【廖雪峰】Python
Python是一种相当高级的语言。
![]()
![web-utf-8]()
![]()
![]()
![]()
![]()
TIOBE排行榜
高级编程语言通常都会提供一个比较完善的基础代码库,让你能直接调用,
许多大型网站就是用Python开发的,例如YouTube、Instagram,还有国内的豆瓣。
Python的哲学就是简单优雅
那Python适合开发哪些类型的应用呢?
- 网络应用,包括网站、后台服务等等;
- 脚本任务等等;
- 把其他语言开发的程序再包装起来,方便使用。
缺点:
- 运行速度慢:解释型语言,执行的时候翻译称为机器代码。
- 代码不能加密:靠网站和移动应用卖服务的模式越来越多了
安装
Python3.5
在Windows上运行Python时,请先启动命令行,然后运行python。
在Mac和Linux上运行Python时,请打开终端,然后运行python3。
Python解释器
Cpython:官方
第一个Python程序
退出:exit()
命令行模式和Python交互模式
python calc.py
使用文本编辑器
#!/usr/bin/env python3print('hello, world')
$ chmod a+x hello.py直接输入python进入交互模式,相当于启动了Python解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行。
直接运行.py文件相当于启动了Python解释器,然后一次性把.py文件的源代码给执行了,你是没有机会以交互的方式输入源代码的。
Python代码运行助手
网页上输入代码,通过本机的Python库进行解释。
输入和输出
print()会依次打印每个字符串,遇到逗号“,”会输出一个空格,因此,输出的字符串是这样拼起来的:
print()也可以打印整数,或者计算结果
输入
name = input()
提示字符串:
name = input('please enter your name: ')python基础
其他每一行都是一个语句,当语句以冒号:结尾时,缩进的语句视为代码块。
缩进的坏处就是“复制-粘贴”功能失效了,
最后,请务必注意,Python程序是大小写敏感的,如果写错了大小写,程序会报错。
在文本编辑器中,需要设置把Tab自动转换为4个空格,确保不混用Tab和空格。
变量和类型
字符串
字符串是以单引号'或双引号"括起来的任意文本
>>> print(r'\\\t\\')用r''表示''内部的字符串默认不转义
字符串有很多行:
用\n写在一行里不好阅读,为了简化,Python允许用'''...'''的格式表示多行内容
>>> print('''line1
... line2
... line3''')
line1
line2
line3布尔值
True、False
if age >= 18:
print('adult')
else:
print('teenager')空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
变量
理解变量在计算机内存中的表示也非常重要。当我们写:
a = 'ABC'
时,Python解释器干了两件事情:
- 在内存中创建了一个'ABC'的字符串;
- 在内存中创建了一个名为a的变量,并把它指向'ABC'。
a = 'ABC'
b = a
a = 'XYZ'print(b)执行a = 'ABC',解释器创建了字符串'ABC'和变量a,并把a指向'ABC':

执行b = a,解释器创建了变量b,并把b指向a指向的字符串'ABC':

执行a = 'XYZ',解释器创建了字符串'XYZ',并把a的指向改为'XYZ',但b并没有更改:

所以,最后打印变量b的结果自然是'ABC'了。
一种除法是//,称为地板除,两个整数的除法仍然是整数:
>>> 10 // 33Python还提供一个余数运算,可以得到两个整数相除的余数:
>>> 10 % 31Python的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如Java对32位整数的范围限制在-2147483648~-2147483647。
Python的浮点数也没有大小限制,但是超出一定范围就直接表示为inf(无限大)
字符串和编码
最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
把Unicode编码转化为“可变长编码”的UTF-8编码
常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
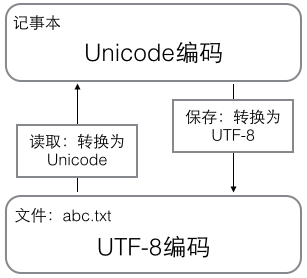
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
print('包含中文的str')>>> ord('A')
65>>> chr(66)
'B',Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。而在内存中用Unicode进行表示,一个字符对应多个字节
x = b'ABC'注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes
>>> 'ABC'.encode('ascii')
b'ABC'>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'在bytes中,无法显示为ASCII字符的字节,用\x##显示。
'中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'计算字符数:len('中文')
计算字节数:
>>> len(b'ABC')
3>>> len('中文'.encode('utf-8'))
6为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
按照UTF-8进行读取:
#!/usr/bin/env python3# -*- coding: utf-8 -*-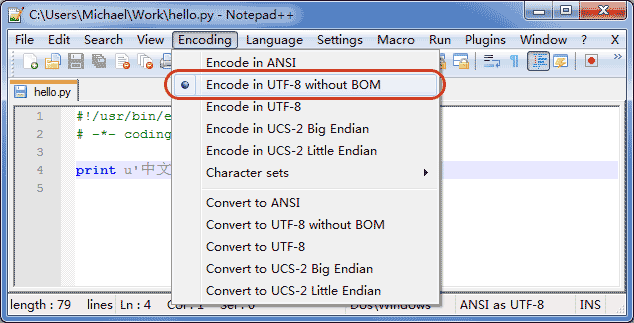
格式化
'Hello, %s' % 'world' 'Hi, %s, you have $%d.' % ('Michael', 1000000)| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
>>> '%2d-%02d' % (3, 1)
' 3-01'>>> '%.2f' % 3.1415926'3.14'补零
'Age: %s. Gender: %s' % (25, True)会把所有类型转换为字符串。
用%%来表示一个%:
list和tuple
list
。list是一种有序的集合,可以随时添加和删除其中的元素。
classmates = ['Michael', 'Bob', 'Tracy'] len(classmates)classmates[0]记得最后一个元素的索引是len(classmates) - 1。
倒数第二个: classmates[-2]
list是一个可变的有序表,所以,可以往list中追加元素到末尾:
classmates.append('Adam')要删除list末尾的元素,用pop()方法:
classmates.pop()要删除指定位置的元素,用pop(i)方法,其中i是索引位置:
要把某个元素替换成别的元素,可以直接赋值给对应的索引位置:classmates[1] = 'Sarah'
list里面的元素的数据类型也可以不同,比如:>>> L = ['Apple', 123, True]
也可以是另外的list:s = ['python', 'java', ['asp', 'php'], 'scheme']
要拿到'php'可以s[2][1],
tuple
元组
一旦初始化以后就不能修改。
classmates = ('Michael', 'Bob', 'Tracy')
所以也没有append() , insert()这样的方法。
代码可以更安全,尽可能使用。
t = (1)既可能是表示元组,也可能是表示括号。
t = (1,)消除歧义。
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'>>> t[2][1] = 'Y'>>> t
('a', 'b', ['X', 'Y'])tuple包含3个元素。

变的其实是list的元素。
所谓的不变指的是指向永远不变。
小结
list和tuple是Python内置的有序集合,一个可变,一个不可变。
条件判断
age = 3if age >= 18:
print('adult')
elif age >= 6:
print('teenager')
else:
print('kid')注意else后面的冒号。
elif是else if 的缩写。
如果在某个判断上是True,把该判断对应的语句执行后,就忽略掉剩下的elif和else
birth = input('birth: ')
if birth < 2000:
print('00前')
else:
print('00后')输入的是字符串。但是2000是数字,不能比较。
s = input('birth: ')
birth = int(s)
if birth < 2000:
print('00前')
else:
print('00后')通过int(s)把字符串转换为数字。
循环
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)提供一个range()函数,可以生成一个整数序列,再通过list()函数可以转换为list。比如range(5)生成的序列是从0开始小于5的整数:
list(range(5))range(101)就可以生成0-100的整数序列
sum = 0
n = 99while n > 0:
sum = sum + n
n = n - 2print(sum)在循环内部变量n不断自减,直到变为-1时,不再满足while条件,循环退出。
使用dict和set
dict
其他语言map,键值对。
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}>>> d['Michael']
95在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。
要避免key不存在的错误,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False二是通过dict提供的get方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
dict是用空间来换取时间的一种方法。
dict的key必须是不可变对象
通过key计算位置的算法称为哈希算法(Hash)。
而list是可变的,就不能作为key:
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
s = set([1, 2, 3])
重复元素自动过滤
s = set([1, 1, 2, 2, 3, 3])通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
通过remove(key)方法可以删除元素:
set可以看成数学意义上的无序和无重复元素的集合
set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。
再议不可变对象
>>> a = ['c', 'b', 'a']
>>> a.sort()
>>> a
['a', 'b', 'c']内部对象是会变化的。
>>> a = 'abc'>>> a.replace('a', 'A')
'Abc'>>> a
'abc'虽然replace可以变出Abc,但是实际上a仍然是abc
a是变量,而'abc'才是字符串对象!有些时候,我们经常说,对象a的内容是'abc',但其实是指,a本身是一个变量,它指向的对象的内容才是'abc':
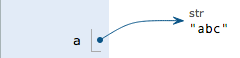
replace方法创建了一个新字符串'Abc'并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串'abc',但变量b却指向新字符串'Abc'了:

对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
最常用的key是字符串。
函数
定义函数
def my_abs(x):if x >= 0:
return x
else:
return -x用from abstest import my_abs来导入my_abs()函数,注意abstest是文件名(不含.py扩展名):
空函数
使用pass语句。
def nop():pass作为占位符。
不会对参数类型做检查。
用内置函数isinstance()实现:
def my_abs(x):if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x返回多个值
import math语句表示导入math包,并允许后续代码引用math包里的sin、cos等函数。
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny返回仍然是单一值,是一个tuple。
函数的参数
位置参数
修改后的power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
def power(x, n=2):
s = 1while n > 0:
n = n - 1
s = s * x
return s一是必选参数在前,默认参数在后,否则Python的解释器会报错
二是如何设置默认参数。
当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
def add_end(L=[]):
L.append('END')
return L此时默认参数是可变的list
第一次调用
>>> add_end()
['END']后面调用就不对了。
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
所以,定义默认参数要牢记一点:默认参数必须指向不变对象!
可以通过不变对象None来实现。
def add_end(L=None):if L is None:
L = []
L.append('END')
return L>>> add_end()
['END']
>>> add_end()
['END']由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。
可变参数
def calc(*numbers):
sum = 0for n in numbers:
sum = sum + n * n
return sumPython允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)可以传入任意个数的关键字参数
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}可以扩展函数的功能。
可以先组装为一个dict,然后传进去。
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字
在内部对传入的关键字进行检测。
def person(name, age, **kw):if 'city' in kw:
# 有city参数passif 'job' in kw:
# 有job参数pass
print('name:', name, 'age:', age, 'other:', kw)def person(name, age, *, city, job):
print(name, age, city, job)如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)参数组合
参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)>>> f1(1, 2)
a = 1 b = 2 c = 0 args = () kw = {}
>>> f1(1, 2, c=3)
a = 1 b = 2 c = 3 args = () kw = {}
>>> f1(1, 2, 3, 'a', 'b')
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
>>> f1(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
>>> f2(1, 2, d=99, ext=None)
a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}通过一个tuple和dict,你也可以调用上述函数:
>>> args = (1, 2, 3, 4)
>>> kw = {'d': 99, 'x': '#'}
>>> f1(*args, **kw)
a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
>>> args = (1, 2, 3)
>>> kw = {'d': 88, 'x': '#'}
>>> f2(*args, **kw)
a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
小结
默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
要注意定义可变参数和关键字参数的语法:
*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3));
关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符*,否则定义的将是位置参数。
递归函数
def fact(n):if n==1:
return 1return n * fact(n - 1)防止栈溢出。
通过尾递归优化。和循环的效果一样。在函数返回的时候,调用自身。return不能包含表达式。
这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
要把每一步的乘积传入到递归函数中:
def fact(n):return fact_iter(n, 1)
def fact_iter(num, product):if num == 1:
return product
return fact_iter(num - 1, num * product)可以看到,return fact_iter(num - 1, num * product)仅返回递归函数本身,num - 1和num * product在函数调用前就会被计算,不影响函数调用。
高级特性
构造列表:
L = []n = 1while n <= 99:L.append(n)n = n + 2
切片
取前N个元素。
>>> r = []
>>> n = 3>>> for i in range(n):
... r.append(L[i])
...
>>> L[0:3]>>> L[-2:]记住倒数第一个元素的索引是
-1。前11-20个数:
>>> L[10:20]前10个数,每两个取一个:
>>> L[:10:2]
所有数每5个取一个
>>> L[::5]复制应该 list
>>> L[:]tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple:
>>> (0, 1, 2, 3, 4, 5)[:3]字符串'xxx'也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串
>>> 'ABCDEFG'[:3]
'ABC'>>> 'ABCDEFG'[::2]
'ACEG'针对字符串提供了很多各种截取函数(例如,substring),其实目的就是对字符串切片。Python没有针对字符串的截取函数,只需要切片一个操作就可以完成,非常简单。
迭代
迭代:遍历list or tuple
Python中迭代是通过for in 实现的,java是通过下标实现的。
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...默认dict迭代的是key
如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象,因此,也可以作用于for循环:
如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代True>>> isinstance([1,2,3], Iterable) # list是否可迭代True>>> isinstance(123, Iterable) # 整数是否可迭代FalsePython内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C上面的for循环里,同时引用了两个变量,在Python里是很常见的
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:... print(x, y)...1 12 43 9
列表生成式
List Comprehensions :内置的,用来创建list的生成式。
>>> list(range(1, 11))如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?
>>> [x * x for x in range(1, 11)]for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
[x * x for x in range (1 , 11) if x %2 = 0]
还可以使用两层循环,可以生成全排列:
[m + n for m in 'ABC' for n in 'abc']
列出当前目录下的文件和目录
import os[d for d in os.listdir ('.')]
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> for k, v in d.items():
... print(k, '=', v)
...
y = B
x = A
z = C
d = {'x' : 'A' , 'y' : 'B' , 'z' : 'C'}[k + '=' + v for k,v in d.items()]
最后把list的字符串变为小写。
L = ['Hello', 'World', 'IBM', 'Apple']
[s.lower() for s in L]
>>> L = ['Hello', 'World', 18, 'Apple', None]>>> [s.lower() for s in L]Traceback (most recent call last):File "<stdin>", line 1, in <module>File "<stdin>", line 1, in <listcomp>AttributeError: 'int' object has no attribute 'lower'
如果list中既包含字符串,又包含整数,由于非字符串类型没有lower()方法,所以列表生成式会报错:
使用内建的isinstance函数可以判断一个变量是不是字符串:
isinstance(x, str)
L2 = [s.lower() for s in L1 if isinstance (s , str)]
生成器
列表容量是有限的。
列表的元素按照算法推算出
generator:一边循环一边计算
把列表表达式中的[]变为()
打印:next ()
也可以使用循环。
g = (x * x for x in range (10))for i in gprint (i)
如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
def fib (max)n , a , b = 0 , 0 , 1while n < max :print(b)a , b = b , a + bn = n + 1return 'done'
a , b = b , a + b
相当于
t = (b , a + b)a = t[0]b = t[1]
要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
>>> f = fib(6)
>>> f
<generator object fib at 0x104feaaa0>最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回
而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
但是用for循环调用generator时,发现拿不到generator的return语句的返回值,因为每次在yield处就中断了。
如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)>>> while True:... try:... x = next(g)... print('g:', x)... except StopIteration as e:... print('Generator return value:', e.value)... break...
普通函数调用直接返回结果:
generator函数的“调用”实际返回一个generator对象:
迭代器
可以作用于for循环的主要有如下两种:
- 集合数据类型:list,tuple,dict , set , str
- generator : 生成器和带yield的generate function
可以直接作用于for循环的对象,统称为可迭代对象:Iterable
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True为什么list、dict、str等数据类型不是Iterator?
因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
for循环本质上就是通过不断调用next()函数实现的
# 首先获得Iterator对象:it = iter([1, 2, 3, 4, 5])# 循环:while True:try:# 获得下一个值:x = next(it)except StopIteration:# 遇到StopIteration就退出循环break
函数式编程
而函数式编程(请注意多了一个“式”字)——Functional Programming,
在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。
而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。
对应到编程语言,就是越低级的语言,越贴近计算机,抽象程度低,执行效率高,比如C语言;越高级的语言,越贴近计算,抽象程度高,执行效率低,比如Lisp语言。
高阶函数
Higher-order function
变量可以指向函数
abs(-10)是函数调用,而abs是函数本身。
f = abs
结论:函数本身也可以赋值给变量,即:变量可以指向函数。
>>> f = abs
>>> f(-10)
10直接调用abs()函数和调用变量f()完全相同。
函数名也是变量
对于abs()这个函数,完全可以把函数名abs看成变量,它指向一个可以计算绝对值的函数!
如果把abs指向其他对象,会有什么情况发生?
>>> abs = 10
>>> abs(-10)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable要恢复abs函数,请重启Python交互环境。
注:由于abs函数实际上是定义在import builtins模块中的,所以要让修改abs变量的指向在其它模块也生效,要用import builtins; builtins.abs = 10。
传入函数
那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x, y, f):return f(x) + f(y)add(-5, 6, abs)
x = -5
y = 6
f = abs
f(x) + f(y) ==> abs(-5) + abs(6) ==> 11return 11map/reduce
map()函数接收两个参数,一个是函数,一个是Iterable,
map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:

>>> def f(x):... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数
>>> list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
['1', '2', '3', '4', '5', '6', '7', '8', '9']reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)序列求和:
>>> from functools import reduce
>>> def add(x, y):... return x + y
...
>>> reduce(add, [1, 3, 5, 7, 9])
25如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> from functools import reduce
>>> def fn(x, y):... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
13579果考虑到字符串str也是一个序列,对上面的例子稍加改动,配合map(),我们就可以写出把str转换为int的函数:
>>> from functools import reduce>>> def fn(x, y):... return x * 10 + y...>>> def char2num(s):... return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]...>>> reduce(fn, map(char2num, '13579'))13579
整理成一个str2int的函数就是:
from functools import reducedef str2int(s):def fn(x, y):return x * 10 + ydef char2num(s):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]return reduce(fn, map(char2num, s))
还可以用lambda函数进一步简化成:
from functools import reducedef char2num(s):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]def str2int(s):return reduce(lambda x, y: x * 10 + y, map(char2num, s))
from functools import reducedef str2float(L):dotIndex=L.find('.')times=len(L)-dotIndex-1s=L.replace('.','')def char2num(s):return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]def fn(x, y):return x * 10 + yL=reduce(fn, map(char2num, s))print ('times = ', pow(10,times))return L/pow(10 , times)print(str2float('123.456'))
filter
过滤序列。
接收一个序列。
把传入的函数作用于每个元素,根据返回值是ture和False决定保留还是丢弃。
删除偶数,保留奇数。
def is_odd(n):return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]如果为false,则删除。
s.strip(rm) 删除s字符串中开头、结尾处,位于 rm删除序列的字符
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' ')
把空字符串删掉。
def not_empty(s):return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
用filter求素数
埃氏筛法
首先,列出从2开始的所有自然数,构造一个序列:
取序列的第一个数2,它一定是素数,然后用2把序列的2的倍数筛掉:
取新序列的第一个数3,它一定是素数,然后用3把序列的3的倍数筛掉:
取新序列的第一个数5,然后用5把序列的5的倍数筛掉:
构造从3开始的奇数序列
def _odd_iter():
n = 1while True:
n = n + 2yield n注意这是一个生成器,并且是一个无限序列。
定义一个筛选函数:
def _not_divisible(n):return lambda x: x % n > 0
最后,定义一个生成器,不断返回下一个素数:
def primes():yield 2it = _odd_iter() # 初始序列while True:n = next(it) # 返回序列的第一个数yield nit = filter(_not_divisible(n), it) # 构造新序列
这个生成器先返回第一个素数2,然后,利用filter()不断产生筛选后的新的序列。
由于primes()也是一个无限序列,所以调用时需要设置一个退出循环的条件:
for n in primes():if n < 1000:print(n)else:break
注意到Iterator是惰性计算的序列,所以我们可以用Python表示“全体自然数”,“全体素数”这样的序列,而代码非常简洁。
filter()的作用是从一个序列中筛出符合条件的元素。由于filter()使用了惰性计算,所以只有在取filter()结果的时候,才会真正筛选并每次返回下一个筛出的元素。
sorted
高阶函数:sorted([36, 5, -12, 9, -21], key=abs)
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
忽略大小写:只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写)
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)反向排序:
sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)sorted()也是一个高阶函数。用sorted()排序的关键在于实现一个映射函数。
返回函数
函数作为返回值。
def calc_sum(*args):ax = 0for n in args:ax = ax + nreturn ax
如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
def lazy_sum(*args):def sum():ax = 0for n in args:ax = ax + nreturn axreturn sum
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
>>> f = lazy_sum(1, 3, 5, 7, 9)
调用函数f时,才真正计算求和的结果:
在这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
>>> f1 = lazy_sum(1, 3, 5, 7, 9)
>>> f2 = lazy_sum(1, 3, 5, 7, 9)
>>> f1==f2
False闭包
注意到返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以,闭包用起来简单,实现起来可不容易
返回的函数并没有立刻执行,而是直到调用了f()才执行。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行
def count():fs = []for i in range(1, 4):def f():return i*ifs.append(f)return fsf1, f2, f3 = count()
每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:
全部都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count():def f(j):def g():return j*jreturn gfs = []for i in range(1, 4):fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()return fs
返回一个函数时,牢记该函数并未执行,返回函数中不要引用任何可能会变化的变量。
匿名函数
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))匿名函数lambda x: x * x实际上就是:
def f(x):return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数
装饰器
函数对象有一个__name__属性,可以拿到函数的名字:
假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
decorator就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的decorator,可以定义如下:
def log(func):def wrapper(*args, **kw):print('call %s():' % func.__name__)return func(*args, **kw)return wrapper
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:
@logdef now():print('2015-3-25')
把@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:
def log(text):def decorator(func):def wrapper(*args, **kw):print('%s %s():' % (text, func.__name__))return func(*args, **kw)return wrapperreturn decorator
@log('execute')def now():print('2015-3-25')
偏函数
Partial function
int('12345', base=8)可以定义一个int2()的函数,默认把base=2传进去:
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools>>> int2 = functools.partial(int, base=2)>>> int2('1000000')64>>> int2('1010101')85
相当于
kw = { 'base': 2 }
int('10010', **kw)max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是
max2(5, 6, 7)相当于
args = (10, 5, 6, 7)max(*args)
模块
我们把很多函数分组,分别放到不同的文件里面。
自己在编写模块时,不必考虑名字会与其他模块冲突
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
方法是选择一个顶层包名,比如mycompany,
每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是mycompany。
使用模块
Mac或Linux上有可能并存Python 3.x和Python 2.x,因此对应的pip命令是pip3。
确保安装时勾选了pip和Add python.exe to Path。
pip install Pillow生成缩略图
>>> from PIL import Image>>> im = Image.open('test.png')>>> print(im.format, im.size, im.mode)PNG (400, 300) RGB>>> im.thumbnail((200, 100))>>> im.save('thumb.jpg', 'JPEG')
其他常用的第三方库还有MySQL的驱动:mysql-connector-python,用于科学计算的NumPy库:numpy,用于生成文本的模板工具Jinja2,等等。
当我们试图加载一个模块时,Python会在指定的路径下搜索对应的.py文件
Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中:
>>> import sys
>>> sys.path添加自己的目录:
- 修改sys.path
- 第二种方法是设置环境变量PYTHONPATH
面向对象编程
class Student(object):passclass后面紧接着是类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
bart = Student()
注意:特殊方法“init”前后有两个下划线!!!
class Student(object):def __init__(self, name, score):self.name = nameself.score = score
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
有了__init__方法,在创建实例的时候,就不能传入空的参数了,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去:
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数
访问限制
内部属性不被外部访问。把属性的名称前加上两个下划线__,
原先那种直接通过bart.score = 59也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数:
继承和多态
新的class称为子类(Subclass),而被继承的class称为基类、父类或超类(Base class、Super class)。
class Cat(Animal):
继承原来的代码,可以做一定改进。
子类的run()覆盖了父类的run()
多态:
因为Dog是从Animal继承下来的,当我们创建了一个Dog的实例c时,我们认为c的数据类型是Dog没错,但c同时也是Animal也没错,Dog本来就是Animal的一种!
当我们定义一个class的时候,我们实际上就定义了一种数据类型
在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类。但是,反过来就不行:
多态的好处就是,当我们需要传入Dog、Cat、Tortoise……时,我们只需要接收Animal类型就可以了,因为Dog、Cat、Tortoise……都是Animal类型,然后,按照Animal类型进行操作即可。由于Animal类型有run()方法,因此,传入的任意类型,只要是Animal类或者子类,就会自动调用实际类型的run()方法,这就是多态的意思:
对于一个变量,我们只需要知道它是Animal类型,无需确切地知道它的子类型,就可以放心地调用run()方法,而具体调用的run()方法是作用在Animal、Dog、Cat还是Tortoise对象上,由运行时该对象的确切类型决定,这就是多态真正的威力:调用方只管调用,不管细节,而当我们新增一种Animal的子类时,只要确保run()方法编写正确,不用管原来的代码是如何调用的。这就是著名的“开闭”原则:
对扩展开放:允许新增Animal子类;
对修改封闭:不需要修改依赖Animal类型的run_twice()等函数。
静态语言VS动态语言
对于静态语言(例如Java)来说,如果需要传入Animal类型,则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。
对于Python这样的动态语言来说,则不一定需要传入Animal类型。我们只需要保证传入的对象有一个run()方法就可以了:
这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子
获取对象信息
使用type()
果我们要在if语句中判断,就需要比较两个变量的type类型是否相同:
>>> type(fn)==types.FunctionTypeTrue>>> type(abs)==types.BuiltinFunctionTypeTrue>>> type(lambda x: x)==types.LambdaTypeTrue>>> type((x for x in range(10)))==types.GeneratorTypeTrue
isinstance()
object -> Animal -> Dog -> Husky>>> a = Animal()
>>> d = Dog()
>>> h = Husky()isinstance(h, Husky)>>> isinstance(h, Animal)
Truedir()
如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list,
比如__len__方法返回长度。在Python中,如果你调用len()函数试图获取一个对象的长度,实际上,在len()函数内部,它自动去调用该对象的__len__()方法,所以,下面的代码是等价的:
>>> len('ABC')3>>> 'ABC'.__len__()3
仅仅把属性和方法列出来是不够的,配合getattr()、setattr()以及hasattr(),我们可以直接操作一个对象的状态:
我们可以对任意一个Python对象进行剖析,拿到其内部的数据。要注意的是,只有在不知道对象信息的时候,我们才会去获取对象信息
可以用
sum = obj.x + obj.y就不要写:
sum = getattr(obj, 'x') + getattr(obj, 'y')假设我们希望从文件流fp中读取图像,我们首先要判断该fp对象是否存在read方法,如果存在,则该对象是一个流,如果不存在,则无法读取。hasattr()就派上了用场。
实例属性和类属性
>>> class Student(object):... name = 'Student'...>>> s = Student() # 创建实例s>>> print(s.name) # 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性Student>>> print(Student.name) # 打印类的name属性Student>>> s.name = 'Michael' # 给实例绑定name属性>>> print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性Michael>>> print(Student.name) # 但是类属性并未消失,用Student.name仍然可以访问Student>>> del s.name # 如果删除实例的name属性>>> print(s.name) # 再次调用s.name,由于实例的name属性没有找到,类的name属性就显示出来了Student
从上面的例子可以看出,在编写程序的时候,千万不要把实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
使用__slots__
class Student(object):pass
>>> s = Student()>>> s.name = 'Michael' # 动态给实例绑定一个属性>>> print(s.name)Michael
但是,给一个实例绑定的方法,对另一个实例是不起作用的:
为了给所有实例都绑定方法,可以给class绑定方法:
通常情况下,上面的set_score方法可以直接定义在class中,但动态绑定允许我们在程序运行的过程中动态给class加上功能,这在静态语言中很难实现。
但是如果想限制实例的属性
定义一个特殊的__slots__变量,来限制该class实例能添加的属性:
class Student(object):__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:
除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
访问数据库
在Mac或Linux上,需要编辑MySQL的配置文件,把数据库默认的编码全部改为UTF-8。MySQL的配置文件默认存放在/etc/my.cnf或者/etc/mysql/my.cnf:
[client]default-character-set = utf8[mysqld]default-storage-engine = INNODBcharacter-set-server = utf8collation-server = utf8_general_ci
mysql> show variables like '%char%';安装驱动:
pip install mysql-connector
# 导入MySQL驱动:>>> import mysql.connector# 注意把password设为你的root口令:>>> conn = mysql.connector.connect(user='root', password='password', database='test')>>> cursor = conn.cursor()# 创建user表:>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')# 插入一行记录,注意MySQL的占位符是%s:>>> cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'Michael'])>>> cursor.rowcount1# 提交事务:>>> conn.commit()>>> cursor.close()# 运行查询:>>> cursor = conn.cursor()>>> cursor.execute('select * from user where id = %s', ('1',))>>> values = cursor.fetchall()>>> values[('1', 'Michael')]# 关闭Cursor和Connection:>>> cursor.close()True>>> conn.close()
附件列表
也可以参见简书主页:https://www.jianshu.com/u/482f183ec380

 浙公网安备 33010602011771号
浙公网安备 33010602011771号