
一、集群模式
总结经验
redis主从:可实现高并发(读),典型部署方案:一主二从
redis哨兵:可实现高可用,典型部署方案:一主二从三哨兵
redis集群:可同时支持高可用(读与写)、高并发,典型部署方案:三主三从
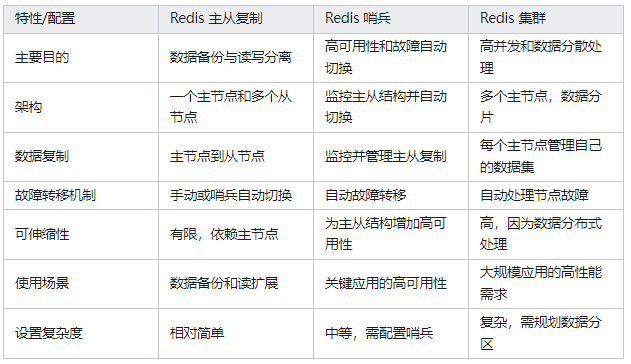

1.主从模式
优点:读写分离,一主多从,数据备份方便
缺点:无法自动切换主从,无法自动处理故障(无选取机制),无法动态伸缩
2.哨兵模式
进阶版主从模式,能自动处理故障
优点:
缺点:
3.cluster模式
优点:可以自动处理故障,自动切换主从,可以动态伸缩
搭建过程:
kubectl get endpoints -n redis 获取redis node ip
创建redis集群: redis-cli --cluster create 10.244.36.101:6379 10.244.36.102:6379 10.244.36.103:6379 10.244.36.104:6379 10.244.36.105:6379 10.244.36.106:6379 --cluster-replicas 1
二、配置文件
# 900秒(15分钟)内至少1个key值改变(则进行数据库保存--持久化) save 900 1 save <seconds> <changes> save "" 表示禁止rdb持久化,打开aof持久化
三、redis问题
1.脑裂
某个节点由于网络分区或者其他原因,与其他节点失去联系,想独立成为一个实例,从而导致数据不一致或其他问题。
解决方法通常包括以下几个步骤:
-
检查网络连接:确保所有节点之间的网络连接正常,没有防火墙或网络分裂问题。
-
检查集群配置:确保每个节点的
redis.conf文件中的集群配置正确,包括集群节点的地址和端口。 -
检查集群状态:使用
redis-cli工具的CLUSTER INFO和CLUSTER NODES命令来检查集群的状态和节点信息。 -
解决网络分裂问题:如果发生了网络分裂,需要解决这个问题,可能需要手动干预,将分裂的节点重新连接到集群中。
-
数据一致性:在网络分裂问题解决后,确保通过数据恢复或其他手段,保证集群中各个节点的数据一致性。
-
监控和预警:设置监控系统,以便在未来发生类似问题时能够快速响应和解决。
三、数据
1.列表
列表的插入方向,左为头,右为尾。列表序号从0开始,方向从左开始
lpush key value1 value2 #从列表头插入键,列表[values2,values1] rpush key value1 value2 #从列表尾插入键,列表[values1, values2]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号