
使用dlib进行人脸检测和关键点-python版
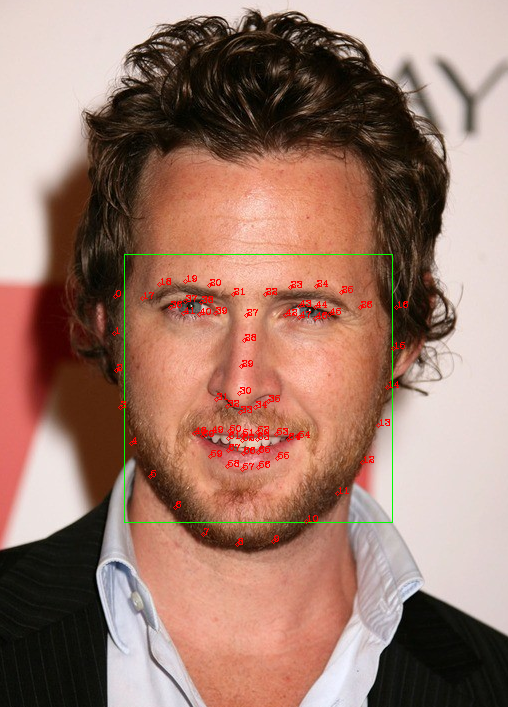
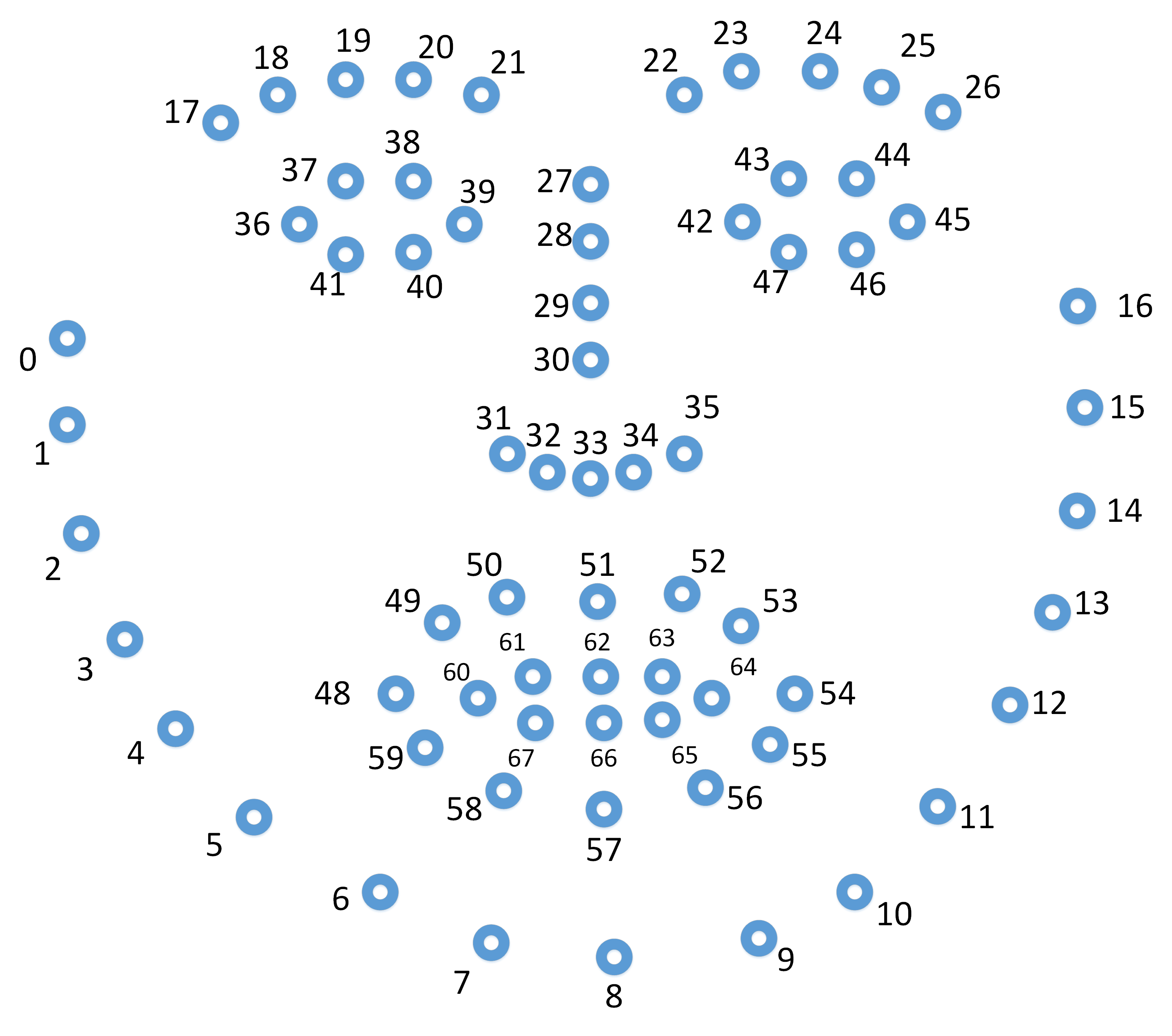
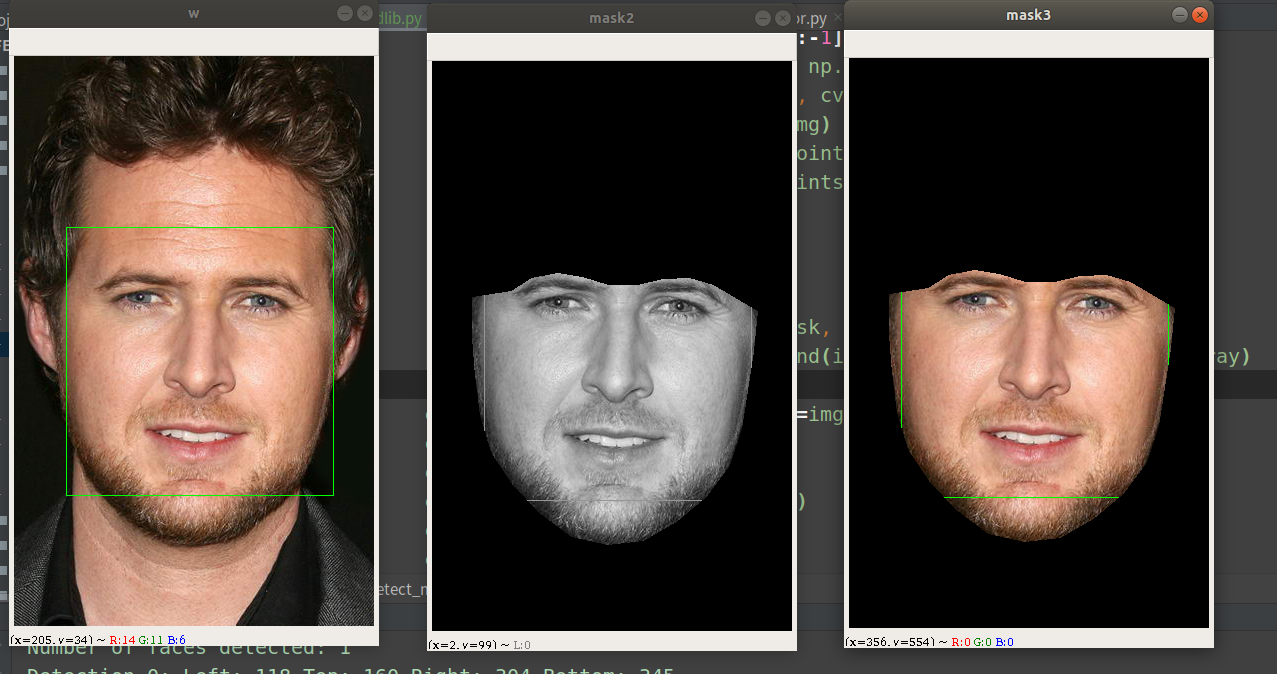
#!/usr/bin/env python # -*- coding:utf-8-*- # file: {NAME}.py # @author: jory.d # @contact: dangxusheng163@163.com # @time: 2020/04/10 19:42 # @desc: 使用dlib进行人脸检测和人脸关键点 import cv2 import numpy as np import glob import dlib FACE_DETECT_PATH = '/home/build/dlib-v19.18/data/mmod_human_face_detector.dat' FACE_LANDMAKR_5_PATH = '/home/build/dlib-v19.18/data/shape_predictor_5_face_landmarks.dat' FACE_LANDMAKR_68_PATH = '/home/build/dlib-v19.18/data/shape_predictor_68_face_landmarks.dat' def face_detect(): root = '/media/dangxs/E/Project/DataSet/VGG Face Dataset/vgg_face_dataset/vgg_face_dataset/vgg_face_dataset' imgs = glob.glob(root + '/**/*.jpg', recursive=True) assert len(imgs) > 0 detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor(FACE_LANDMAKR_68_PATH) for f in imgs: img = cv2.imread(f) # The 1 in the second argument indicates that we should upsample the image # 1 time. This will make everything bigger and allow us to detect more # faces. dets = detector(img, 1) print("Number of faces detected: {}".format(len(dets))) for i, d in enumerate(dets): x1, y1, x2, y2 = d.left(), d.top(), d.right(), d.bottom() print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format( i, x1, y1, x2, y2)) cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 1) # Get the landmarks/parts for the face in box d. shape = predictor(img, d) print("Part 0: {}, Part 1: {} ...".format(shape.part(0), shape.part(1))) # # Draw the face landmarks on the screen. ''' # landmark 顺序: 外轮廓 - 左眉毛 - 右眉毛 - 鼻子 - 左眼 - 右眼 - 嘴巴 ''' for i in range(shape.num_parts): x, y = shape.part(i).x, shape.part(i).y cv2.circle(img, (x, y), 2, (0, 0, 255), 1) cv2.putText(img, str(i), (x, y), cv2.FONT_HERSHEY_COMPLEX, 0.3, (0, 0, 255), 1) cv2.resize(img, dsize=None, dst=img, fx=2, fy=2) cv2.imshow('w', img) cv2.waitKey(0) def face_detect_mask(): root = '/media/dangxs/E/Project/DataSet/VGG Face Dataset/vgg_face_dataset/vgg_face_dataset/vgg_face_dataset' imgs = glob.glob(root + '/**/*.jpg', recursive=True) assert len(imgs) > 0 detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor(FACE_LANDMAKR_68_PATH) for f in imgs: img = cv2.imread(f) # The 1 in the second argument indicates that we should upsample the image # 1 time. This will make everything bigger and allow us to detect more # faces. dets = detector(img, 1) print("Number of faces detected: {}".format(len(dets))) for i, d in enumerate(dets): x1, y1, x2, y2 = d.left(), d.top(), d.right(), d.bottom() print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format( i, x1, y1, x2, y2)) cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 1) # Get the landmarks/parts for the face in box d. shape = predictor(img, d) print("Part 0: {}, Part 1: {} ...".format(shape.part(0), shape.part(1))) # # Draw the face landmarks on the screen. ''' # landmark 顺序: 外轮廓 - 左眉毛 - 右眉毛 - 鼻子 - 左眼 - 右眼 - 嘴巴 ''' points = [] for i in range(shape.num_parts): x, y = shape.part(i).x, shape.part(i).y if i < 26: points.append([x, y]) # cv2.circle(img, (x, y), 2, (0, 0, 255), 1) # cv2.putText(img, str(i), (x,y),cv2.FONT_HERSHEY_COMPLEX, 0.3 ,(0,0,255),1) # 只把脸切出来 points[17:] = points[17:][::-1] points = np.asarray(points, np.int32).reshape(-1, 1, 2) img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) black_img = np.zeros_like(img) cv2.polylines(black_img, [points], 1, 255) cv2.fillPoly(black_img, [points], (1, 1, 1)) mask = black_img masked_bgr = img * mask # 位运算时需要转化成灰度图像 mask_gray = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY) masked_gray = cv2.bitwise_and(img_gray, img_gray, mask=mask_gray) cv2.resize(img, dsize=None, dst=img, fx=2, fy=2) cv2.imshow('w', img) cv2.imshow('mask', mask) cv2.imshow('mask2', masked_gray) cv2.imshow('mask3', masked_bgr) cv2.waitKey(0) if __name__ == '__main__': face_detect()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号