返回k对应的value,如果k不在字典中返回None |
| d.get(k,v) | 返回k对应的value,如果k不在字典中就返回v |
| d.items() | 返回dict中所有key,value项 |
| d.keys() | 返回dict中的所有key |
| d.values() | 返回dict中的所有value |
| d.pop(k) | 返回k对应的value,并移除k的项,如果k不存在就产生KeyError |
| d.pop(k,v) | 返回k对应的value,并移除k的项,如果k不存在就返回v |
| d.popitem() | 返回并移除dict中一个任意的key,value对,如果d为空就产生KeyError |
| d.setdefault(k,v) | 与d.get()方法一样,不同处如果k没有包含在dict d中就插入一个键为k的新项,其值为None或v,可用于赋值 |
| d.update(a) | 将a中不包含在b的(key,value)添加到d,如包含则替换 |
dict.setdefault(key, default=None) --> 有key获取值,否则设置 key:default,并返回default,default默认值为None,会修改原字典
dict.get(key, default=None) --> 有key获取值,否则返回default。default默认值为None。
字典内涵
两种语法格式:
[keyexpression:valueexpression for key, value in iterable]
[keyexpression:valueexpression for key, value in iterable if condition]
实例一:如果使用字典内涵创建字典,键为当前目录中文件的文件名,值为以字节计数的文件大小
os.listdir()返回传递给函数的路径中包含的文件与目录列表但列表中不会包含"."或".."
os.path.getsize()函数返回给定文件的大小(以字节计数)
file_sizes = {name:os.path.getseize(name) for name in os.listdir(".")}
file_sizes = {name:os.path.getseize(name) for name in os.listdir(".")
if os.path.isfile(name)}
字典内涵可用于创建反转目录,比如给定字典d,生成一个新字典,新字典的键是d的值,值是d的键
inverted_d = {v:k for k,v in d.items()}
每天进步一小步 日积月累跨大步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号