
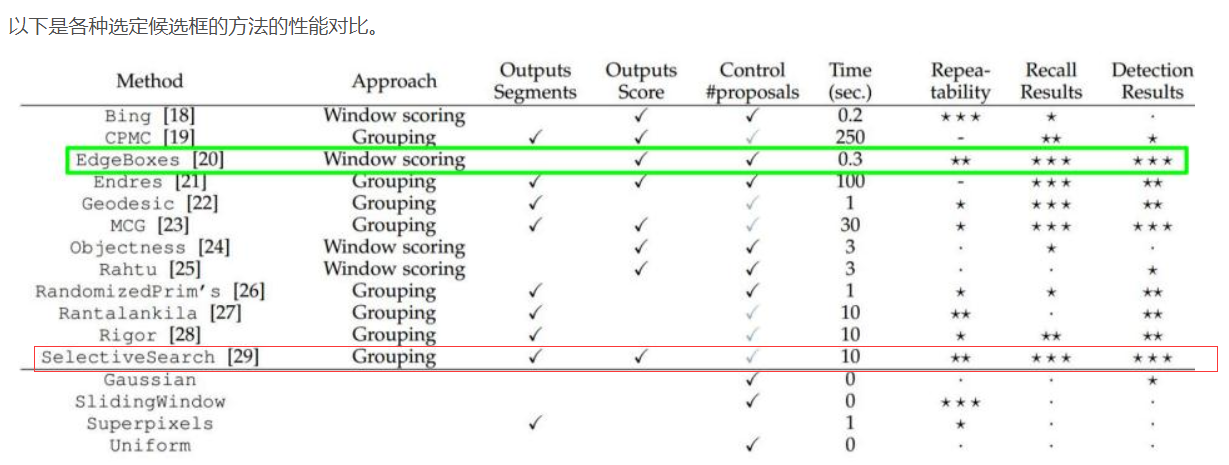
目标检测: R-CNN原理
论文地址:
1 selective search: https://arxiv.org/pdf/1502.05082.pdf
2 r-cnn: https://arxiv.org/pdf/1311.2524.pdf
1 概述:
为了降低滑动窗口导致的时间消耗, 采用selective search 方法来定位含有目标的候选框, 大约2k个, 然后再原图上按照这2k个框去切出来, 依次进行CNN训练
[selective search]解释: 预先找出图中目标可能出现的位置,即候选区域(Region Proposal)。利用图像中的纹理、边缘、颜色等信息,可以保证在选取较少窗口(几千甚至几百)的情况下保持较高的召回率(Recall)(这个博客有较好的解释: https://sevenold.github.io/2019/04/object-detection-RCNN/)
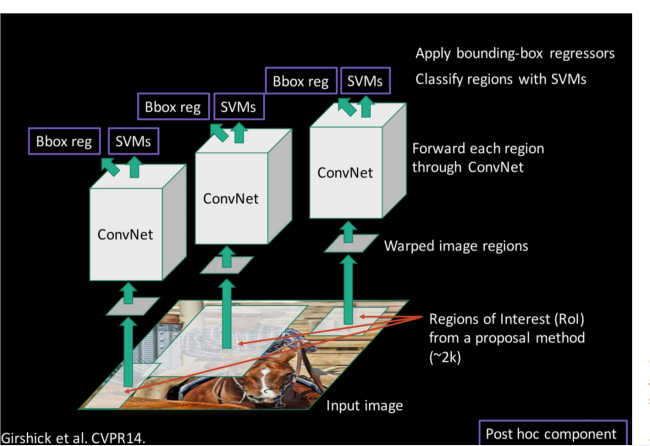
2 步骤:
2.1 在imagenet上预训练一个分类CNN
2.2 使用selective search方法切出图像上所有图片
2.3 将切出来的图片resize到统一尺寸
2.4 采用预训练出来的CNN进行fine-tune, 总输出类别为N+1, 1表示背景, 此时需要用较小的lr(0.001), 训练好保存此CNN(IoU>=0.5作为正例, 其他为负例)
2.5 去掉2.4步训练出来的CNN的最后一个分类层, 将中间的一维特征向量作为输出, 将每一个候选区域图片经过此CNN, 输出特征向量存储到磁盘
2.5 将特征向量作为输入样本, 依次为每一个类别训练一个线性核SVM(正例为候选区域和真实区域的IoU>=0.3的候选区域, 其他作为负例)
2.6 使用线性回归损失训练目标的box的位置参数
box回归损失解释:
假设预测模型输出di(p), 其中p=(px,py,pw,ph)为候选区域的中心点坐标宽高, g=(gx,gy,gw,gh)为真实目标的中心点坐标宽高
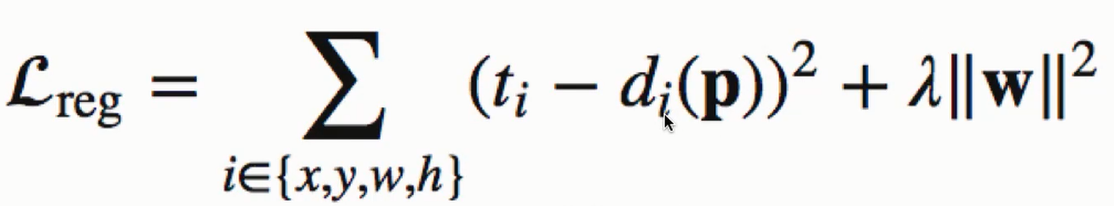

1 其中L2正则化超参的值是交叉验证确定的.
2 只有IoU>=0.6的候选区域才参与计算回归损失
3 缺点
3.1 selective search过程很慢
3.2 2k个区域里有很大重复, 信息冗余
3.3 4个模块(selective search, CNN, SVM, Regression)各自分离

 浙公网安备 33010602011771号
浙公网安备 33010602011771号