技术博客——PyPDF2 & Reportlab 使用
技术博客:PyPDF2 & Reportlab 使用
PyPDF2
PyPDF2包是在python中处理pdf的简易程序包,它包含了分割、合并、剪裁等对pdf的操作,可以满足对pdf操作的大部分需求,接下来就用几个例子对本程序包的几个功能进行介绍。
提取pdf文字
参考代码:
pdf = open("pdf.pdf", "rb")
reader = PyPDF2.PdfFileReader(pdf)
page = reader.getPage(0)
print(page.extractText())
识别实例:
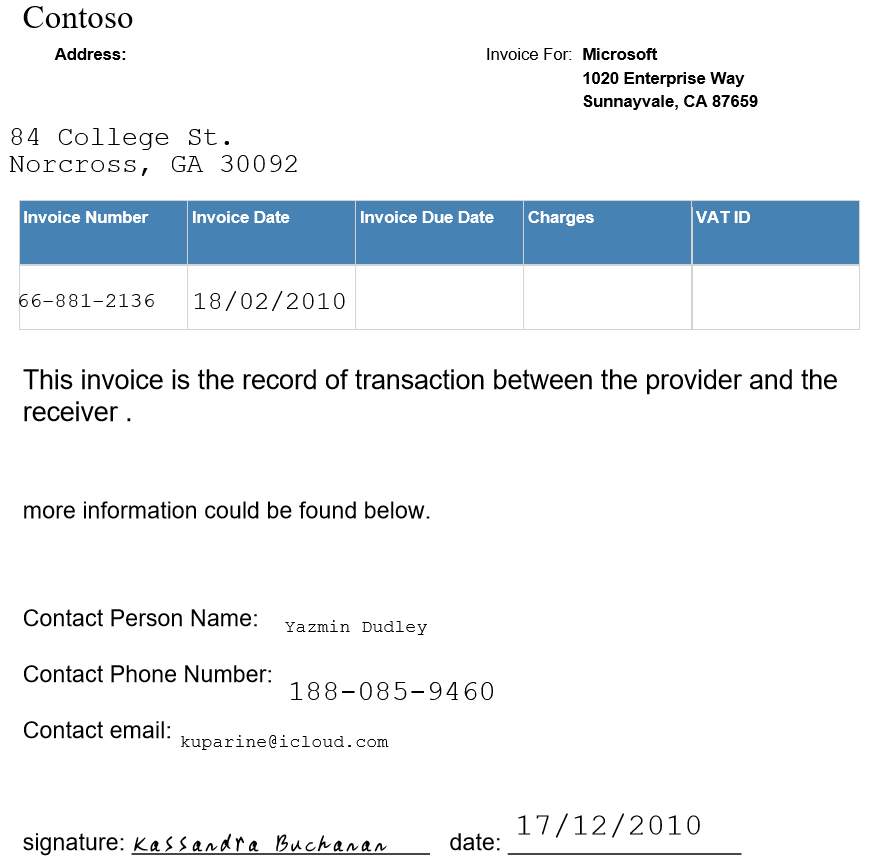
识别结果:
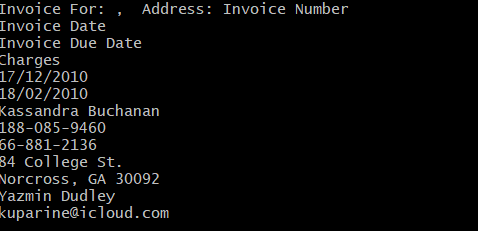
从上述实例中可以看出,比如date、电话号码等均被正确识别,但是也有一些内容是无法识别到的,比如字段名字。而上述内容几乎都是比较规整的,却没有识别出来,可见本功能的鲁棒性较差,仅能识别一些较为简单的pdf中的text内容。
合并pdf文件
参考代码:
merger = PdfFileMerger()
input1 = open('pdf1.pdf', 'rb')
input2 = open('pdf2.pdf', 'rb')
merger.append(fileobj=input1)
merger.merge(position=2, fileobj=input2)
output = open('document-output.pdf', 'wb')
merger.write(output)
output.close()
合并实例:


合并结果:

可以看出,本功能是直接将两个不同的pdf合并到一起,如果不设置page参数的话,就会将所选择的pdf按顺序把所有页合并,设置page参数之后可以选择部分合并。本功能主要用途在于需要批量合并某些同类型表格时,不需使用pdf合并工具一个个去点,省时省力。
但本功能的缺点也在上述实例中体现了出来,就是合并两个不同大小的pdf时,本函数包会直接将其合并,而不会调整到同样大小。
本功能除了合并,也可以直接取某个pdf的部分page,达到删除的效果
pdf添加水印
参考代码:
reader = PyPDF2.PdfFileReader(open('pdf1.pdf', 'rb'))
watermark = PyPDF2.PdfFileReader(open('pdf2.pdf', 'rb'))
writer = PyPDF2.PdfFileWriter() # 写入PDF的对象
page = reader.getPage(0)
page.mergePage(watermark.getPage(0))
writer.addPage(page)
outputStream = open('output.pdf', 'wb')
writer.write(outputStream)
outputStream.close()
添加结果:

上述添加水印的实例与合并pdf部分相同,故不作展示。可以看出,本功能是比较实用的。首先,对pdf自动化添加水印,可以使得pdf的版权轻松得到保护,其次,如果需要自动化修改pdf中的内容,可以通过添加水印的方式,直接覆盖原pdf的内容,达到修改的目的。
本次项目中,所使用的修改方式就是通过直接覆盖原pdf的内容,来进行修改。首先给定一个含有内容的表格,根据前端识别好的位置进行相应的计算。这里值得一提的是,pdf自动生成不一定是letter的大小,即A4大小,而本大小为此程序包的默认大小。所以需要通过调整页面大小来计算相对位置,从而使需要添加的水印在正确的地方。在计算位置时,默认的单位为inch,可以通过导入cm来进行修改,更符合编程者的习惯。
总结
本函数包中主要功能为以上几种,可以覆盖到常见所需的处理pdf方法,所以还是十分强大的。同时,它还包含一些细节的功能,比如对pdf进行旋转等,这里不一一介绍。
在本团队的项目中,数据生成部分的展示功能主要使用本包进行pdf的自动化修改。虽然由于beta阶段的任务难度增大,部分生成信息无法直接获知,需要进行位置计算等相应操作。这里需要使用其它对于界面的操作来为本项目的数据生成工作进行辅助,所以我选用了reportlab
Reportlab
本项目使用到程序包中的canvas部分的功能,所以仅介绍canvas相关函数。
pdf文本生成
参考代码:
c = canvas.Canvas("hello.pdf")
c.drawString(100,100,"Hello World")
c.showPage()
c.save()
生成结果:

如图所示,可以通过canvas这个画布功能,生成pdf的文字,根据其中的一些调整位置的函数,可以把想要生成的文字放到不同位置,并且可以改变生成文字的字体大小、颜色、字体种类等。本项目中,需要生成姓名,性别,地址等文本,本功能都可以满足要求。
pdf图形生成
除了生成本文,本程序包还可以生成图形,从而更好的辅助数据的生成。比如可以生成纯白色的方形来进行对已有文本的覆盖,再生成新的文本,从而实现对pdf的修改。
参考代码:
def create_watermark(content):
c = canvas.Canvas("mark.pdf", pagesize = (30*cm, 30*cm))
c.setStrokeColorRGB(1, 1, 0)
c.setFillColorRGB(1, 1, 0)
c.rect(10*cm, 10*cm, 7*cm, 17*cm, fill=1)
c.save()
create_watermark('walker')
生成结果:

如此,可以生成出常见的几何图形,经过组合可以变成各种形状,从而对pdf的生成有辅助作用。这其中最重要的作用就是生成白色图形进行文字覆盖,从而实现文字修改。
总结
本部分功能是对于数据生成的较为重要的部分,将传进来的文本信息进行可视化或是将pdf上的文本进行直接修改都是十分有用的。
其它一些辅助性功能包括坐标转换,页面旋转平移等不详细介绍。
本项目
本项目中实现空白表格pdf的文本生成以及有字表格pdf的文字修改。
首先需要根据读入pdf页面大小,创建空白画布以进行文字水印生成,代码如下:
c = canvas.Canvas(markpdf, pagesize=(float(page['/MediaBox'][2]), float(page['/MediaBox'][3])))
由于在空白Pdf中生成文本与有字pdf中文字修改,所做流程都可以是先生成一个空白矩形覆盖,再在空白矩形上生成相应文本,所以本部分将两者的实现合并,代码如下:
c.setStrokeColorRGB(1, 1, 1)
c.setFillColorRGB(1, 1, 1)
c.rect(leftx, -leftupy, xgap, -ygap, fill=1)
c.setFillColorRGB(0, 0, 0)
for subtext in text:
c.drawString(leftx, -position, subtext)
position += fontsize
上述流程实现了对水印pdf的生成,之后需要将水印pdf覆盖到读入的表格pdf中,这里使用到了前面提到的PyPDF2程序包,代码如下:
pdf_output = PdfFileWriter()
pdf_watermark = PdfFileReader(open(markpdf, 'rb'), strict=False)
page.mergePage(pdf_watermark.getPage(0))
page.compressContentStreams()
pdf_output.addPage(page)
pdf_output.write(open(outpdf, 'wb'))
如此,便可以在任意pdf表格上生成我们所需要的图形或者文本了。
总的来说,本项目用到的此部分技术性并没有那么强。但通过学习python中的对pdf自动处理,了解了一个比较实用的程序包,同时在调整pdf生成的文字的时候,需要比较强的耐心,所以本部分的学习还是十分有意义的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号