【rerdis】redis基础操作
一redis介绍
1.1NoSql
学名(not only sql) 特点: 存储结构与mysql这一种关系型数据库完全不同,nosql存储的是KV形式 nosql有很多产品,都有自己的api和语法,以及业务场景 产品种类: Mongodb redis Hbase hadoop
1.2Nosql和sql的区别
应用场景不同,sql支持关系复杂的数据查询,nosql反之
sql支持事务性,nosql不支持
1.3redis特性
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件 redis是c语言编写的,支持数据持久化,是key-value类型数据库。 应用在缓存,队列系统中 redis支持数据备份,也就是master-slave模
1.4redis优势
性能高,读取速度10万次每秒
写入速度8万次每秒
所有操作支持原子性
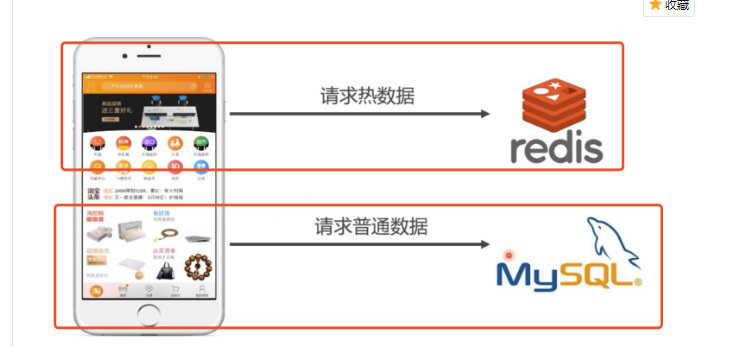
用作缓存数据库,数据放在内存中
替代某些场景下的mysql,如社交类app
大型系统中,可以存储session信息,购物车订单


二reids的安装
2.1yum安装
#前提得配置好阿里云yum源,epel源 #查看是否有redis包 yum list redis #安装redis yum install redis -y #安装好,启动redis systemctl start redis
#检测是否安装成功
redis-cli #redis 客户端工具 #进入交互式环境后,执行ping,返回pong表示安装成功 127.0.0.1:6379> ping PONG
2.2源码安装redis,编译安装
`2.1编译安装的优势是:
- 编译安装时可以指定扩展的module(模块),php、apache、nginx都是一样有很多第三方扩展模块,如mysql,编译安装时候,如果需要就定制存储引擎(innodb,还是MyIASM)
- 编译安装可以统一安装路径,linux软件约定安装目录在/opt/下面
- 软件仓库版本一般比较低,编译源码安装可以根据需求,安装最新的版
2.2redis的安装
1.下载redis源码 wget http://download.redis.io/releases/redis-4.0.10.tar.gz 2.解压缩 tar -zxf redis-4.0.10.tar.gz 3.切换redis源码目录 cd redis-4.0.10.tar.gz 4.编译源文件 make 5.编译好后,src/目录下有编译好的redis指令 6.make install 安装到指定目录,默认在/usr/local/bin
#redis可执行文件
./redis-benchmark //用于进行redis性能测试的工具 ./redis-check-dump //用于修复出问题的dump.rdb文件 ./redis-cli //redis的客户端 ./redis-server //redis的服务端 ./redis-check-aof //用于修复出问题的AOF文件 ./redis-sentinel //用于集群管理
注意事项:
此redis压缩包,已经提供好了makefile,只需要执行,编译的第二,第三曲
2.2redis的配置文件
redis.conf:
bind 192.168.16.142
protected-mode yes
port 6380
daemonize no
pidfile /var/run/redis_6379.pid
loglevel notice
requirepass 123456
常用参数解释
bind 192.168.16.142 #绑定redis启动的地址 protected-mode yes #开启redis的安全模式,必须输入密码才可以远程登录 port 6380 #指定redis的端口 daemonize no #让redis以守护进程方式在后台运行,不占用窗口 pidfile /var/run/redis_6379.pid #记录redis的进程id号的文件 loglevel notice #日志运行等级 .严重级别,警告级别,debug调试界别.....logging requirepass haohaio #设置redis的密码,是 haohaio
2.3Redis的启动
服务端
启动redis非常简单,直接./redis-server就可以启动服务端了,还可以用下面的方法指定要加载的配置文件: ./redis-server ../redis.conf 默认情况下,redis-server会以非daemon的方式来运行,且默认服务端口为6379
客户端
redis-cli -p 6380 -h 192.168.16.142
登录后进行(auth)密码验证,不然有些功能没有办法使用
三数据结构
redis是一种高级的key:value存储系统,其中value支持五种数据类型字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、
有序集合(sorted sets)
3.1基本命令
keys * 查看所有key type key 查看key类型 expire key seconds 过期时间 ttl key 查看key过期剩余时间 -2表示key已经不存在了 persist 取消key的过期时间 -1表示key存在,没有过期时间 exists key 判断key存在 存在返回1 否则0 del keys 删除key 可以删除多个 dbsize 计算key的数量
3.2strigs
set 设置key get 获取key append 追加string mset 设置多个键值对 mget 获取多个键值对 del 删除key incr 递增+1 decr 递减-1
eg:
127.0.0.1:6379> set name 'yu' #设置key OK 127.0.0.1:6379> get name #获取value "yu" 127.0.0.1:6379> set name 'yuchao' #覆盖key OK 127.0.0.1:6379> get name #获取value "yuchao" 127.0.0.1:6379> append name ' dsb' #追加key的string (integer) 10 127.0.0.1:6379> get name #获取value "yuchao dsb" 127.0.0.1:6379> mset user1 'alex' user2 'xiaopeiqi' #设置多个键值对 OK 127.0.0.1:6379> get user1 #获取value "alex" 127.0.0.1:6379> get user2 #获取value "xiaopeiqi" 127.0.0.1:6379> keys * #找到所有key 1) "user2" 2) "name" 3) "user1" 127.0.0.1:6379> mget user1 user2 name #获取多个value 1) "alex" 2) "xiaopeiqi" 3) "yuchao dsb" 127.0.0.1:6379> del name #删除key (integer) 1 127.0.0.1:6379> get name #获取不存在的value,为nil (nil) 127.0.0.1:6379> set num 10 #string类型实际上不仅仅包括字符串类型,还包括整型,浮点型。
redis可对整个字符串或字符串一部分进行操作,而对于整型/浮点型可进行自增、自减操作。 OK 127.0.0.1:6379> get num "10" 127.0.0.1:6379> incr num #给num string 加一 INCR 命令将字符串值解析成整型,将其加一,
最后将结果保存为新的字符串值,可以用作计数器 (integer) 11 127.0.0.1:6379> get num "11" 127.0.0.1:6379> decr num #递减1 (integer) 10 127.0.0.1:6379> decr num #递减1 (integer) 9 127.0.0.1:6379> get num "9"
3.3list
lpush 从列表左边插
rpush 从列表右边插
lrange 获取一定长度的元素 lrange key start stop
ltrim 截取一定长度列表
lpop 删除最左边一个元素
rpop 删除最右边一个元素
lpushx/rpushx key存在则添加值,不存在不处理
eg:
lpush duilie 'alex' 'peiqi' 'ritian' #新建一个duilie,从左边放入三个元素 llen duilie #查看duilie长度 lrange duilie 0 -1 #查看duilie所有元素 rpush duilie 'chaoge' #从右边插入chaoge lpushx duilie2 'dsb' #key存在则添加 dsb元素,key不存在则不作处理 ltrim duilie 0 2 #截取队列的值,从索引0取到2,删除其余的元素 lpop #删除左边的第一个 rpop #删除右边的第一个
3.4sets 集合类型
redis的集合,是一种无序的集合,集合中的元素没有先后顺序。集合相关的操作也很丰富,如添加新元素、删除已有元素、取交集、取并集、取差集等。我们来看例子:
sadd/srem 添加/删除 元素
sismember 判断是否为set的一个元素
smembers 返回集合所有的成员
sdiff 返回一个集合和其他集合的差异
sinter 返回几个集合的交集
sunion 返回几个集合的并集
eg:
sadd zoo wupeiqi yuanhao #添加集合,有三个元素,不加引号就当做字符串处理 smembers zoo #查看集合zoo成员 srem zoo wupeiqi #删除zoo里面的alex sismember zoo wupeiqi #返回改是否是zoo的成员信息,不存在返回0,存在返回1 sadd zoo wupeiqi #再把wupeiqi加入zoo smembers zoo #查看zoo成员 sadd zoo2 wupeiqi mjj #添加新集合zoo2 sdiff zoo zoo2 #找出集合zoo中有的,而zoo2中没有的元素 sdiff zoo2 zoo #找出zoo2中有,而zoo没有的元素 sinter zoo zoo1 #找出zoo和zoo1的交集,都有的元素 sunion zoo zoo1 #找出zoo和zoo1的并集,所有的不重复的元素
3.5有序集合
都是以z开头的命令用来保存需要排序的数据,例如排行榜,成绩,工资等。
实例:
利用有序集合的排序,
排序学生的成绩
127.0.0.1:6379> ZADD mid_test 70 "alex" (integer) 1 127.0.0.1:6379> ZADD mid_test 80 "wusir" (integer) 1 127.0.0.1:6379> ZADD mid_test 99 "yuyu"
运行:
1、移除有序集合mid_test中的成员,xiaofeng给移除掉
127.0.0.1:6379> ZREVRANGE mid_test 0 -1 withscores 1) "yuyu" 2) "99" 3) "wusir" 4) "80" 5) "xiaofneg" 6) "75" 7) "alex" 8) "70" 127.0.0.1:6379> ZRANGE mid_test 0 -1 withscores 1) "alex" 2) "70" 3) "xiaofneg" 4) "75" 5) "wusir" 6) "80" 7) "yuyu" 8) "99"
2、返回有序集合mid_test的基数
127.0.0.1:6379> ZCARD mid_test (integer) 3
3、返回成员的score值
127.0.0.1:6379> ZSCORE mid_test alex "70"
4、zrank返回有序集合中,成员的排名。默认按score,从小到大排序。
127.0.0.1:6379> ZRANGE mid_test 0 -1 withscores 1) "alex" 2) "70" 3) "wusir" 4) "80" 5) "yuyu" 6) "99" 127.0.0.1:6379> 127.0.0.1:6379> 127.0.0.1:6379> ZRANK mid_test wusir (integer) 1 127.0.0.1:6379> ZRANK mid_test yuyu (integer) 2
3.6哈希数据结构
哈希结构就是 k1 -> k1 : v1 如同字典 套字典 { k1 : { k2: v2 } } ,取出v2 必须 k1,取出k2
hashes即哈希。哈希是从redis-2.0.0版本之后才有的数据结构。
hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。、
hset 设置散列值
hget 获取散列值
hmset 设置多对散列值
hmget 获取多对散列值
hsetnx 如果散列已经存在,则不设置(防止覆盖key)
hkeys 返回所有keys
hvals 返回所有values
hlen 返回散列包含域(field)的数量
hdel 删除散列指定的域(field)
hexists 判断是否存在
redis hash是一个string类型的field和value的映射表 语法 hset key field value hset news1 title "first news title" #设置第一条新闻 news的id为1,添加数据title的值是"first news title" hset news1 content "news content" #添加一个conntent内容 hget news1 title #获取news:1的标题 hget news1 content #获取news的内容 hmget news1 title content #获取多对news:1的 值 hmset news2 title "second news title" content "second Contents2" #设置第二条新闻news:2 多个field hmget news2 title content #获取news:2的多个值 hkeys news1 #获取新闻news:1的所有key hvals news1 #获取新闻news:1的所有值 hlen news1 #获取新闻news:1的长度 hdel news1 title #删除新闻news:1的title hlen news1 #看下新闻news:1的长度 hexists news1 title #判断新闻1中是否有title,不存在返回0,存在返回1
四、reis的发布订阅
4.1相关概念

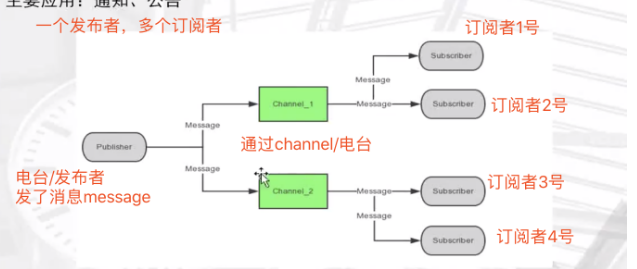
4.2发布订阅命令
PUBLISH channel msg 将信息 message 发送到指定的频道 channel SUBSCRIBE channel [channel ...] 订阅频道,可以同时订阅多个频道 UNSUBSCRIBE [channel ...] 取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道 PSUBSCRIBE pattern [pattern ...] 订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所 有以 it 开头的频道
( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有 以 news. 开头的频道( news.it 、 news.global.today 等等),
诸如此类 PUNSUBSCRIBE [pattern [pattern ...]] 退订指定的规则, 如果没有参数则会退订所有规则 PUBSUB subcommand [argument [argument ...]] 查看订阅与发布系统状态 注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,
必须Provider和Consumer同时在线。
4.3实现过程
窗口1,2,启动两个redis-cli窗口,均订阅 wang*频道(channel)
窗口1:
127.0.0.1:6379> PSUBSCRIBE wang* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "wang*" 3) (integer) 1
窗口2:
127.0.0.1:6379> PSUBSCRIBE wang* Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "wang*" 3) (integer) 1
窗口3,发布者消息
[root@web02 ~]# redis-cli 127.0.0.1:6379> PUBLISH wangbaoqiang "jintian zhennanshou " (integer) 2
五RDB 与AOF
5.1redis持久化
`Redis是一种内存型数据库,一旦服务器进程退出,数据库的数据就会丢失,为了解决这个问题,Redis提供了两种持久化的方案,将内存中的数据保存到磁盘中,避免数据的丢失。
5.2RDB持久化
redis提供了RDB持久化的功能,这个功能可以将redis在内存中的的状态保存到硬盘中,它可以手动执行。也可以再redis.conf中配置,定期执行。
RDB持久化产生的RDB文件是一个经过压缩的二进制文件,这个文件被保存在硬盘中,redis可以通过这个文件还原数据库当时的状态。
参数解析
dir /data/6379/ dbfilename dbmp.rdb 每过900秒 有1个操作就进行持久化 save 900秒 1个修改类的操作 save 300秒 10个操作 save 60秒 10000个操作 save 900 1 #每900秒至少有1个修改操作,save就会执行 save 300 10 #每300秒至少有10个修改操作,save就会执行
save 60 10000 #每60秒至少有10000个修改操作,save就会执行
代码
1、配置文件
daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 #定义持久化文件存储位置 dbfilename dbmp.rdb #rdb持久化文件 bind 10.0.0.10 127.0.0.1 #redis绑定地址 requirepass redhat #redis登录密码 save 900 1 save 300 10 save 60 10000
2、创建文件/data/6379
3、启动redis服务端
redis-server redis.conf
4、登录redis设置一个key
redis-cli -a redhat
5、.通过save触发持久化,将数据写入RDB文件
127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> save OK
5.3AOF
记录服务器执行的所有变更操作命令(例如set del等),并在服务器启动时,通过重新执行这些命令来还原数据集
AOF 文件中的命令全部以redis协议的格式保存,新命令追加到文件末尾。
优点:最大程序保证数据不丢
缺点:日志记录非常大
redis-client 写入数据 > redis-server 同步命令 > AOF文件
配置参数:
AOF持久化配置,两条参数
appendonly yes
appendfsync always 总是修改类的操作
everysec 每秒做一次持久化
no 依赖于系统自带的缓存大小机制
启动redis服务
redis-server /etc/redis.conf
检查redis数据目录/data/6379/是否产生了aof文件
[root@web02 6379]# ls
appendonly.aof dbmp.rdb redis.log
登录redis-cli,写入数据,实时检查aof文件信息
[root@web02 6379]# tail -f appendonly.aof
设置新key,检查aof信息,然后关闭redis,检查数据是否持久化
redis-cli -a redhat shutdown redis-server /etc/redis.conf redis-cli -a redhat
5.4总结
redis 持久化方式有哪些?有什么区别?
rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
六 redis不重启切换RDB到AOF的备份
6.1确保redis版本在2.2以上
[root@pyyuc /data 22:23:30]#redis-server -v Redis server v=4.0.10 sha=00000000:0 malloc=jemalloc-4.0.3 bits=64 build=64cb6afcf41664c
6.2实验环境准备
1、redis.conf服务端配置文件
daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 dbfilename dbmp.rdb save 900 1 #rdb机制 每900秒 有1个修改记录 save 300 10 #每300秒 10个修改记录 save 60 10000 #每60秒内 10000修改记录
2、启动redis服务端
redis-server redis.conf
3、登录redis-cli插入数据,手动持久化
127.0.0.1:6379> set name chaoge OK 127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> set addr shahe OK 127.0.0.1:6379> save OK
4、检查RDB文件
[root@pyyuc /data 22:34:16]#ls 6379/ dbmp.rdb redis.log
5、备份这个rdb文件,保证数据安全
[root@pyyuc /data/6379 22:35:38]#cp dbmp.rdb dbmp.rdb.bak
6、执行命令,开启AOF持久化
127.0.0.1:6379> CONFIG set appendonly yes #开启AOF功能 OK 127.0.0.1:6379> CONFIG SET save "" #关闭RDB功能 OK
7、确保数据库的key数量正确
127.0.0.1:6379> keys * 1) "addr" 2) "age" 3) "name"
8、确保插入新的key,AOF文件会记录
127.0.0.1:6379> set title golang
OK
9、修改redis.conf文件
daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379
appendonly yes
appendfsync everysec
七、redis安全设置
在使用云服务器时,安装的redis3.0+版本都关闭了protected-mode,因而都遭遇了挖矿病毒的攻击,使得服务器99%的占用率!!因此我们在使用redis时候,最好更改默认端口,并且使用redis密码登录。
(1)redis没有用户概念,redis只有密码
(2)redis默认在工作在保护模式下。不允许远程任何用户登录的(protected-mode)
1、redis.conf设置
protected-mode yes #打开保护模式 port 6380 #更改默认启动端口 requirepass xxxxxx #设置redis启动密码,xxxx是自定义的密码
2、启动redis服务端
redis-server /opt/redis-4.0.10/redis.conf & #指定配置文件启动redis,且后台启动
3、使用密码登录redis,使用6380端口
方法一:
[root@oldboy_python ~ 09:48:41]#redis-cli -p 6380 127.0.0.1:6380> auth xxxx OK
方法二:此方案不安全,容易暴露密码
[root@oldboy_python ~ 09:49:46]#redis-cli -p 6380 -a xxxx Warning: Using a password with '-a' option on the command line interface may not be safe. 127.0.0.1:6380> ping PONG
4、补充
127.0.0.1:6380> CONFIG get requirepass 1) "requirepass" 2) "xxxxxx"
八redis主从同步
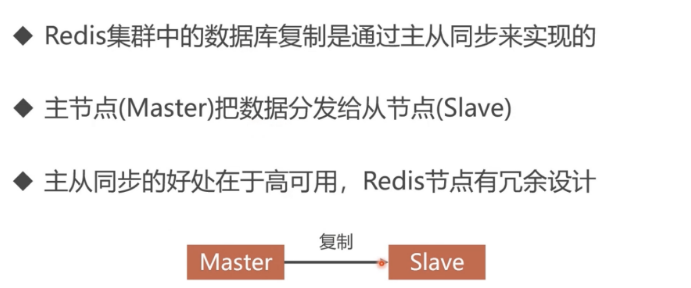
原理:
1. 从服务器向主服务器发送 SYNC 命令。
2. 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
3. 当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
4. 主服务器将缓冲区储存的所有写命令发送给从服务器执行。
------------
1、在开启主从复制的时候,使用的是RDB方式的,同步主从数据的
2、同步开始之后,通过主库命令传播的方式,主动的复制方式实现
3、2.8以后实现PSYNC的机制,实现断线重连
1、环境准备
1、环境: 准备两个或两个以上redis实例 mkdir /data/638{0..2} #创建6380 6381 6382文件夹 配置文件示例:
vim /data/6380/redis.conf port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 protected-mode no
vim /data/6381/redis.conf port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dbfilename dump.rdb dir /data/6381 protected-mode no
vim /data/6382/redis.conf
port 6382 daemonize yes pidfile /data/6382/redis.pid loglevel notice logfile "/data/6382/redis.log" dbfilename dump.rdb dir /data/6382 protected-mode no
2、启动三个redis实例
redis-server /data/6380/redis.conf redis-server /data/6381/redis.conf redis-server /data/6382/redis.conf
3、主从规划
主节点:6380
从节点:6381、6382
4、配置主从同步
6381/6382命令行 redis-cli -p 6381 SLAVEOF 127.0.0.1 6380 #指明主的地址 redis-cli -p 6382 SLAVEOF 127.0.0.1 6380 #指明主的地址
检查主从状态
127.0.0.1:6382> info replication
127.0.0.1:6381> info replication
127.0.0.1:6381> info replication
5、测试写入数据、主库写入数据,检查从库数据
主 127.0.0.1:6380> set name chaoge 从 127.0.0.1:6381>get name
7、 手动进行主从复制故障切换
#关闭主库6380 redis-cli -p 6380 shutdown
# 检查从库信息
redis-cli -p 6381 info replication
redis-cli -p 6382
info replication
既然主库挂了,我想要在6381 6382之间选一个新的主库
1.关闭6381的从库身份
redis-cli -p 6381 info replication slaveof no one
2/将6382设为6381的从库
6382连接到6381: [root@db03 ~]# redis-cli -p 6382 127.0.0.1:6382> SLAVEOF no one 127.0.0.1:6382> SLAVEOF 127.0.0.1 6381
3、再次检查6382/6381、的主从信息
九、redis哨兵集群
9.1Redis-Sentinel
Redis-Sentinel是redis官方推荐的高可用性解决方案,当用redis作master-slave的高可用时,如果master本身宕机,redis本身或者客户端都没有实现主从切换的功能。而redis-sentinel就是一个独立运行的进程,用于监控多个master-slave集群,自动发现master宕机,进行自动切换slave > master。
主要功能:
不时的监控redis是否良好运行,如果节点不可达就会对节点进行下线标识 如果被标识的是主节点,sentinel就会和其他的sentinel节点“协商”,如果其他节点也人为主节点不可达,就会选举一个sentinel节点来完成自动故障转义 在master-slave进行切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,
即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
9.2Sentinel的工作方式:
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel
标记为主观下线。 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。 主观下线和客观下线 主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。 客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过
SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover. SDOWN适合于Master和Slave,只要一个 Sentinel 发现Master进入了ODOWN, 这个 Sentinel 就可能会被其他 Sentinel 推选出,
并对下线的主服务器执行自动故障迁移操作。 ODOWN只适用于Master,对于Slave的 Redis 实例,Sentinel 在将它们判断为下线前不需要进行协商, 所以Slave的 Sentinel 永远不会达到ODOWN。
9.3redis主从复制背景问题
redis主从复制可将主节点数据同步给从节点,从节点此时有两个作用:
- 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。
- 扩展主节点的读能力,分担主节点读压力。
但是问题是:
- 一旦主节点宕机,从节点上位,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点
那么这个问题,redis-sentinel就可以解决了
9.4Redis Sentinel架构
redis的一个进程,但是不存储数据,只是监控redis
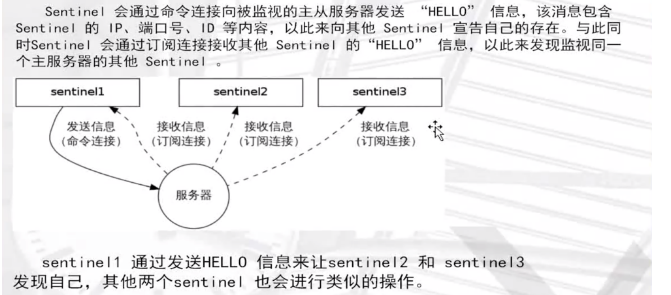
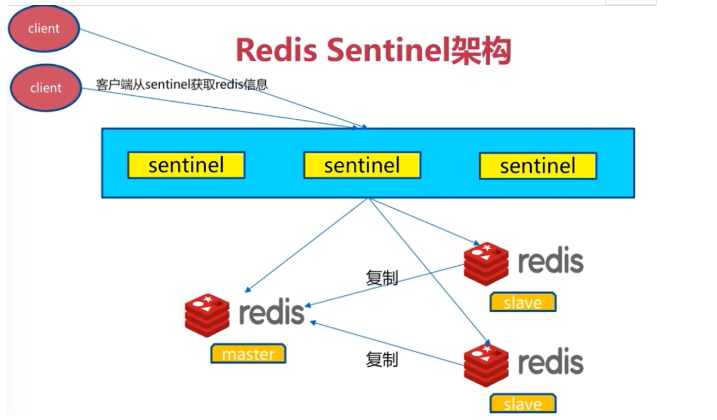

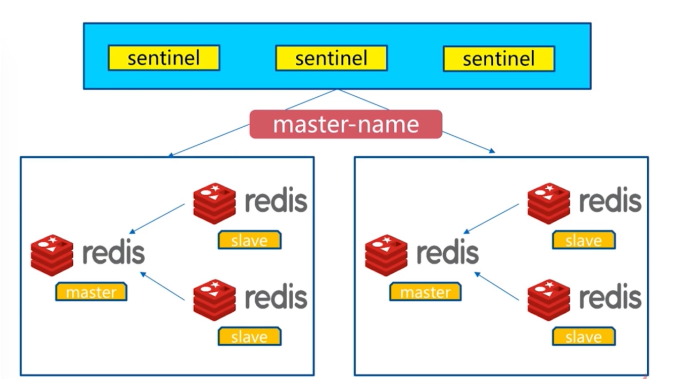
9.5安装与配置
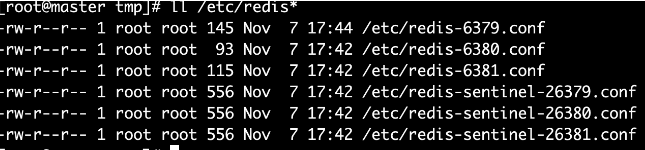
1、文件配置信息
2、主从节点的配置
redis-6379.conf
port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/"
redis-6380.conf
port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点
redis-6381.conf
daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点
3、启动主节点并测试主节点是否通信
启动:
redis-server /etc/redis-6379.conf
测试:
redis-cli ping
4、启动从节点,测试是否通信
启动:
[root@master 192.168.119.10 ~]$redis-server /etc/redis-6380.conf [root@master 192.168.119.10 ~]$redis-server /etc/redis-6381.conf
测试:
[root@master ~]$redis-cli -p 6380 ping PONG [root@master ~]$redis-cli -p 6381 ping PONG
5、确定主从关系
主:
[root@master ~]# redis-cli -p 6379 info replication
从:
[root@slave 192.168.119.11 ~]$redis-cli -p 6380 info replication
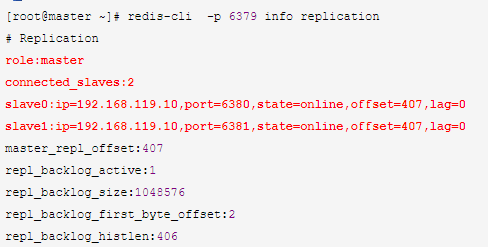
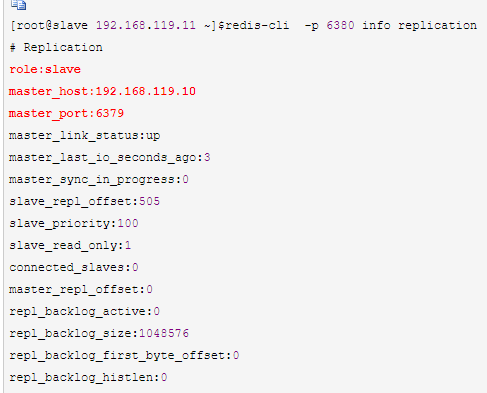
此时可以在master上写入数据,在slave上查看数据,此时主从复制配置完成
6、哨兵配置文件信息
// Sentinel节点的端口 port 26379 dir /var/redis/data/ logfile "26379.log" // 当前Sentinel节点监控 192.168.119.10:6379 这个主节点 // 2代表判断主节点失败至少需要2个Sentinel节点节点同意 // mymaster是主节点的别名 sentinel monitor mymaster 192.168.119.10 6379 2 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds mymaster 30000 //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点, 原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs mymaster 1 //故障转移超时时间为180000毫秒 sentinel failover-timeout mymaster 180000
protected-mode no
redis-sentinel-26380.conf和redis-sentinel-26381.conf的配置仅仅差异是port(端口)的不同。
使用sed命令快速生成
sed "s/2637926380/g" redis-sentinel-26379 > redis-sentinel-26380
7、启动哨兵
redis-sentinel /etc/redis-sentinel-26379.conf redis-sentinel /etc/redis-sentinel-26380.conf redis-sentinel /etc/redis-sentinel-26381.conf
8、查看哨兵是否通信
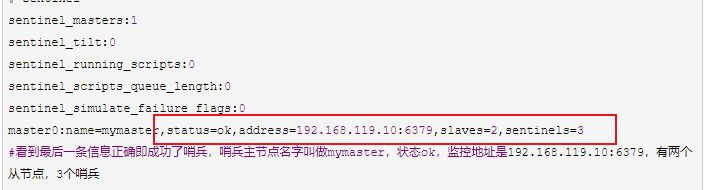
[root@master ~]# redis-cli -p 26379 info sentinel
9、redis高可用故障实验
大致思路
- 杀掉主节点的redis进程6379端口,观察从节点是否会进行新的master选举,进行切换
- 重新恢复旧的“master”节点,查看此时的redis身份
首先查看三个redis的进程状态
1)查看三个节点的进程状态
ps -ef|grep redis
2)查看三个节点的身份状态
[root@master tmp]# redis-cli -p 6381 info replication
[root@master tmp]# redis-cli -p 6380 info replication
[root@master tmp]# redis-cli -p 6379 info replication
# Replication role:slave master_host:127.0.0.1 master_port:6380
3)干掉master
ps -ef|grep 6380 #干掉master进程
kill -9 端口号
4)重新查看两个从节点的身份
[root@master tmp]# redis-cli -p 6379 info replication
9.6总结:
会发现从节点会自动变为主节点
十redis-cluster配置
10.1为什么要用redis-cluste
1、并发问题 redis官方生成可以达到 10万/每秒,每秒执行10万条命令 假如业务需要每秒100万的命令执行呢?
2、数据量大
一台服务器内存正常是16~256G,假如你的业务需要500G内存,
eg:新浪微博作为世界上最大的redis存储,就超过1TB的数据,各大公司有自己的解决方案,推出各自的集群功能,
核心思想都是将数据分片(sharding)存储在多个redis实例中,每一片就是一个redis实例。
各大企业集群方案: twemproxy由Twitter开源 Codis由豌豆荚开发,基于GO和C开发 redis-cluster官方3.0版本后的集群方案
10.2解决方案
1、配置一个超级牛逼的计算机,超大内存,超强cpu

2.正确的应该是考虑分布式,加机器,把数据分到不同的位置,分摊集中式的压力,一堆机器做一件事

10.3客户端分片
redis3.0集群采用P2P模式,完全去中心化,将redis所有的key分成了16384个槽位,每个redis实例负责一部分slot,集群中的所有信息通过节点数据交换而更新。
redis实例集群主要思想是将redis数据的key进行散列,通过hash函数特定的key会映射到指定的redis节点上
10.4数据分布原理图
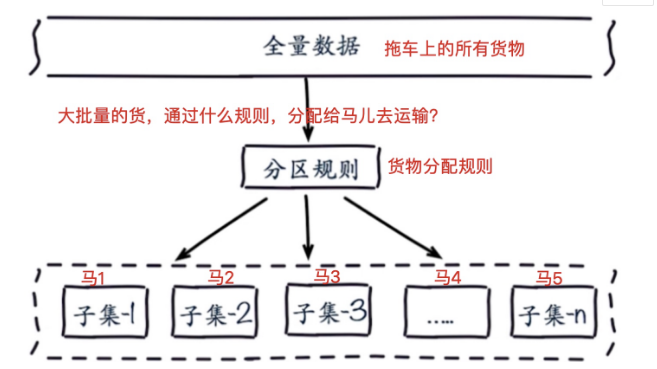
10.5数据分布理论
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
常见的分区规则有哈希分区和顺序分区。Redis Cluster采用哈希分区规则,因此接下来会讨论哈希分区规则。
- 节点取余分区
- 一致性哈希分区
- 虚拟槽分区(redis-cluster采用的方式)
1、顺序分区
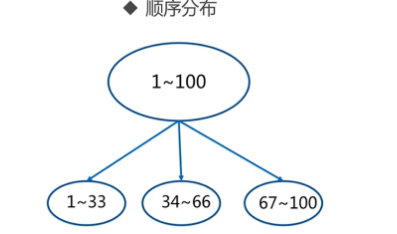
2、哈希分区
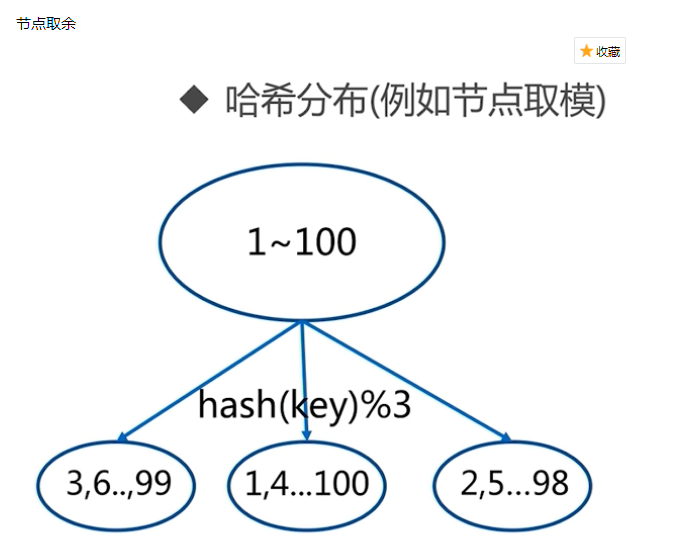
例如按照节点取余的方式,分三个节点
1~100的数据对3取余,可以分为三类
- 余数为0
- 余数为1
- 余数为2
那么同样的分4个节点就是hash(key)%4
3、一致性哈希
节点取余的优点是简单,客户端分片直接是哈希+取余
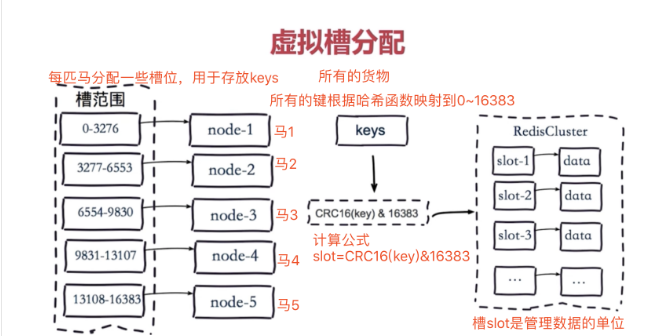
4、虚拟槽分区
Redis Cluster采用虚拟槽分区
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。 Redis Cluster槽的范围是0 ~ 16383。 槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展, 每个节点负责一定数量的槽。
10.6搭建redis cluster
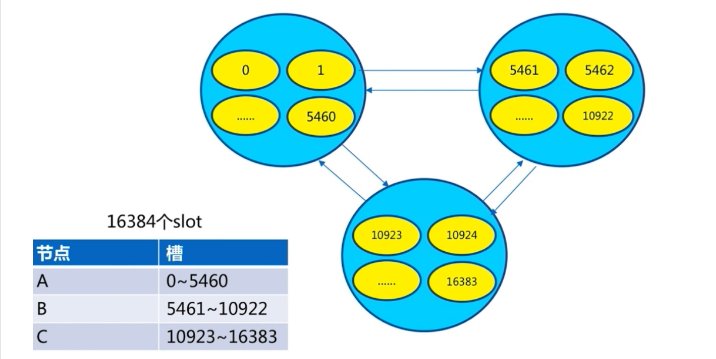
搭建集群分为几部
- 准备节点(几匹马儿)
- 节点通信(几匹马儿分配主从)
- 分配槽位给节点(slot分配给马儿)
redis-cluster集群架构
10.7安装方式
1、环境准备
通过配置,开启redis-cluster
port 7000 daemonize yes dir "/opt/redis/data" logfile "7000.log" dbfilename "dump-7000.rdb" cluster-enabled yes #开启集群模式 cluster-config-file nodes-7000.conf #集群内部的配置文件 cluster-require-full-coverage no #redis cluster需要16384个slot都正常的时候才能对外提供服务,换句话说,
只要任何一个slot异常那么整个cluster不对外提供服务。 因此生产环境一般为no
redis支持多实例的功能,我们在单机演示集群搭建,需要6个实例,三个是主节点,三个是从节点,数量为6个节点才能保证高可用的集群。
每个节点仅仅是端口运行的不同!
其他数据配置文件快熟生成:
sed "s/7000/7001/g" redis-7000.conf > redis-7001.conf
最后目录结构:
[root@yugo /opt/redis/config 17:12:30]#ls redis-7000.conf redis-7002.conf redis-7004.conf redis-7001.conf redis-7003.conf redis-7005.conf
2、运行reids实例
redis-server redis-7000.conf
.....
redis-server redis-7005.conf
3、检查端口、进程
netstat -tunlp|grep redis
ps -ef|grep redis
4、准备ruby环境
#下载ruby wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz #安装ruby tar -xvf ruby-2.3.1.tar.gz ./configure --prefix=/opt/ruby/ make && make install #准备一个ruby命令 #准备一个gem软件包管理命令 #拷贝ruby命令到path下/usr/local/ruby cp /opt/ruby/bin/ruby /usr/local/ cp bin/gem /usr/local/bin
!别忘了环境变量的配置
安装ruby gem 包管理工具
wget http://rubygems.org/downloads/redis-3.3.0.gem gem install -l redis-3.3.0.gem
#查看gem有哪些包 gem list -- check redis gem
5、一键开启redis-cluster集群
#每个主节点,有一个从节点,代表--replicas 1 redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 #集群自动分配主从关系 7000、7001、7002为 7003、7004、7005 主动关系
!redis-trib.rb 使用绝对路径
6、查看集群的状态
redis-cli -p 7000 cluster info redis-cli -p 7000 cluster nodes # 等同于查看nodes-7000.conf文件节点信息
集群主节点状态 redis-cli -p 7000 cluster nodes | grep master 集群从节点状态 redis-cli -p 7000 cluster nodes | grep slave
检查集群状态
[root@yugo /opt/redis/src 18:42:14]#redis-cli -p 7000 cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:10468 cluster_stats_messages_pong_sent:10558 cluster_stats_messages_sent:21026 cluster_stats_messages_ping_received:10553 cluster_stats_messages_pong_received:10468 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:21026
7、测试
登录集群必须使用redis-cli -c -p 7000必须加上-c参数
127.0.0.1:7000> set name chao -> Redirected to slot [5798] located at 127.0.0.1:7001 OK 127.0.0.1:7001> exit [root@yugo /opt/redis/src 18:46:07]#redis-cli -c -p 7000 127.0.0.1:7000> ping PONG 127.0.0.1:7000> keys * (empty list or set) 127.0.0.1:7000> get name -> Redirected to slot [5798] located at 127.0.0.1:7001 "chao"
10.8工作原理
redis客户端任意访问一个redis实例,如果数据不在该实例中,通过重定向引导客户端访问所需要的redis实例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号