

一、控制器
1.Label与seletor
Labels就是一对key/vaule。被关联到对象上,对用户来说很有用,通过labels能够知道对象的意义。
通过Labels可以实现多维度的资源分组管理
示例:
"release" : "stable", "release" : "canary" "environment" : "dev","environment" : "qa","environment" : "production" "tier" : "frontend","tier" : "backend","tier" : "cache" "partition" : "customerA", "partition" : "customerB" "track" : "daily", "track" : "weekly"
1.1 Label key的组成
- 不得超过63个字符
- 可以使用前缀,使用/分隔,前缀必须是DNS子域,不得超过253个字符,系统中的自动化组件创建的label必须指定前缀,
kubernetes.io/由kubernetes保留 - 起始必须是字母(大小写都可以)或数字,中间可以有连字符、下划线和点
1.2 Label value的组成:
- 不得超过63个字符
- 起始必须是字母(大小写都可以)或数字,中间可以有连字符、下划线和点
1.3 seletor
1.3.1 equality-based: 可以使用=、==、!=操作符,可以使用逗号分隔多个表达式
environment = production tier != frontend 第一个选择所有key等于 environment 值为 production 的资源。后一种选择所有key为 tier 值不等于 frontend 的资源,和那些没有key为 tier 的label的资源。
1.4 使用场景
1 kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量,从而实现Pod副本的数量时钟符合预期设定的全自动控制流程 2 kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表,从而实现Service的只能负载均衡机制。 3 通过对某些Node定义特定的Label,并且在Pod定义文件中使用NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod“定向调度”的特性。
kubectl get node --selector=kubernetes.io/hostname=k8s-master
kubectl get po -A -l 'k8s-app in (metrics-server, kubernetes-dashboard)'
kubectl get po -l version!=1,app=nginx
kubectl get po -A -l version!=1,'app in (busybox, nginx)'
kubectl get po -A -l app=hello
2. 常规控制器
2.1 statefulset
2.2 deployment
只有修改了template中的内容,才会出发滚动更新操作。
1 kubectl create -f xxx.yaml --record 2 --record 会在 annotation 中记录当前命令创建或升级了资源,后续可以查看做过哪些变动操作。 3 4 滚动更新操作 5 查看滚动更新的过程 6 kubectl rollout status deploy <deployment_name> 7 8 9 回滚 10 默认情况下,kubernetes会在系统中保存前两次的Deployment的rollout历史记录,以便你可以随时会退(你可以修改revision history limit来更改保存的revision数)。 11 监控滚动升级状态,由于镜像名称错误,下载镜像失败,因此更新过程会卡住 12 kubectl rollout status deployments nginx-deploy 13 14 通过 kubectl rollout history deployment/nginx-deploy 可以获取 revison 的列表 15 16 通过 kubectl rollout history deployment/nginx-deploy --revision=2 可以查看详细信息 17 18 确认要回退的版本后,可以通过 kubectl rollout undo deployment/nginx-deploy 可以回退到上一个版本 19 20 也可以回退到指定的 revision 21 kubectl rollout undo deployment/nginx-deploy --to-revision=2 22 23 可以通过设置 .spec.revisonHistoryLimit 来指定 deployment 保留多少 revison,如果设置为 0,则不允许 deployment 回退了。 24 25 暂停滚动更新 26 kubectl rollout pause deployment <name> 就可以实现暂停 27 28 恢复滚动更新 29 kubectl rollout resume deploy <name>
二、网络
1.headliness service(特殊的service)
clusterIP:None,用户想自定义负载均衡,就可以采用此种方式。这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询(DNS解析到后端pod的地址)。
2.ingress
速记: 通过域名请求到ingress controller,然后根据ingress对象的转发规则转发到后端service上去, ingress分为两部分
- ingress对象: 未被转化的转发规则 例如nginx配置conf
- ingress controller: nginx程序,也可能是其他程序haproxy等,会对ingress对象的转发规则进行转化,如nginx.conf
- 举例说明: ingress controller pod部署在192.168.0.121节点上, 要想访问 service api-gateway的9000端口,则需要在本地/etc/hosts中加入dns解析: 192.168.0.121
api.wolfcode.cn,接着直接通过访问 http://api.wolfcode.cn即可。
- ingress对象配置如下:
-
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: api-gateway-ingress namespace: ks-shop-dev annotations: kubernetes.io/ingress.class: "nginx" nginx.ingress.kubernetes.io/rewrite-target: / spec: rules: - host: api.wolfcode.cn http: paths: - pathType: Prefix backend: service: name: api-gateway port: number: 9000 path: /
Service对集群之外暴露服务的主要方式有两种:NotePort和LoadBalancer,但是这两种方式,都有一定的缺点:
NodePort方式的缺点是会占用很多集群机器的端口,那么当集群服务变多的时候,这个缺点就愈发明显
LB方式的缺点是每个service需要一个LB,浪费、麻烦,并且需要kubernetes之外设备的支持
kubernetes提供了Ingress资源对象,Ingress只需要一个NodePort或者一个LB就可以满足暴露多个Service的需求。工作机制大致如下图表示:
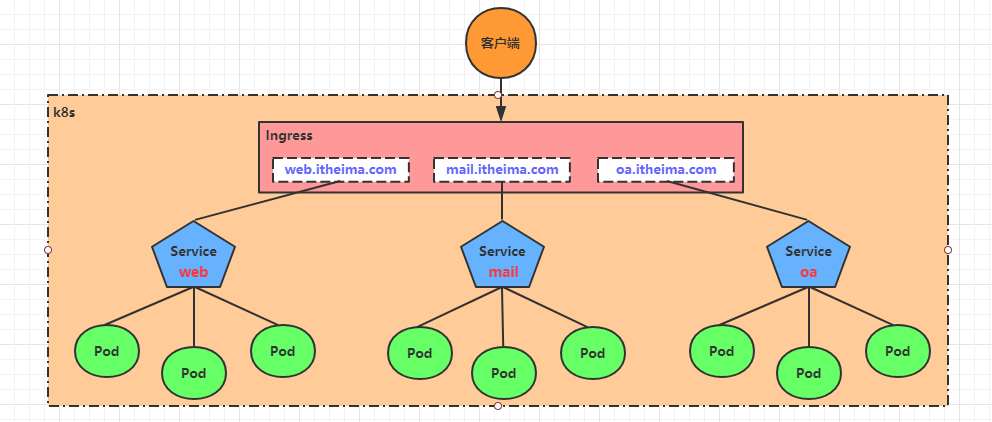
Ingress相当于一个7层的负载均衡器,是kubernetes对反向代理的一个抽象,它的工作原理类似于Nginx,可以理解成在Ingress里建立诸多映射规则,Ingress Controller通过监听这些配置规则并转化成Nginx的反向代理配置 , 然后对外部提供服务。在这里有两个核心概念:
- ingress:kubernetes中的一个对象,作用是定义请求如何转发到service的规则
- ingress controller:具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现方式有很多,比如Nginx, Contour, Haproxy等等
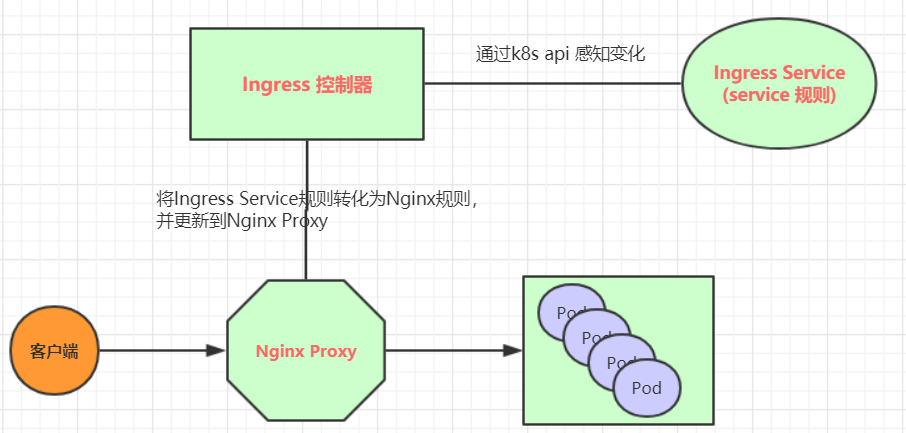
Ingress(以Nginx为例)的工作原理如下:
- 用户编写Ingress规则,说明哪个域名对应kubernetes集群中的哪个Service
- Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的Nginx反向代理配置
- Ingress控制器会将生成的Nginx配置写入到一个运行着的Nginx服务中,并动态更新
- 到此为止,其实真正在工作的就是一个Nginx了,内部配置了用户定义的请求转发规则
3.CNI网络插件
4.service
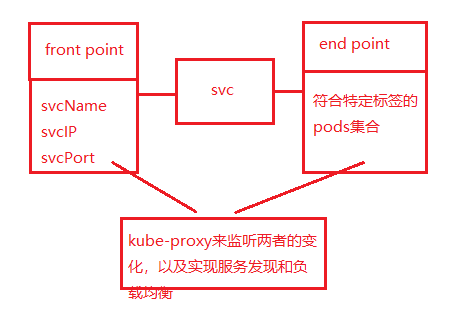
kube-proxy将clusterip的流量转发到后端pod上
4层负载均衡,通过kube-proxy实现反向代理和后端的负载均衡。
1.clusterIP(内网访问)
2.nodeport(外网访问) 将service的IP和端口映射到node节点的端口上(nat)
将service暴露在节点网络上,NodePort背后就是Kube-Proxy,Kube-Proxy是沟通service网络、Pod网络和节点网络的桥梁
测试环境使用还行,当有几十上百的服务在集群中运行时,NodePort的端口管理就是个灾难。 3.LB 在nodeport的基础上,集群外部的LB针对每个service都有一个负载均衡器。 4.externalName 负载均衡策略: 1.不指定,则是kube-proxy的默认策略,轮询或者随机 2.基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上
此模式可以使在spec中添加sessionAffinity:ClientIP选项
5.coredns
域名解析,相当于通过<svc-name>.<ns>.svc.cluster.local解析到clusterip
三、安装
1.cgroup driver
分为cgroupfs和systemd,两种对cgroup的资源
1.1 cgroupfs
Cgroup提供了一个原生接口并通过cgroupfs提供(从这句话我们可以知道cgroupfs就是Cgroup的一个接口的封装)。类似于procfs和sysfs,是一种虚拟文件系统。并且cgroupfs是可以挂载的,默认情况下挂载在/sys/fs/cgroup目录。
1.2 systemd
Systemd也是对于Cgroup接口的一个封装。systemd以PID1的形式在系统启动的时候运行,并提供了一套系统管理守护程序、库和实用程序,用来控制、管理Linux计算机操作系统资源。
1.3 为什么使用systemd而不是croupfs
引用下官方原话:
当某个 Linux 系统发行版使用 systemd 作为其初始化系统时,初始化进程会生成并使用一个 root 控制组(cgroup),并充当 cgroup 管理器。 Systemd 与 cgroup 集成紧密,并将为每个 systemd 单元分配一个 cgroup。 你也可以配置容器运行时和 kubelet 使用 cgroupfs。 连同 systemd 一起使用 cgroupfs 意味着将有两个不同的 cgroup 管理器。
单个 cgroup 管理器将简化分配资源的视图,并且默认情况下将对可用资源和使用 中的资源具有更一致的视图。 当有两个管理器共存于一个系统中时,最终将对这些资源产生两种视图。 在此领域人们已经报告过一些案例,某些节点配置让 kubelet 和 docker 使用 cgroupfs,而节点上运行的其余进程则使用 systemd; 这类节点在资源压力下 会变得不稳定。
ubuntu系统,debian系统,centos7系统,都是使用systemd初始化系统的。systemd这边已经有一套cgroup管理器了,如果容器运行时和kubelet使用cgroupfs,此时就会存在cgroups和systemd两种cgroup管理器。也就意味着操作系统里面存在两种资源分配的视图,当操作系统上存在CPU,内存等等资源不足的时候,操作系统上的进程会变得不稳定。
我们可以简单得理解为一山不要容二虎,一个国家只能有一个国王。
注意事项: 不要尝试修改集群里面某个节点的cgroup驱动,如果有需要,最好移除该节点重新加入。
1.4 如何修改docker默认的cgroup驱动
增加"exec-opts": ["native.cgroupdriver=systemd"]配置,重启docker即可
root@cfdcub7217s:~# cat /etc/docker/daemon.json {"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn","http://hub-mirror.c.163.com"],"max-concurrent-downloads": 10,"log-driver": "json-file","log-level": "warn","log-opts": {"max-size": "10m","max-file": "3"},"data-root": "/var/lib/docker" }
1.5 kubelet配置cgroup驱动
参考官方
说明: 在版本 1.22 中,如果用户没有在
KubeletConfiguration中设置cgroupDriver字段,kubeadm init会将它设置为默认值systemd。
# kubeadm-config.yaml kind: ClusterConfiguration apiVersion: kubeadm.k8s.io/v1beta3 kubernetesVersion: v1.21.0 --- kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 cgroupDriver: systemd 然后使用kubeadm初始化 kubeadm init --config kubeadm-config.yaml
四、存储
kubernetes的Volume支持多种类型,比较常见的有下面几个:
- 简单存储:EmptyDir、HostPath、NFS
- 高级存储:PV、PVC
- 配置存储:ConfigMap、Secret
共享存储,非持久化
EmptyDir是最基础的Volume类型,一个EmptyDir就是Host上的一个空目录。
EmptyDir是在Pod被分配到Node时创建的,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当Pod销毁时, EmptyDir中的数据也会被永久删除。 EmptyDir用途如下:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
hostPath(当前节点持久化)
volumes:
- name: logs-volume
hostPath:
path: /root/logs
type: DirectoryOrCreate # 目录存在就使用,不存在就先创建后使用
关于type的值的一点说明:
DirectoryOrCreate 目录存在就使用,不存在就先创建后使用
Directory 目录必须存在
FileOrCreate 文件存在就使用,不存在就先创建后使用
File 文件必须存在
Socket unix套接字必须存在
CharDevice 字符设备必须存在
BlockDevice 块设备必须存在NFS(远端) HostPath可以解决数据持久化的问题,但是一旦Node节点故障了,Pod如果转移到了别的节点,又会出现问题了,此时需要准备单独的网络存储系统,比较常用的用NFS、CIFS volumes: - name: logs-volume nfs: server: 192.168.5.6 #nfs服务器地址 path: /root/data/nfs #共享文件路径
高级存储
PV(Persistent Volume)是持久化卷的意思,是对底层的共享存储的一种抽象。一般情况下PV由kubernetes管理员进行创建和配置,它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对接。
PVC(Persistent Volume Claim)是持久卷声明的意思,是用户对于存储需求的一种声明。换句话说,PVC其实就是用户向kubernetes系统发出的一种资源需求申请。
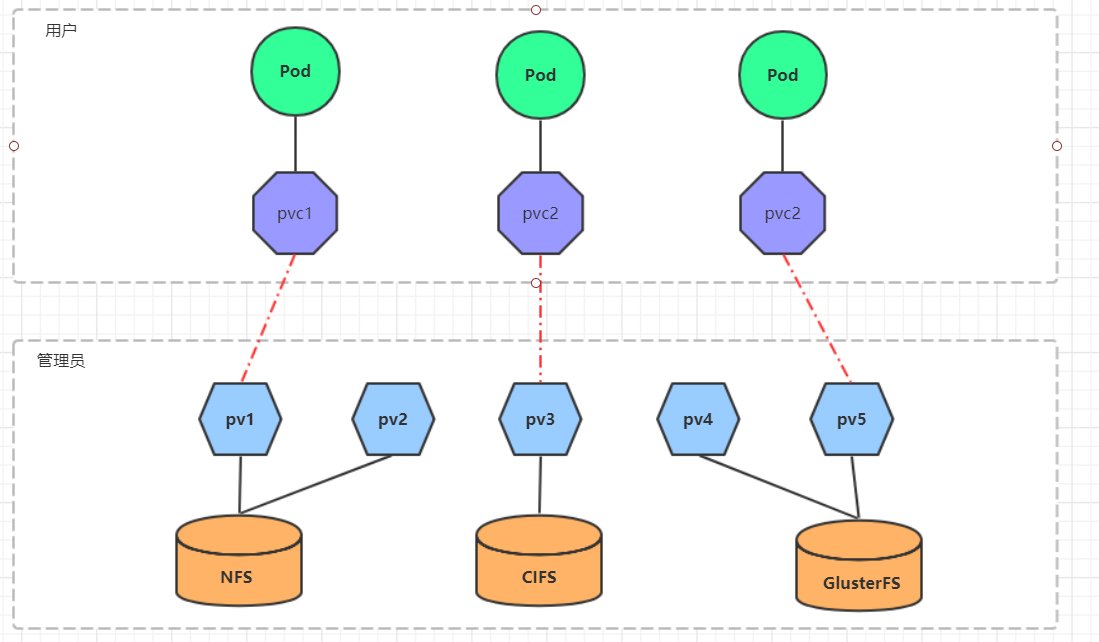
使用了PV和PVC之后,工作可以得到进一步的细分:
- 存储:存储工程师维护
- PV: kubernetes管理员维护
- PVC:kubernetes用户维护
五、健康检查
1.启动探针(startupprob)
用于启动时间大于30s的老应用
2.就绪探针(readinessprob)
service后端就绪,流量就绪
3.保活探针(livenessprob)
失败就会重启容器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号