

个人第4次作业:结对编程
| GIT项目地址 | https://github.com/dxg1999/WordCount.git |
|---|---|
| 结对伙伴的作业地址 | https://www.cnblogs.com/whisperwahh/p/11670134.html |
| 个人博客 | 我的博客 |
| 作业链接 | 作业内容 |
1.PSP项目计划表
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 43 |
| · Estimate | · 估计这个任务需要多少时间 | 1500 | 1753 |
| Development | 开发 | 500 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 55 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 300 | 600 |
| · Code Review | · 代码复审 | 30 | 45 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 20 |
| Reporting | 报告 | 30 | 60 |
| · Test Report | · 测试报告 | 30 | 45 |
| · Size Measurement | · 计算工作量 | 30 | 25 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 1220 | 1753 |
2..解题思路描述
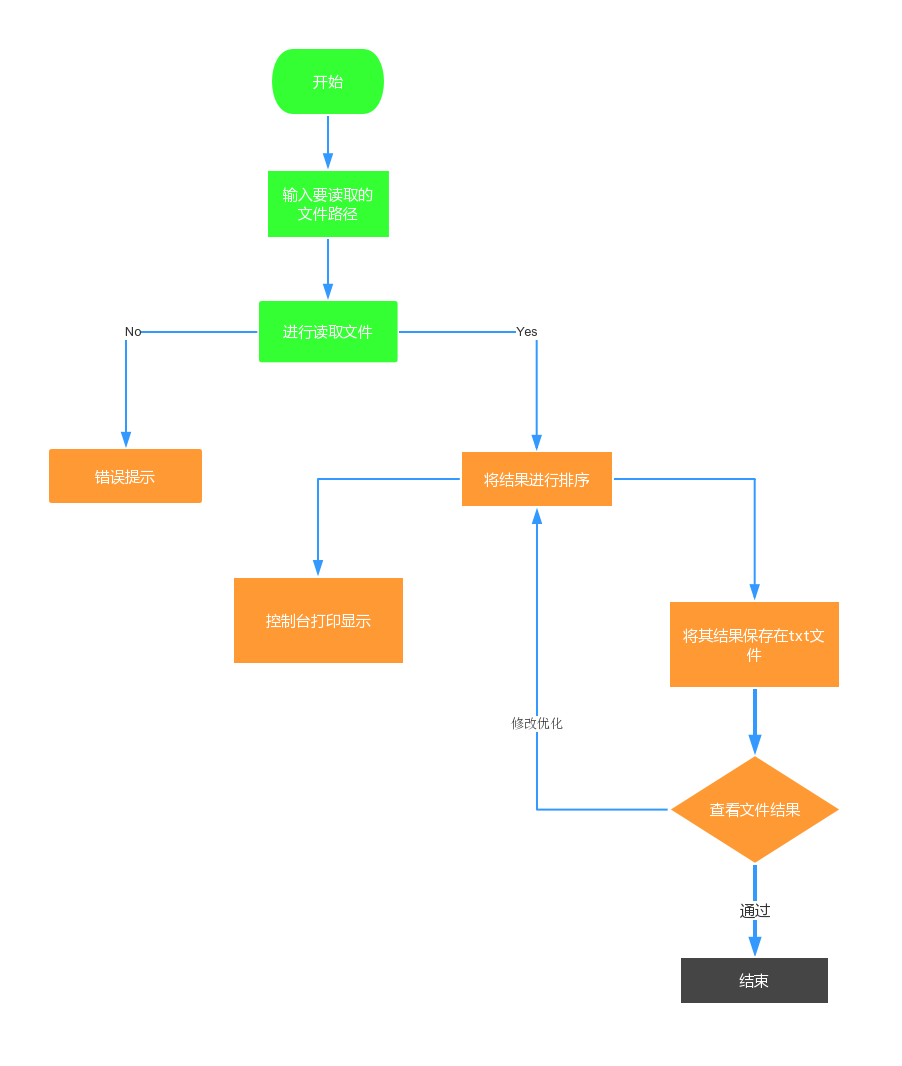
需求分析
- 输入文件名以命令行参数传入。
例如我们在命令行窗口(cmd)中输入:
wordCount.exe input.txt
则会统计input.txt中的以下几个指标
统计文件的字符数:
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
输出的单词统一为小写格式
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的格式为:
· characters: number
· words: number
· lines: number
·: number
·: number
需求整合
1.命令行传入参数
2.统计文件字符数(包括字特殊符号)
3.只需要统计Ascii码,汉字不需考虑
4.统计单词总数(单词必须四个英文字母开头,后面可以为数字,不区分大小写)
5统计文件中单词总数,并按照频率排序,对于相同频率单词按字典顺序排列
6.按照字典顺序输出到文件中等等
实现思路
1.传入指令的获取,就用C#中的正则表达式来获取,从控制台读取文件路径从而获取参数,并用addString类方法将其储存在集合里
2.从集合t里获取数据,并判断提取参数内容是否为null来解决
3.再在功能实现接口下用cal类方法实现数据统计并排序
4.在cal_Words方法cal参数的解析,再利用txt文件保存其内容
5.利用output输出功能按字典序输出
3.设计实现过程
项目的类
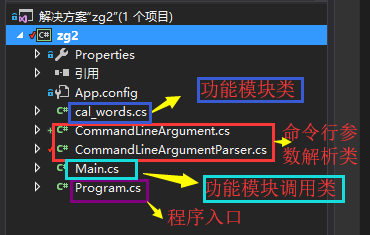
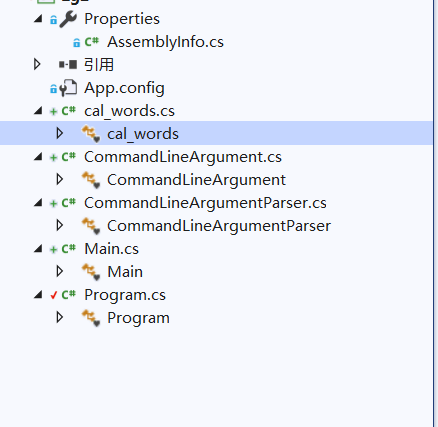
流程图

4.代码规范及链接
类型成员的排列顺序自上而下:
字段:private、protected
属性:private、protected、public
事件:private、protected、public
构造函数:参数越多,排的越靠前
方法:参数越多,排的越靠前
5.主要关键代码
5.1统计单词数
public int cal(String s, Hashtable word)
{
int num_words = 0;
if (s.Length >= 4)
{
for (int i = 0; i < s.Length - 3;)
{
if (!IsOnlyWord(s.Substring(i, 4)))
{
i++; continue;
}
for (int j = i + 3; j < s.Length; j++)
{
if (IsNumberAndWord(s[j] + "") && j == s.Length - 1)
{
num_words++;
addString(s.Substring(i, j - i + 1),word);
return num_words;
}
else if (!IsNumberAndWord(s[j] + ""))
{
num_words++;
addString(s.Substring(i, j - i),word);
i = j + 1;
break;
}
}
}
}
return num_words;
}
5.2计算指定长度的单词词组
public void cal_specifide(int length,String s,Hashtable words)
{
String[] temp = s.Split(new char[3] { ',', '.',' ' });
for(int i = 0; i < temp.Length - 1; i++)
{
//一个词组应该处于同一个完整的句子中
if (temp[i].Equals(".") || temp[i].Equals(",")) continue;
bool isWords = true;
String tmp_string = "";
for (int j = i; j < i + length; j++)
{
if (temp[j].Length < 4)
{
isWords = false;
break;
}
else if(!IsOnlyWord(temp[j].Substring(0, 4)))
{
isWords = false;
break;
}
else if (temp[j].Length>4 && !IsNumberAndWord(temp[j].Substring(4, temp[j].Length - 4)))
{
isWords = false;
break;
}
else tmp_string += " "+temp[j];
}
if (isWords)
addString(tmp_string, words);
}
}
5.3将单词加入Hashtable中
public void addString(String temp,Hashtable ht)
{
temp = temp.ToLower();
foreach (DictionaryEntry de in ht)
{
if (de.Key.Equals(temp))
{
ht[temp] = (int)de.Value + 1;
return;
}
}
ht.Add(temp, 1);
}
5.4按照key排序
//ArrayList akeys在此处初始化为word-key集合(Hashtable)
public void sort(ArrayList akeys,Hashtable ht)
{
akeys = new ArrayList(ht.Keys);
akeys.Sort(); //按字母顺序进行排序
}
6.代码复审
完成了之前分配的函数编码后,我们就开始代码互审。首先,我们根据之前借鉴的编码规范,各自审查对方的代码的可读性,有无不理解的函数名和变量名,代码方法是否不一致,可行性效率高不高;其实两人分开做,多多少少都会按照一点自己的意识来编写,肯定会有不同之处,所以编码前,我们就约定实时在QQ上交流,以免有重大的偏差,有也能及时更改。然后,通过一些简单的测试检查对方的方法是否实现目标功能。
7.性能分析
7.1初步分析

7.2详细分析


7.3测试用例

7.4测试结果

8.附加功能
提供可供用户交互的按钮和,实现-i -m -n -o 这四个参数的功能,对于异常情况需要给予用户提示,将结果直接输出到界面上,并提供“导出”按钮,将结果保存到用户指定的位置
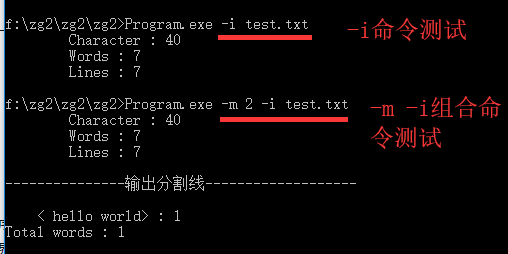
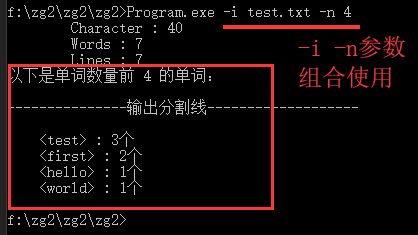

9.过程和总结

这次和我的搭档做这个作业,我们一起讨论了怎么设计类库、翻阅资料以及画流程图等等,做了很多前期准备,才敢进行代码编写这一步工作,总的来说收获是有的,但也认识到很多不足之处。这次作业学到了许多新知识,比如说从命令行接收参数,解析字符串,字典中键值对的一些操作等等。

