【2022-07-13】Python模块详解
python模块
模块简介
-
模块就是用一堆代码实现一些功能的代码的集合,通常一个或多个函数写在一个.py文件里,如果实现的功能过于复杂,那么就需要创建n个.py文件
这n个.py文件的集合就是模块。
-
通俗的讲,我们也可以把模块当成是一个工具包,要想使用这个工具包里面的工具,就需要导入这个模块。
模块的分类
-
Python中的模块可分为三类,分别是内置模块、第三方模块和自定义模块,相关介绍如下:
内置模块:
Python内置标准库中的模块,也是Python的官方模块,可直接导入程序供开发人员使用
第三方模块:
由非官方制作发布的、供给大众使用的Python模块,在使用之前需要开发人员先自行安装
自定义模块:
开发人员在程序编写的过程中自行编写的、存放功能性代码的.py文件
模块的表现形式
- py文件(py文件也可以称之为是模块文件)
- 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
- 已被编译为共享库或DLL的c或C++扩展
- 使用C编写并链接到python解释器的内置模块
导入模块语句 ------import语句
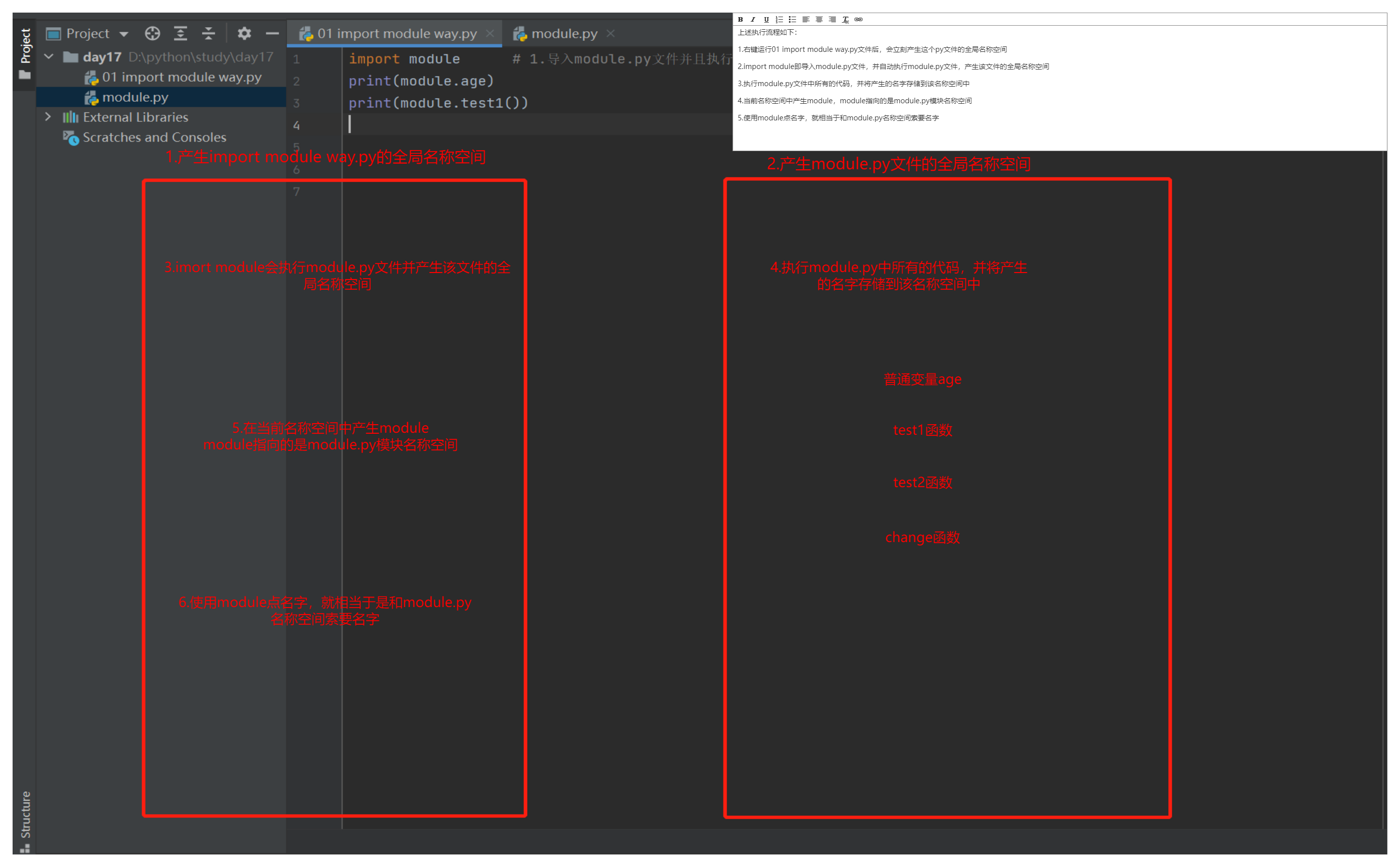
import module # 1.导入module.py文件并且执行 打印结果:my name is module
# print(module.age) # 18
# print(module.test1()) # from module.py test1 function
"""
上述执行流程如下:
1.先运行01 import module way.py文件后,会立刻产生这个py文件的全局名称空间
2.import module即导入module.py文件,并自动执行module.py文件,产生该文件的全局名称空间
3.执行module.py文件中所有的代码,并将产生的名字存储到该名称空间中
4.当前名称空间中产生module,module指向的是module.py模块名称空间
5.使用module点名字,就相当于和module.py名称空间索要名字
"""
# age = 25
# print(module.age) # my name is module 18
# print(age) # 25
# def test1():
# print('我是来自执行文件内的test1函数') # from module.py test2 function
# module.test2() # from module.py test1 function 18
# age = 28
# module.change()
# print(age) # 28
# print(module.age) # 23
补充说明
同一个程序反复导入相同的模块,导入语句只会执行一次
import module 执行有效
import module 执行无效
import module 执行无效
导入模块语句-----from.....import.....语句
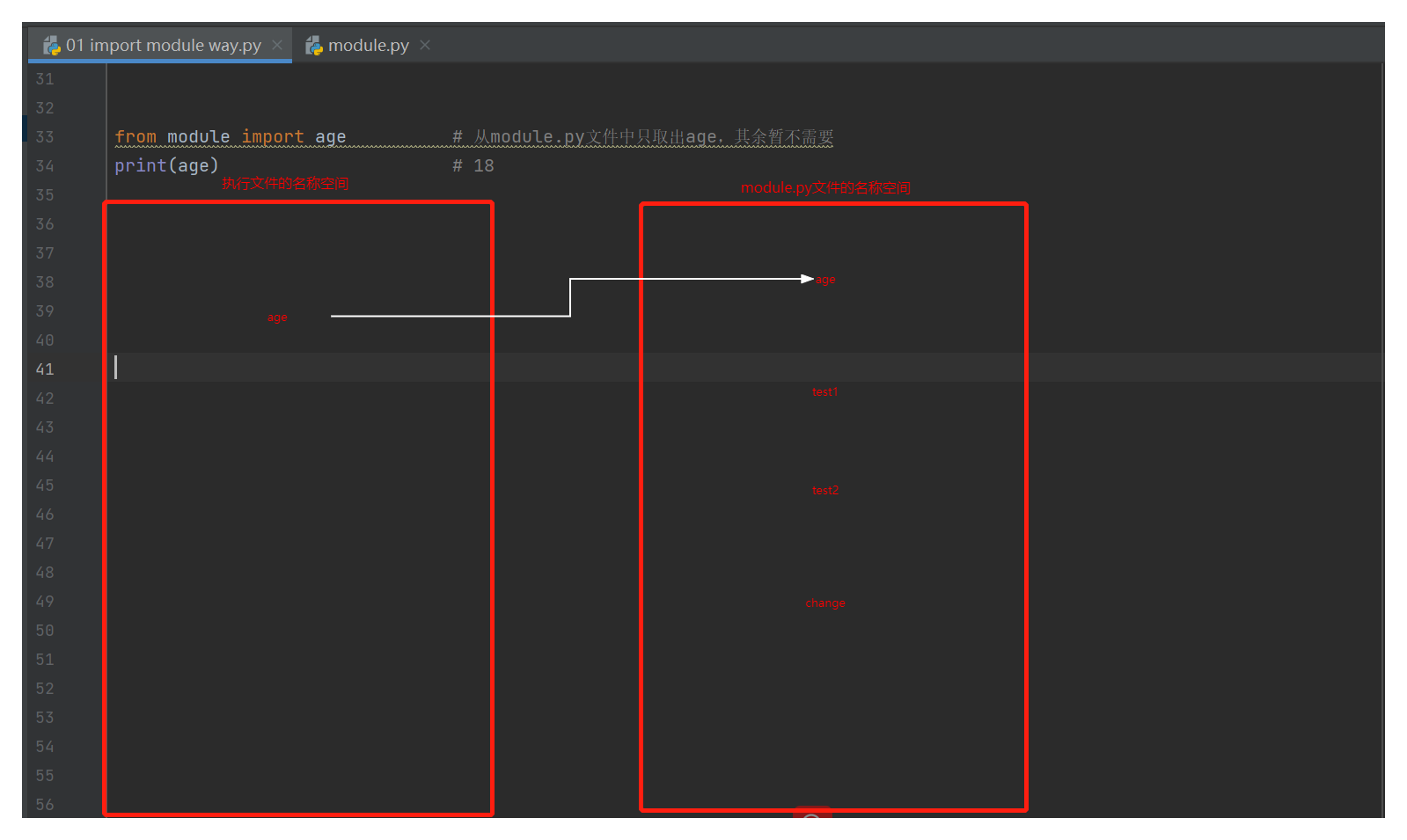
from module import age # 从module.py文件中只取出age,其余暂不需要
print(age) # 18
"""
上述语句执行流程如下:
1.首先运行01 import module way.py文件后,会立刻产生这个py文件的全局名称空间
2.运行from module import age代码后,立刻产生module.py的全局名称空间
3.开始执行module.py文件中的代码
4.此时执行文件的名称空间里只存放了age,并且指向了module.py文件中的age指向的值18
"""
# from module import age, test1
# test1() # from module.py test1 function
两种执行语句的优缺点
import module
优点:通过md点的方式可以使用到模块内所有的名字 并且不会冲突
缺点:md什么都可以点 有时候并不想让所有的名字都能被使用
from module import age, test1
优点:指名道姓的使用指定的名字 并且不需要加模块名前缀
缺点:名字及其容易产生冲突(绑定关系被修改)
循环导入问题
-
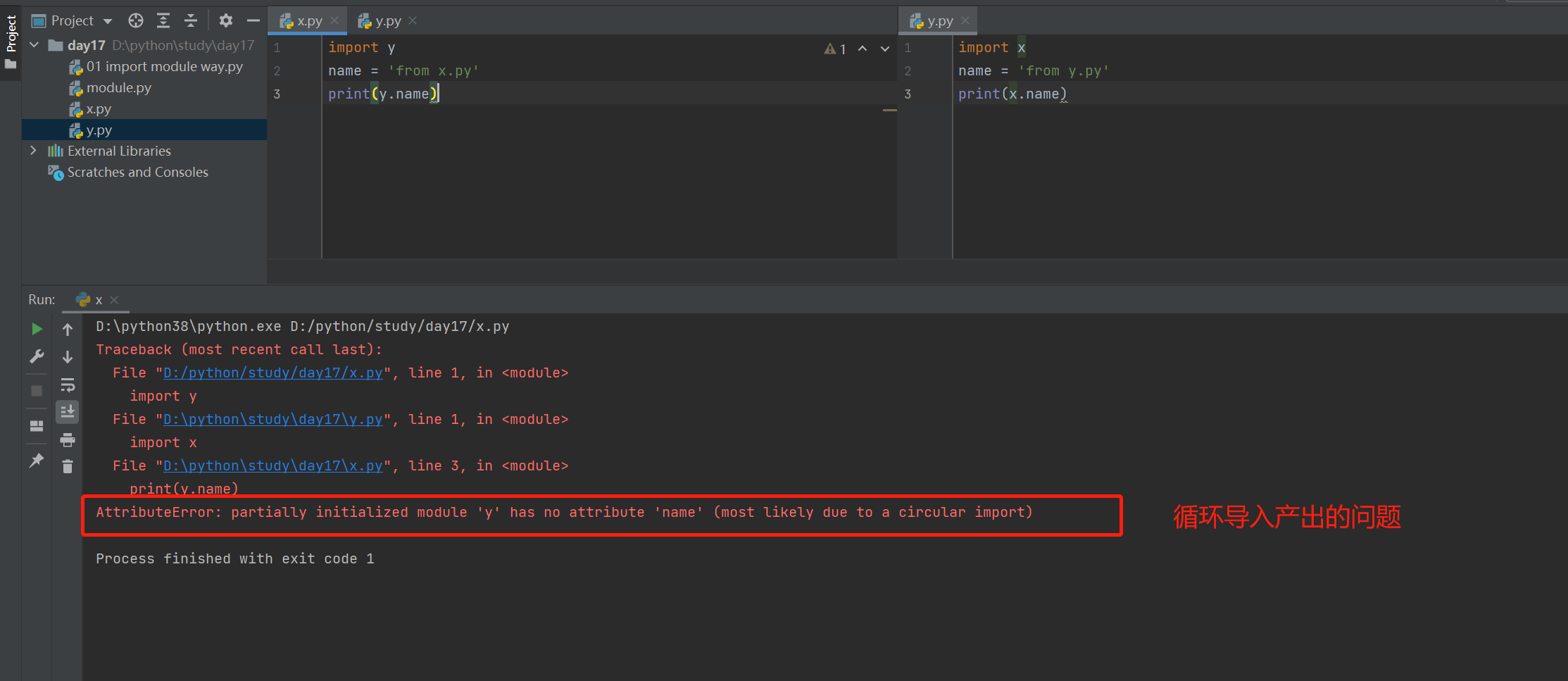
循环导入产生的问题
两个模块直接相互导入,且相互使用其名称空间中的名字,但是有些名字没有产生就使用,就出现了循环导入问题
-
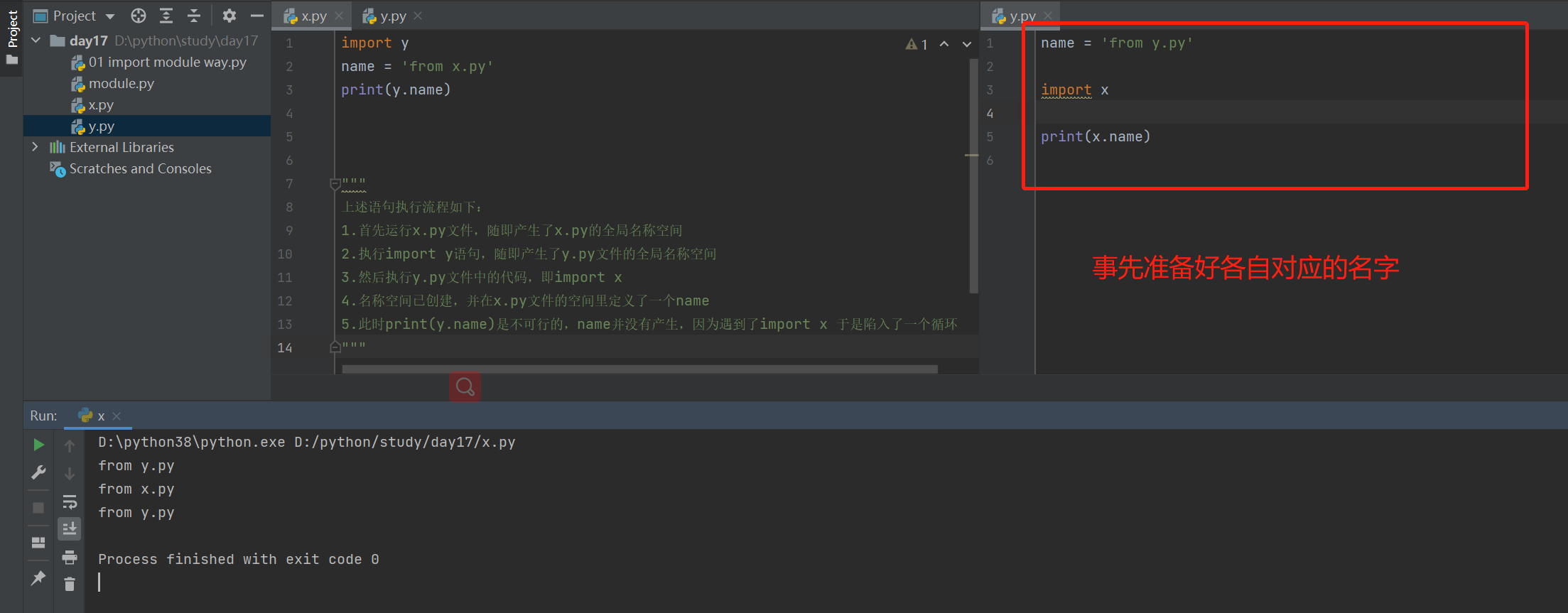
解决问题
延后导入,先产生对方要使用的名字,再去完成导入对方
import y import x
name = 'from x.py' name = 'from y.py'
print(y.name) print(x.name)
"""
上述语句执行流程如下:
1.首先运行x.py文件,随即产生了x.py的全局名称空间
2.执行import y语句,随即产生了y.py文件的全局名称空间
3.然后执行y.py文件中的代码,即import x
4.名称空间已创建,并在x.py文件的空间里定义了一个name
5.此时print(y.name)是不可行的,name并没有产生,因为遇到了import x 于是陷入了一个循环
"""
from导入马上会使用名字,极容易出现错误,建议循环导入情况下,使用import导入
先提前产生名字,在导入模块(先做饭,再出门)
在导入逻辑放在函数中,将导入的逻辑延后到函数的调用,只要调用在产生名字后即可
"""循环导入将来尽量避免出现!!! 如果真的避免不了 就想办法让所有的名字在使用之前提前准备好"""
判断文件类型
因为一个python文件,可以是执行文件,也可以是被导入文件,那么我们该如何来区分呢?python中通过__name__的内容来进行区分。
注意:
如果在执行文件中,name__的值是__main,并且是字符串类型。
如果作为模块时,__name__的值被赋予模块名。
作为模块的开发者,可以在文件末尾基于__name__在不同应用场景下的值的不同来控制文件执行不同的逻辑。
if __name__ == '__main__':
test.py被当做脚本执行时运行的代码
else:
test.py被当做模块导入时运行的代码
模块的查找顺序
-
模块的查找顺序:内存空间>>>内置模块>>>sys.path查找(类似于我们之前学过的环境变量)。如果这三个地方都没找到,会直接报错
-
导入模块的时候一定要清楚哪一个是执行文件,因为所有的路径都是参照文件来的
内存空间查找
import module
import time
time.sleep(7) # 程序在睡眠期间被删除
print(module.age) # 18
"""
执行删除操作前,文件已经写进了内存里,所以还能看到打印的结果,如果在执行一次就会直接报错
"""
内置模块查找
import time
print(time) # <module 'time' (built-in)> 打印的结果是内置time
print(time.time()) # 1657711015.7224374 获取时间戳
"""
创建py文件时,一定不要和模块名关键字(内置、第三方)发生冲突
"""
sys.path查找
import sys
print(sys.path)
"""
['D:\\python\\study\\day17',
'D:\\python\\study\\day17',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display',
'D:\\python38\\python38.zip',
'D:\\python38\\DLLs',
'D:\\python38\\lib',
'D:\\python38',
'D:\\python38\\lib\\site-packages',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
"""
"""
上述打印的结果是个列表,里面存放了很多路径,我们只需要从第一个路径中去查找就可以了,第一个其实就是执行文件所在的路径
"""
解决方法
方法一:
import sys
sys.path.append(r'D:\python\study\day17\xxx')
from xxx import time
print(time.name)
"""
sys.path是一个列表,所有我们可以使用append方法进行追加
之后把目标文件所在的路径添加到sys.path路径中就可以了
"""
方法二:
from xxx import time
print(time.name)
"""
使用from...import...句式指名道姓的查找
"""
分类:
python模块大全


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)