02python基础之基础数据类型
基础数据类型
数据类型在数据结构中的定义是一个值的集合以及定义在这个值集上的一组操作。变量是用来存储值的所在处,它们有名字和数据类型。变量的数据类型决定了如何将代表这些值的位存储到计算机的内存中。在声明变量时也可指定它的数据类型。所有变量都具有数据类型,以决定能够存储哪种数据。
1、数字(int )
数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以。
常用方法:bit_length
#bit_length() 当十进制用二进制表示时,最少使用的位数 v = 11 data = v.bit_length() print(data)
2、布尔值(bool)
布尔值就两种:True,False。就是反应条件的正确与否.。
真 1 True。
假 0 False
3、字符串(str)
字符串或串(String)是由数字、字母、下划线组成的一串字符。
操作方法
1、索引
索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。
a = 'ABCDEFGHIJK' print(a[0]) print(a[3]) print(a[5]) print(a[7])
2、切片
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串。
原则:就是顾头不顾腚。
a = 'ABCDEFGHIJK' print(a[0:3]) print(a[2:5]) print(a[0:]) #默认到最后 print(a[0:-1]) # -1 是列表中最后一个元素的索引,但是要满足顾头不顾腚的原则,所以取不到K元素 print(a[0:5:2]) #加步长 print(a[5:0:-2]) #反向加步长
3、常用方法
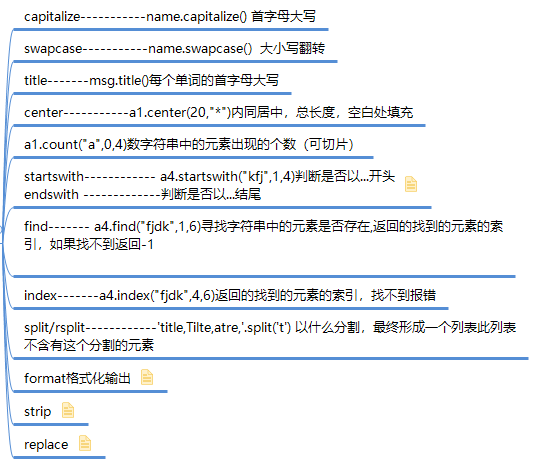


#captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='taibai say hi' print(msg.title()) #每个单词的首字母大写 # 内同居中,总长度,空白处填充 ret2 = a1.center(20,"*") print(ret2) #数字符串中的元素出现的个数。 # ret3 = a1.count("a",0,4) # 可切片 # print(ret3) a4 = "dkfjdkfasf54" #startswith 判断是否以...开头 #endswith 判断是否以...结尾 # ret4 = a4.endswith('jdk',3,6) # 顾头不顾腚 # print(ret4) # 返回的是布尔值 # ret5 = a4.startswith("kfj",1,4) # print(ret5) #寻找字符串中的元素是否存在 # ret6 = a4.find("fjdk",1,6) # print(ret6) # 返回的找到的元素的索引,如果找不到返回-1 # ret61 = a4.index("fjdk",4,6) # print(ret61) # 返回的找到的元素的索引,找不到报错。 #split 以什么分割,最终形成一个列表此列表不含有这个分割的元素。 # ret9 = 'title,Tilte,atre,'.split('t') # print(ret9) # ret91 = 'title,Tilte,atre,'.rsplit('t',1) # print(ret91) #format的三种玩法 格式化输出 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) #strip name='*barry**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #####is系列 name='taibai123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isdigit()) #字符串只由数字组成
4、元组(tuple)
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,字符串的切片操作同样适用于元组。例:(1,2,3)("a","b","c")
操作方法:
1、查
索引、切片、切片+步长、for循环,具体操作参照列表。
2、删
del
3、改
元组本身不支持修改,但其元素可能可以修改
4、常用方法
count、index
5、列表
列表是python中的基础数据类型之一,其他语言中也有类似于列表的数据类型,比如js中叫数组,他是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如:
li = [‘alex’,123,Ture,(1,2,3,’wusir’),[1,2,3,’小明’,],{‘name’:’alex’}]
列表与字符串的区别:
1、可以储存不同的数据类型,而且可以储存大量数据,32位python的限制是 536870912 个元素,64位python的限制是 1152921504606846975 个元素。
2、列表是有序的,有索引值,可切片,方便取值
操作方法:
1、 增
主要方法有append-----最后 可以是int、str、list、tuple
insert -------插入(根据索引)
extend------必须是可迭代对象、可迭代加入
li = [1,'a','b',2,3,'a'] li.insert(0,55) #按照索引去增加 # print(li) # li.append('aaa') #增加到最后 # li.append([1,2,3]) #增加到最后 # print(li) # li.extend(['q,a,w']) #迭代的去增 # li.extend(['q,a,w','aaa']) # li.extend('a') # li.extend('abc') # li.extend('a,b,c') # print(li)
2、删
pop 索引、pop()有返回值
remove l.remove()根据元素删除、没有返回值。只删除第一个
注: 删除多个时,用For 循环
clear 清空列表
del 删除列表1、索引 2、 切片/(切片+步长)3、 删除整个列表
1 li = [1,'a','b',2,3,'a'] 2 # li.insert(0,55) #按照索引去增加 3 # print(li) 4 # 5 # li.append('aaa') #增加到最后 6 # li.append([1,2,3]) #增加到最后 7 # print(li) 8 # 9 # li.extend(['q,a,w']) #迭代的去增 10 # li.extend(['q,a,w','aaa']) 11 # li.extend('a') 12 # li.extend('abc') 13 # li.extend('a,b,c') 14 # print(li)
3、改
1、通过索引修改 2、切片 (先清除在跌代添加)3、(切片+步长)必须一一对应
# 改 # li = [1,'a','b',2,3,'a'] # li[1] = 'dfasdfas' # print(li) # li[1:3] = ['a','b'] # print(li) 列表的改
4、查
1、通过索引2、 切片/(切片+步长)3、for循序
5、其他常用方法:
len、count、index(通过元素找索引,找到第一个返回,找不到报错,没有find函数)、sort/sort(reverse=True)、reverse(反转)、copy
count a = ["q","w","q","r","t","y"] print(a.count("q")) index = ["q","w","r","t","y"] print(a.index("r")) sort/reverse a = [2,1,3,4,5] a.sort()# 他没有返回值,所以只能打印a print(a) a.reverse()#他也没有返回值,所以只能打印a print(a)
6、字典
字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。字典(dictionary)是除列表外python之中最灵活的内置数据结构类型。
特点:
1、python中唯一的映射类型 2、字典以键、值对的形式储存,键是可哈希的,值是不可哈希的。
优点:
1、字典可以储存大量的关系型数据。 2 、字典的查询速度非常快
字典与列表的区别:
1、字典当中的元素是通过键来存取的,而不是通过偏移存取 2、列表的关系性不强、储存信息较多时查询速度慢
字典在python3.6和在以前版本的区别:
1、字典是无序的
2、在cpython解释器中,字典在python3.6中是无序的,在python3.5(包括在python3.5以前的版本中是有序的)
操作方法:
1、 增
1、通过索引增加 有则覆盖,无则增加
2、se.tdefault 有则不变,无则增加
# dic['li'] = ["a","b","c"] # print(dic) # setdefault 在字典中添加键值对,如果只有键那对应的值是none,但是如果原字典中存在设置的键值对,则他不会更改或者覆盖。 # dic.setdefault('k','v') # print(dic) # {'age': 18, 'name': 'jin', 'sex': 'male', 'k': 'v'} # dic.setdefault('k','v1') # {'age': 18, 'name': 'jin', 'sex': 'male', 'k': 'v'} # print(dic) 字典的增
2、删
只能按照键删除
pop dic.pop() 有返回值, 有则删除,无则报错。但是可以设置不报错(也可设置不报错的返回值)。dic.pop('age','没有此键')
clear 清空字典
del 1、按照键删除 2、删除整个字典
注:有则删除,无则报错,按照键删除时推荐使用pop
# dic_pop = dic.pop("a",'无key默认返回值') # pop根据key删除键值对,并返回对应的值,如果没有key则返回默认返回值 # print(dic_pop) # del dic["name"] # 没有返回值。 # print(dic) # dic_pop1 = dic.popitem() # 随机删除字典中的某个键值对,将删除的键值对以元祖的形式返回 # print(dic_pop1) # ('name','jin') # dic_clear = dic.clear() # 清空字典 # print(dic,dic_clear) # {} None
3、改
1、按照键修改 2、update
# dic = {"name":"jin","age":18,"sex":"male"} # dic2 = {"name":"alex","weight":75} # dic2.update(dic) # 将dic所有的键值对覆盖添加(相同的覆盖,没有的添加)到dic2中 # print(dic2)
4、查
1、按照键查找 没有会报错 2、get (没有不会报错、可设置返回值) 3、for循环
# value1 = dic["name"] # 没有会报错
# print(value1)
#
# value2 = dic.get("djffdsafg","默认返回值") # 没有可以返回设定的返回值
# print(value2
# dic = {"name":"jin","age":18,"sex":"male"} # for key in dic: # print(key) # for item in dic.items(): # print(item) # for key,value in dic.items(): # print(key,value)
5 、其他常用方法:
dic.keys() 、 dic.values() 、 dic.items() 三种方法均可转换成列表
# item = dic.items() # print(item,type(item)) # dict_items([('name', 'jin'), ('sex', 'male'), ('age', 18)]) <class 'dict_items'> # 这个类型就是dict_items类型,可迭代的 # keys = dic.keys() # print(keys,type(keys)) # dict_keys(['sex', 'age', 'name']) <class 'dict_keys'> # values = dic.values() # print(values,type(values)) # dict_values(['male', 18, 'jin']) <class 'dict_values'> 同上 这三种形式都可以转换成列表
嵌套:
dic = { 'name_list': ['博哥', '菊哥', 'b哥', 'alex'], 'barry': { 'name': '太白金星', 'age': 18, 'hobby': 'wife', } } # 1,给这个列表['博哥', '菊哥', 'b哥', 'alex'] 追加一个元素 '老男孩'。 # l1 = dic['name_list'] # # print(l1) # l1.append('老男孩') # print(dic) # 简写; # dic['name_list'].append('老男孩') # print(dic) # 2,将这个列表['博哥', '菊哥', 'b哥', 'alex']中的alex变成首字母大写。 # print(dic['name_list'][-1].capitalize()) # dic['name_list'][-1] = dic['name_list'][-1].capitalize() # print(dic) # 3,将这个键值对 'name': '太白金星' 的 '太白金星' 改成男神。 # 先通过dic 找到小字典 # print(dic['barry']) # 在通过小字典将name 对应的值更改 # dic['barry']['name'] = '男神' # print(dic) # 4,给barry对应的小字典增加一个键值对: weight: 160 # dic['barry']['weight'] = 150 # print(dic)
7、集合
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。也可以理解为一种特殊的字典(所有value都是None的字典)。
作用:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
集合中元素的特点:
唯一、可以哈希、无序
操作方法:
1、集合的创建
1.手动创建集合.
1.创建空集合
d = {}
创建空集合,只有一种方式:调用set函数.
S = set()
2.创建带元素集合
S = {1,2,3}
从可迭代对象中(字符串,列表,元组,字典)创建集合.
s = set(‘abc’)
S = set([1,2,3])
S = set((1,2,3))
S = set({‘name’:’Andy’,’age’:10})
2.通过方法调用
-> str
-> list
-> set
2、增
add 有则不变,无则增加
set1 ={11,'22','dxl'}
set1.add('libai') #{'22', 11, 'dxl', 'libai'}
set1 ={11,'22','dxl'}
set1.add('22') # {'22', 11, 'dxl'}
3、删
Pop() :依次从集合中弹出一个元素,如果集合为空,报错
Discard(ele) :从集合中删除指定的元素,如果不存在,什么都不执行
Remove(ele) :从集合中删除指定的元素,如果不存在,报错
Clear() :清空
set1 ={11,'22','dxl'}
set1.pop()
set1.remove(11)
set1.discard('22')
set1.clear()
print(set1)
4、改
Update :用二者的并集更新当前集合
difference_update: 用二者的差集更新当前集合
intersection_update:用二者的交集更新当前集合
symmetric_difference_update:用二者的对称差集更新当前集合
Update
set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} set1.update(set2) #{'dxl', '李白', '22', 'xiaobai', 11}
# difference_update
set1 ={11,'22','dxl'}
set2 ={11,'22','李白','xiaobai'}
set1.difference_update(set2) #{'dxl'}
# intersection_update
set1 ={11,'22','dxl'}
set2 ={11,'22','李白','xiaobai'}
set1.intersection_update(set2) #{'22', 11}
# intersection_update
set1 ={11,'22','dxl'}
set2 ={11,'22','李白','xiaobai'}
set1.symmetric_difference_update(set2) #{'xiaobai', '李白', 'dxl'}
5、查
集合基本没有单独取其中元素的需求,可以使用for循环进行查询。
set1 ={11,'22','dxl'}
for i in set1:
print(i)
6、其它常用方法:
集合的四大常用操作:并集:union(|)、交集:intersection(&)、差集:difference(-)、对称差:symmetric_differenc
判断功能:
Isdisjoint:判断两个集合是否没有交集
Issubset:判断当前集合是否是后者的子集
Issuperset:判断后者是否是当前集合的子集
并集:union(|) set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.union(set2)) print(set1 | set2) #{'dxl', '22', 'xiaobai', 11, '李白'} 交集:intersection(&) set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.intersection(set2)) print(set1 & set2) #{11, '22'} 差集:difference(-) set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.difference(set2)) print(set1 - set2) #{'dxl'} 对称差:symmetric_differenc set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} # print(set1.symmetric_difference(set2)) # {'dxl', '李白','xiaobai'}
Isdisjoint:判断两个集合 是否 没有交集 set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.isdisjoint(set2)) # False Issubset:判断当前集合是否是后者的子集 set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.issubset(set2)) # False set1 ={11,'22',} set2 ={11,'22','李白','xiaobai'} print(set1.issubset(set2)) # True Issuperset:判断后者是否是当前集合的子集 set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.issuperset(set2)) # False set1 ={11,'22','dxl'} set2 ={11,'22'} print(set1.issuperset(set2)) # False set1 ={11,'22','dxl'} set2 ={11,'22','李白','xiaobai'} print(set1.isdisjoint(set2)) # True
集合的深浅copy
1,先看赋值运算。
l1 = [1,2,3,['barry','alex']] l2 = l1 l1[0] = 111 print(l1) # [111, 2, 3, ['barry', 'alex']] print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir' print(l1) # [111, 2, 3, ['wusir', 'alex']] print(l2) # [111, 2, 3, ['wusir', 'alex']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的。
2,浅拷贝copy。
#同一代码块下: l1 = [1, '太白', True, (1,2,3), [22, 33]] l2 = l1.copy() print(id(l1), id(l2)) # 2713214468360 2713214524680 print(id(l1[-2]), id(l2[-2])) # 2547618888008 2547618888008 print(id(l1[-1]),id(l2[-1])) # 2547620322952 2547620322952 # 不同代码块下: >>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]] >>> l2 = l1.copy() >>> print(id(l1), id(l2)) 1477183162696 >>> print(id(l1[-2]), id(l2[-2])) 1477181814032 >>> print(id(l1[-1]), id(l2[-1])) 1477183162504
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的。可变数据里面的一个数据类型发生变化,copy列表里面的元素也会发生改变。
3、拷贝deepcopy。
# 同一代码块下 import copy l1 = [1, 'alex', True, (1,2,3), [22, 33]] l2 = copy.deepcopy(l1) print(id(l1), id(l2)) # 2788324482440 2788324483016 print(id(l1[0]),id(l2[0])) # 1470562768 1470562768 print(id(l1[-1]),id(l2[-1])) # 2788324482632 2788324482696 print(id(l1[-2]),id(l2[-2])) # 2788323047752 2788323047752 # 不同代码块下 >>> import copy >>> l1 = [1, '太白', True, (1, 2, 3), [22, 33]] >>> l2 = copy.deepcopy(l1) >>> print(id(l1), id(l2)) 1477183162632 >>> print(id(0), id(0)) 1470562736 >>> print(id(-2), id(-2)) 1470562672 >>> print(id(l1[-1]), id(l2[-1])) 1477183162312
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。修改互不影响。
集合的使用场景
1.判断一个元素是否在指定的范围之内.
2.方便数学上的集合操作
3.对序列数据类型中的重复元素进行去重
8、frozenset:冻结的集合
特点:
不可变
操作方法:
1、集合的创建
手动创建
s = frozenset() s = frozenset('abcabc') s = frozenset([1,2,3]) s = frozenset((1,2,3)) s = frozenset({'name':'Andy','age':10})
2、其它方法
1、 'copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union'
2、与集合set相比少了添加、更新的方法,方法的具体操作可参照集合。
3、小结
如果两种数据类型混用,方法的主调者的类型决定了最终结果的类型.
set1 ={11,'22','dxl','22'}
frozenset_set =frozenset({11,'22','libai','xiaobai'})
print(set1.union(frozenset_set),type(set1.union(frozenset_set)))
set1 ={11,'22','dxl','22'}
frozenset_set =frozenset({11,'22','libai','xiaobai'})
print(frozenset_set.union(set1),type(frozenset_set.union(set1)))
应用场景
- 凡是使用到不可改变的数据的场景,都是可以使用frozenset的.
- set集合的元素:必须是可以哈希的,set本身不是可以哈希.
- 但是frozenset是不可变的数据.(可以哈希的),它是可以放到集合中.
- set和frozenset可以互相转换.
8、基础数据总结
8.1基础数据之间相互转换
常见的数据类型有int、bool、str、list、tuple、dic、set
1、int、bool、str、三者之间可以相互转换。
# int ----> str print(str(a),type(str(a))) # 1 <class 'str'> # int ----> bool print(bool(a),type(bool(a))) # True <class 'bool'> # str----> int b = '10' print(int(b),type(int(b))) # 10 <class 'int'> # str ----> bool print(bool(' '),type(bool(' '))) # True <class 'bool'> # bool ----> int print(int(True),type(int(True))) # True <class 'bool'> # bool ----> str print(str(True),type(str(True))) # True <class 'str'>
2、bool可以与所有类型值进行转换,所有为空的数据类型转化成bool都为Fasle
0 '' [] () {} None ----> Fasle
3、str、list之间可以进行相互转换
str ---> list split 分割 s='12234' l = s.split() #['12234'] <class 'list'> print(l,type(l)) list ---> str join # list里面的元素全部都是str类型 l1 = ['武sir', 'alex', '太白'] print(' '.join(l1)) # 武sir alex 太白
4、str、之间tuple可以进行相互转换
str、之间tuple可以进行相互转换
5、dict ----> list,list步能转换成list
# dic = {'name':'alex','age': 73} # print(list(dic))
7、set---->list,list不能转换成
set ={11,'22','33'}
print(list(set),type(list(set))) # ['33', 11, '22'] <class 'list'>
8.2基础数据类型的分类
按占用空间分
数字
字符串
集合:无序,即无序存索引相关信息
元组:有序,需要存索引相关信息,不可变
列表:有序,需要存索引相关信息,可变,需要处理数据的增删改
字典:无序,需要存key与value映射的相关信息,可变,需要处理数据的增删改

8.3易错知识点小结
1、tuple: 如果元组中只有单个元素并且没有 , 则类型是元素本身的类型.
tu1 = (1) tu1 = ('alex') #alex <class 'str'>
2、字典的值是一个可变的数据类型, 他在内存中是一个.id相同.
dic = dict.fromkeys([1,2,3],'太白') #{1: '太白', 2: '太白', 3: '太白'}dic = dict.fromkeys('abcd','太白') #{'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}dic = dict.fromkeys('abcd',[1,2]) #{'a': [1, 2], 'b': [1, 2], 'c': [1, 2], 'd': [1, 2]} dic = dict.fromkeys('abcd',[]) dic['a'].append(666) #{'a': [666], 'b': [666], 'c': [666], 'd': [666]}
3、关于列表赋值
l1 = [1,2,3] l2 = l1 l3 = l2 l1.append(666) l2.append(111) l3.append(333) print(l1) #[1, 2, 3, 666, 111, 333] print(l2) #[1, 2, 3, 666, 111, 333] print(l3) #[1, 2, 3, 666, 111, 333]
4、循环一个列表时,最好不要对原列表有改变大小的操作,这样会影响你的最终结果.
# 方法一: # del l1[1::2] # print(l1) # 方法二:错误示例: # 循环一个列表时,不要改变列表的大小.这样会影响你最后的结果. # for index in range(len(l1)): # if index % 2 == 1: # # index 奇数 # l1.pop(index) # print(l1) # 方法三 # new_l = [] # for index in range(len(l1)): # if index % 2 == 0: # new_l.append(l1[index]) # # print(new_l) # l1 = new_l # print(l1) # 方法三: # for index in range(len(l1)-1,-1,-1): # if index % 2 == 1: # l1.pop(index) # print(l1)
5、 循环一个字典时,不能改变字典的大小,这样会报错.
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'}
# 将字典中的key中含有k元素的所有键值对删除.
# dictionary changed size during iteration
# for key in dic:
# if 'k' in key:
# dic.pop(key)
# print(dic)
# l1 = []
# for key in dic:
# if 'k' in key:
# l1.append(key)
# # print(l1)
# for key in l1:
# dic.pop(key)
# print(dic)
补充知识点
1、分别复制: a,b=(1,2) a=1 b=2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号