
个人第四次作业——结对编程
| GitHub项目地址 | 这里 |
|---|---|
| 合作同学作业地址 | 这里 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 1510 | 1925 |
| Development | 开发 | 990 | 1325 |
| Analysis | 需求分析 (包括学习新技术) | 90 | 100 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 (和同事审核设计文档) | 20 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 30 | 25 |
| Coding | 具体编码 | 900 | 1200 |
| Code Review | 代码复审 | 60 | 100 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 30 | 25 |
| Test Report | 测试报告 | 10 | 5 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1510 | 1925 |
二、计算模块接口的设计与实现过程
1.项目实现的基本思路
1)首先我们需要读取指定的文件,并且将文本文件中的内容提出出来,进行操作。这里使用C#的IO流来进行文件操作。
2)根据要求以及难易程度,我们首先解决文本的行数以及字符数的统计。这里使用正则表达式进行处理。
3)对于单词的统计我们在完成行数和字符数统计之后,决定使用集合来处理单词,但是发现单词是能够处理了,但是得不到单词出现的次数,所以我们转而使用字典集(Dictionary)来进行处理,字典集为我们提供了很多方便的功能。
先用ArrayList集合存储所有单词,包括重复的单词,都存进去,但是是按照要求存储单词,也就是说必须四个英文字母开头的单词我们才存储,这里就用到正则表达式来解决。
将存储好的单词经过遍历放进字典集,这样我们就得到了符合要求的所有单词的一个字典集,并且也得到了它们出现的次数,然后在对它们进行排序,就可以得到最终符合要求的前10个单词了。
4)基础功能实现后,又开始实现新添加的功能,命令行操作以及输出指定长度的词组。
由于使用条件判断语句不能够很好的满足命令行操作的要求,我们经过查找资料,发现了可以使用一个第三方的工具包来帮助我们。这里@命令行解析,通过这个工具包,我们实现了命令行操作。
对于指定长度的词组,实现方式和单词的存储大致相同。
整体程序流程图如下图所示
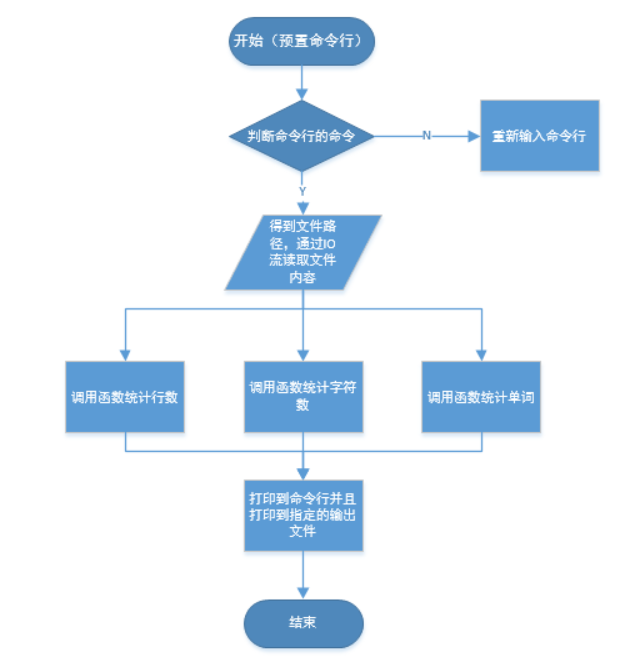
2.部分代码以及代码规范
-
通过正则表达式存储符合要求单词
/* * 按要求存储可用单词 */ public ArrayList Splitwords(string text) { ArrayList al = new ArrayList(); MatchCollection matchs = Regex.Matches(text, @"\b[a-zA-Z]{4,}\w*"); foreach (Match match in matchs) { al.Add(match.Value); } return al; } public ArrayList Splitlenth(int lenth, string text) { string b = lenth.ToString(); string pattern = "\\b\\w{"+b+"}\\s"; ArrayList al = new ArrayList(); MatchCollection matchs = Regex.Matches(text, pattern); foreach (Match match in matchs) { al.Add(match.Value); } return al; } -
统计每个单词出现的次数
/* * 统计每个单词出现的次数 */ public Dictionary<string, int> countWords(ArrayList arrayList) { Dictionary<string, int> nary = new Dictionary<string, int>(); foreach (string word in arrayList) { if (nary.ContainsKey(word)) { nary[word]++; } else { nary.Add(word, 1); } } return nary; } -
按值排序
/* * 按值排序 */ public Dictionary<string, int> sort(Dictionary<string, int> nary) { var result = from pair in nary orderby pair.Value descending, pair.Key ascending select pair; Dictionary<string, int> bronary = new Dictionary<string, int>(); foreach (KeyValuePair<string, int> pair in result) { bronary.Add(pair.Key, pair.Value); } return bronary; } -
指定输出词组长度
/* * 指定词组长度 */ public Dictionary<string,int> msort(ArrayList al,int size) { Dictionary<string, int> nary = new Dictionary<string, int>(); ArrayList bl = new ArrayList(); int i = 0; while(i<=al.Count-size) { string str = null; var result = al.GetRange(i, size); foreach (var n in result) { str += n.ToString()+" "; } bl.Add(str); i++; } foreach (string word in bl) { if (nary.ContainsKey(word)) { nary[word]++; } else { nary.Add(word, 1); } } return nary; }
代码规范是程序员的一种编程习惯,良好的编程习惯,不仅能自然地产生几乎没有bug的代码,而且在代码交接时,也方便继任者的阅读.这是我们的代码规范
3.接口设计以及封装
1)接口设计:将三个基本功能,分为三个类,降低耦合度,便于进行单元测试,以及代码的修改,这样就可以在修改其中一个功能的时候,不影响其他功能。但是也并没有把所有的功能都分离开,统计单词里面就有很多个功能,类多了会增加整个程序的繁琐程度,也会降低代码的可读性。
2)功能封装:按照要求将三个基本功能进行封装,封装成一个ClassLibrary,并且让它生成dll文件,这样程序就可以直接引用封装好的功能,更能减少代码量,降低耦合度。
在我们的Winform程序当中,我们引用了封装好的统计功能,减少了重复代码量。
接口的封装让我们的功能的实现更加的隐蔽,用户在引用我们的dll时,不会看见我们的代码。
三、代码复审
我在审查队友代码的时候,发现“统计单词”这一模块的排序实现有问题,不满足给定的要求。排序功能只实现了词频的排序,但是有相同词频的不同单词没有按照字典序排序。
最初版本运行截图:

可以看到,在第一个版本这里,"child"和"little"的词频都是出现一次,但是按照字典序,"child"应该排在"little"前面输出。
改进后版本运行截图:
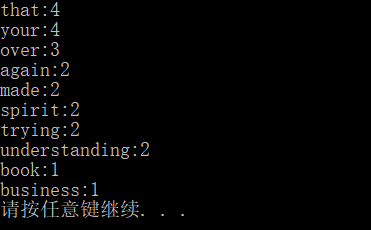
改进后,"again"和"made"词频都是出现两次,实现了字典序输出相同词频的单词排序。
四、模块接口性能改进
- 在完成所有要求之后,对代码进行效能分析如下。

- 对效能分析结果发现characSum函数占用较多CPU,修改前后效能分析对比如下
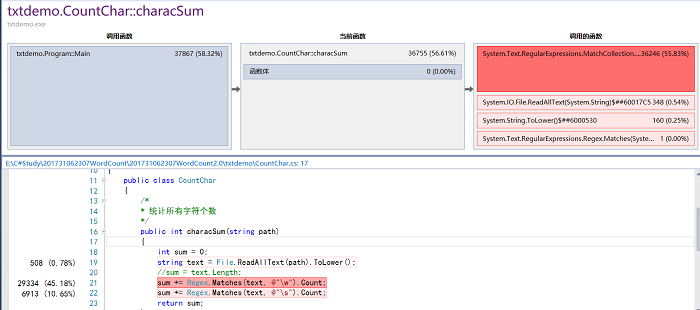
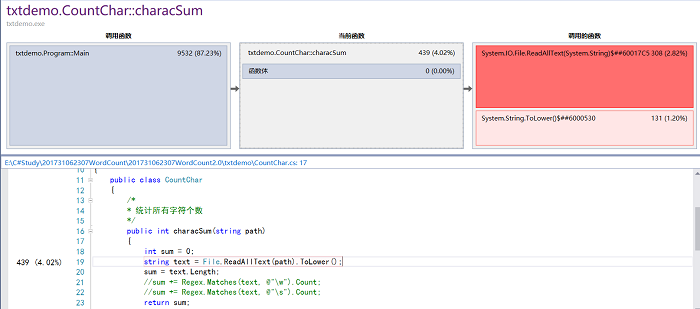
- 发现的问题以及解决措施
内存溢出问题
在进行小文本测试时,代码可以正常实现预定功能,并输出;当我们使用一个大小为28MB的txt文本时,经过进2分钟的运行,抛出内存溢出错误。
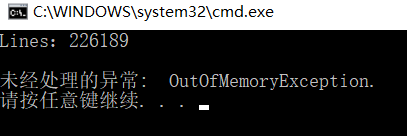
在多方查找资料以及严密分析之后,发现了我们代码中存在的问题。在characSum函数中,对大量数据进行处理时,需要连续不断的实例化非常多个对象,并且它们一直会在缓存区,直到函数执行完毕才会被释放,这样就会导致内存一直被挤压,最后就会导致内存不够用,进而抛出内存溢出的错误。
在了解了问题触发的机制后,在处理数据时,我们不再使用实例化对象的方式,而是通过统计字符串的整个长度来得到字符数的大小,并且经过实验,达到了预期目的。

五、单元测试
- 测试规则
测试三个基本功能。
对于行数以及字符数测试,我们进行简单的数据构造,测试数据要能够靠人工数出来。
对于单词统计测试,我们同样进行简单的数据构造。
1)大小写同时出现。
2)数据中要有file123和123file这类词。
3)数据中心要有小于4个字符的词。
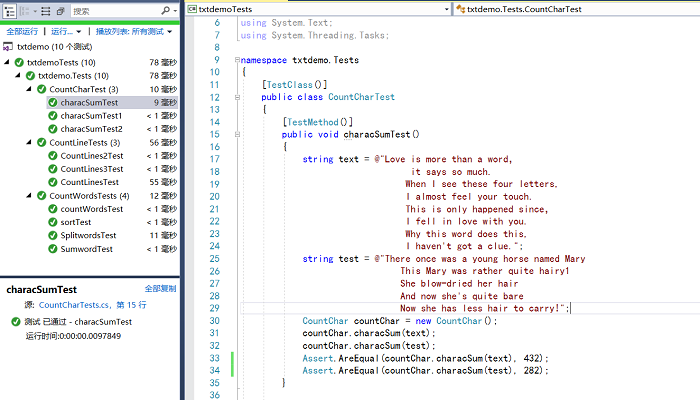
- 测试截图如下(本次测试共进行10组测试,由于本机安装社区版VS2017,不能查看测试代码覆盖率)
![]()
六、模块异常处理
- 命令行输入异常
命令行输入不符合要求的话,会提示出错,需要重新输入命令行。
- 内存溢出异常
根据代码效能分析的结果,设置内存溢出异常处理。
七、结对过程
在结对之后,选定了两方都有空的时间进行讨论,根据PSP表格预估时间,讨论出项目需求,代码设计,根据各自水平进行分工,完成代码先进性自省,然后交换代码进行复审,最后汇总生成.exe文件进行单元测试并不断提交进度,最后撰写博客。
这是我们在一起进行代码测试分析

八、附加功能
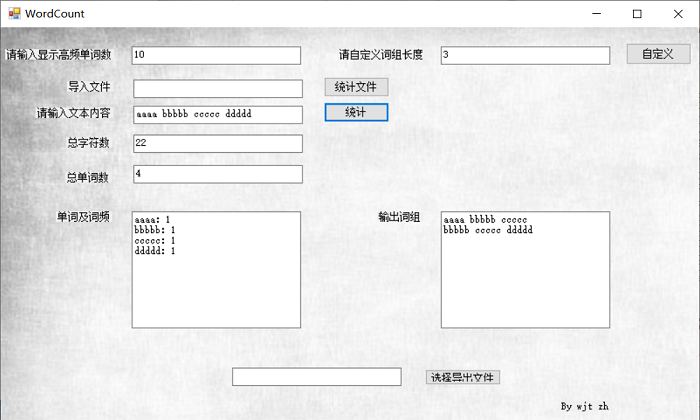
用户交互界面绘制
-
导入单词文本(-i命令行)
![]()
-
直接输入单词
![]()
-
自定义词组长度(-m)
![]()
-
自定义输出高频单词数量(-n)
![]()
-
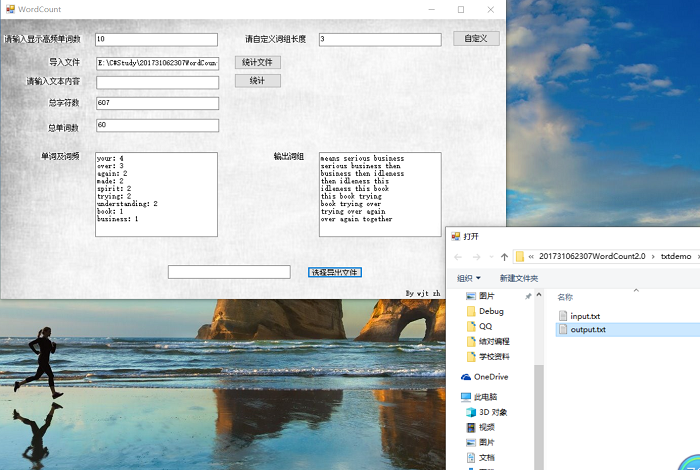
导出统计结果
![]()

总结
1、 两人在合作过程中彼此交流,能更敏锐地发现代码中出现的漏洞,及时改正错误,提高工作效率;
2、 两人合作相较于多人团队合作而言,更能促进彼此的交流,因为两人合作过程中,有什么问题可以直接提出,并在两人商讨之后得到满意的结论,若参与者数量太多,反而不好调配;
3、 虽然我们两个人的水平有一定差距,但是我们彼此信任,共同努力,最终还是实现了一个比较理想的算法,这是我们共同的劳动结果;
4、能和同伴一起交流,一同解决问题是一件挺好的事,两个人一起写代码思路也会更开阔。我觉得如果当一个人没有思路了,或者实现一个比较复杂的逻辑部分代码的时候,可以采用结对编程的方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号