

Python 基础
基础语法
变量标识符命名规范
- 标识符由字母、数字和下划线_组成
- 第一个字符必须是字母或下划线 _ ,不能以数字开头
- 标识符对大小写敏感
- Python关键字不能用作标识符名称
Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
注释
单行注释
在python中,使用# 作为单行注释的符号。从符号 # 开始直到换行为止,# 后面所有的内容都作为注释的内容。
语法如下:
# 注释内容
单行注释可以放在要注释代码的前一行,也可以放在要注释代码的右侧。
第一种形式:
# 要求输入身高,单位为米(m)
height = float(input("请输入您的身高:"))
第二种形式:
height = float(input("请输入您的身高:")) # 要求输入身高,单位为米(m)
多行注释
在python中,并没有一个单独的多行注释标记,而是将包含在一对三单引号('''…''')或者一对三双引号("""…""")之间,并且不属于任何语句的内容都可以视为注释。
语法格式如下:
'''
多行注释内容1
多行注释内容2
多行注释内容3
'''
或者
"""
多行注释内容1
多行注释内容2
多行注释内容3
"""
import 引入模块的方法
在python中使用 import 或者 from...import 来导入响应的模块。
# 将整个模块(some_module)导入
import some_module
# 将整个模块导入 + 起别名
import some_module as aaa
# 从某个模块中导入某个函数或成员
from some_module import some_function
# 从某个模块中导入多个函数或成员
from some_module import some_function_a,some_function_b,some_function_c
# 将某个模块的全部函数和成员导入
from some_module import *
运算法
算术运算符
# +,加
print(3+4) # 7
# -,减
print(7-3) # 4
# *,乘
print(3*4) # 12
# /,除
print(10/5) # 2.0
# //,整除
print(11//5) # 2
# %,取模
print(11%5) # 1
# **,幂运算
print(2**3) # 8
成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False。 | x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False。 | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
a = 10
b = 2
list = [1, 2, 3, 4, 5 ]
print(a in list) # False
print(a not in list) # True
print(b in list) # True
print(b not in list) # False
条件控制
if 语句
语法形式:
if condition_1:
statement_block_1
elif condition_2:
statement_block_2
else:
statement_block_3
- 如果 "condition_1" 为 True 将执行 "statement_block_1" 块语句
- 如果 "condition_1" 为False,将判断 "condition_2"
- 如果"condition_2" 为 True 将执行 "statement_block_2" 块语句
- 如果 "condition_2" 为False,将执行"statement_block_3"块语句
Python 中用 elif 代替了 else if(Java语言中),所以if语句的关键字为:if – elif – else。
使用示例:
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
else:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
match case 语句
在 Python 中没有 switch...case(Java中使用)语句,但在 Python3.10 版本添加了 match...case。
match subject:
case <pattern_1>:
<action_1>
case <pattern_2>:
<action_2>
case <pattern_3>:
<action_3>
case _:
<action_wildcard>
case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
使用示例:
mystatus=400
print(http_error(400)) # "Bad request"
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
一个case中也可以设置多个匹配条件,条件之间使用| 或者 or 隔开,例如:
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case 401 | 403:
return "Not allowed"
case _:
return "Something's wrong with the internet"
数据类型
字典 dict
可通过名称来访问其各个值的数据结构。这种数据结构称为映射(mapping)。字典是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下。键可能是数、字符串或元组。
创建和使用字典
字典以类似于下面的方式表示:
phonebook = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
字典由键及其相应的值组成,这种键-值对称为项(item)。在前面的示例中,键为名字,而
值为电话号码。每个键与其值之间都用冒号( : )分隔,项之间用逗号分隔,而整个字典放在花
括号内。空字典(没有任何项)用两个花括号表示,类似于下面这样: {} 。
在字典中,键是独一无二的,值可以重复
直接创建字典
# 创建字典——直接创建
item_dic = {
"name":"Gumdy",
"age":32
}
print(item_dic) # {'name': 'Gumdy', 'age': 32}
使用dict类创建
可使用函数 dict从其他映射(如其他字典)或键-值对序列创建字典。
# 创建字典——从其他序列创建
items = [('name','Gumdy'),('age',32)]
item_dic = dict(items)
print(item_dic) # {'name': 'Gumdy', 'age': 32}
还可使用关键字实参数:
# 创建字典——dict+关键字参数
items = dict(name = 'Gumby',age = 32)
item_dic = dict(items)
print(item_dic) # {'name': 'Gumdy', 'age': 32}
基本的字典操作
- len(d) 返回字典 d 包含的项(键-值对)数。
- d[k] 返回与键 k 相关联的值。
- d[k] = v 将值 v 关联到键 k 。
- del d[k] 删除键为 k 的项。
- k in d 检查字典 d 是否包含键为 k 的项。
# 学生成绩单
student_report = {'Alice': '100', 'Beth': '98', 'Cecil': '54'}
# 字段项长度
print(len(student_report)) # 3
# 返回键为Alice的值
print(student_report['Alice']) # 100
# 设置键为Cecil的值
student_report['Cecil'] = '87' # {'Alice': '100', 'Beth': '98', 'Cecil': '87'}
print(student_report)
# 如果键不存在,会创建新项
student_report['Juny'] = '92'
print(student_report) # {'Alice': '100', 'Beth': '98', 'Cecil': '87', 'Juny': '92'}
# 删除键为Beth的项
del student_report['Beth']
print(student_report) # {'Alice': '100', 'Cecil': '87', 'Juny': '92'}
# 判断键是否存在
print('Beth' in student_report) # False
print('Juny' in student_report) # True
注意事项
键的类型:字典中的键可以是整数,但并非必须是整数。字典中的键可以是任何不可变
的类型,如浮点数(实数)、字符串或元组。
自动添加:即便是字典中原本没有的键,也可以给它赋值,这将在字典中创建一个新项。
将字符串格式设置功能用于字典
可使用 format_map 来指出你将通过一个映射来提供所需的信息。
phonebook = {'Beth': '9102', 'Alice': '2341', 'Cecil': '3258'}
print("Cecil's phone number is {Cecil}.".format_map(phonebook)) # Cecil's phone number is 3258.
像这样使用字典时,可指定任意数量的转换说明符,条件是所有的字段名都是包含在字典中的键。在模板系统中,这种字符串格式设置方式很有用(下面的示例使用的是HTML):
template = '''
<head><title>{title}</title></head>
<body>
<h1>{title}</h1>
<p>{text}</p>
</body>
'''
data = {'title': 'My Home Page', 'text': 'Welcome to my home page!'}
print(template.format_map(data))
"""
<head><title>My Home Page</title></head>
<body>
<h1>My Home Page</h1>
<p>Welcome to my home page!</p>
</body>
"""
字典常用方法
clear
使用clear() 清除字典所有项。
# clear
student_report = {
'Alice': 100,
'Beth': 100,
'Gumy': 89,
'Cecil': 98
}
student_report.clear()
print(student_report) # {}
copy
方法 copy 返回一个新字典,其包含的键-值对与原来的字典相同(这个方法执行的是浅复制,
因为值本身是原件,而非副本)。
# copy
x = {'username': 'admin', 'machines': ['foo', 'bar', 'baz']}
y = x.copy()
y['username'] = 'mlh'
y['machines'].remove('bar')
print(y)
print(x)
# {'username': 'mlh', 'machines': ['foo', 'baz']}
# {'username': 'admin', 'machines': ['foo', 'baz']}
如上所见,当替换副本中的值时,原件不受影响。然而,如果修改副本中的值(就地修改而不是替换),原件也将发生变化,因为原件指向的也是被修改的值(如这个示例中的’machines’列表所示)。
为避免这种问题,一种办法是执行深复制,即同时复制值及其包含的所有值,等等。为此,可使用模块copy中的函数deepcopy。
from copy import deepcopy
d = {}
d['names'] = ['Alfred', 'Bertrand']
c = d.copy()
dc = deepcopy(d)
d['names'].append('Clive')
print(c) # {'names': ['Alfred', 'Bertrand', 'Clive']}
print(dc) # {'names': ['Alfred', 'Bertrand']}
引用、浅拷贝、深拷贝原理对比(原文)

fromkeys
方法 fromkeys 创建一个新字典,其中包含指定的键,且每个键对应的值都是 None 。
>>> {}.fromkeys(['name', 'age'])
>>> {'age': None, 'name': None}
这个示例首先创建了一个空字典,再对其调用方法 fromkeys 来创建另一个字典,这显得有点多余。你可以不这样做,而是直接对 dict调用方法 fromkeys 。
>>> dict.fromkeys(['name', 'age'])
>>> {'age': None, 'name': None}
如果你不想使用默认值 None ,可提供特定的值。
>>> dict.fromkeys(['name', 'age'], '(unknown)')
>>> {'age': '(unknown)', 'name': '(unknown)'}
get
方法 get 为访问字典项提供了宽松的环境。
通常,如果你试图访问字典中没有的项,将引发错误。
>>> d = {}
>>> print(d['name'])
Traceback (most recent call last):
File "<stdin>", line 1, in ?
KeyError: 'name'
使用 get 来访问不存在的键时,没有引发异常,而是返回 None 。
>>> print(d.get('name'))
None
你可指定默认值,这样将返回你指定的值而不是 None 。
>>> d.get('name', 'N/A')
'N/A'
如果字典包含指定的键, get 的作用将与普通字典查找相同。
>>> d['name'] = 'Eric'
>>> d.get('name')
'Eric'
items
方法 items 返回一个包含所有字典项的列表,其中每个元素都为 (key, value) 的形式。字典项在列表中的排列顺序不确定。
d = {'title': 'Python Web Site', 'url': 'http://www.python.org', 'spam': 0,'dic':{'name':'li','age':32}}
dict_items = d.items()
print(dict_items)
输出:
dict_items([('title', 'Python Web Site'), ('url', 'http://www.python.org'), ('spam', 0), ('dic', {'name': 'li', 'age': 32})])
返回值属于一种名为字典视图的特殊类型。字典视图可用于迭代。
keys
方法 keys 返回一个字典视图,其中包含指定字典中的键。
student_report = {'Alice': 100, 'Beth': 98, 'Cecil': 54}
keys = student_report.keys()
print(keys)
# dict_keys(['Alice', 'Beth', 'Cecil'])
values
方法 values 返回一个由字典中的值组成的字典视图
student_report = {'Alice': 100, 'Beth': 98, 'Cecil': 54}
values = student_report.values()
print(values)
# dict_values([100, 98, 54])
pop
方法 pop 可用于获取与指定键相关联的值,并将该键-值对从字典中删除。
student_report = {'Alice': 100, 'Beth': 98, 'Cecil': 54}
student_report.pop('Alice')
print(student_report)
# {'Beth': 98, 'Cecil': 54}
popitem
方法 popitem 类似于 list.pop ,但 list.pop 弹出列表中的最后一个元素,而 popitem 随机地弹
出一个字典项,因为字典项的顺序是不确定的,没有“最后一个元素”的概念。
student_report = {'Alice': 100, 'Beth': 98, 'Cecil': 54}
i = student_report.popitem()
print(i) # ('Cecil', 54)
print(student_report) # {'Alice': 100, 'Beth': 98}
setdefault
方法 setdefault 有点像 get ,因为它也获取与指定键相关联的值,但除此之外, setdefault 还在字典不包含指定的键时,在字典中添加指定的键-值对。
>>> d = {}
>>> d.setdefault('name', 'N/A')
'N/A'
>>> d
{'name': 'N/A'}
>>> d['name'] = 'Gumby'
>>> d.setdefault('name', 'N/A')
'Gumby'
>>> d
{'name': 'Gumby'}
如果指定的键存在,就返回其值,并保持字典不变。与 get 一样,值是可选的;如果没有指定,默认为 None 。
>>> d = {}
>>> print(d.setdefault('name'))
None
>>> d
{'name': None}
update
方法 update 使用一个字典中的项来更新另一个字典。
d = {'title': 'Python Web Site','url': 'http://www.python.org','changed': 'Mar 14 22:09:15 MET 2016'}
x = {'title': 'Python Language Website','date':'2022-6-10'}
d.update(x)
print(d)
# {'title': 'Python Language Website', 'url': 'http://www.python.org', 'changed': 'Mar 14 22:09:15 MET 2016', 'date': '2022-6-10'}
对于通过参数提供的字典,将其项添加到当前字典中。如果当前字典包含键相同的项,就替换它。
函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
定义一个函数
在Python中,定义一个函数要使用 def 语句,依次写出函数名、括号()、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用 return 语句返回。
def max(a,b):
if a > b:
return a
else:
return b
请注意,return表示返回的意思,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。
函数返回值
有时候函数是没有返回结果的,这个时候从函数获取到的是一个空值None。
def square_of_sum(list):
sum = 0
for i in list:
sum += i**2
print(sum)
result = square_of_sum([1,2,3])
print(result) #None
除了返回None、一个值以外,函数也可以返回多个值,在函数中,如果需要返回多个值,多个值之间使用逗号分隔即可,但是需要注意顺序。
示例:定义一个函数sub_sum(),这个函数接收一个列表作为参数,函数返回列表所有奇数项的和以及所有偶数项的和:
def sub_sum(L):
odd_sum = 0 # 奇数和
even_sum = 0 # 偶数和
for i in L:
if i % 2==0:
even_sum +=i
else:
odd_sum+=i
return odd_sum,even_sum
print(sub_sum(range(0,100))) # (2500, 2450)
函数参数
函数参数可以是任意的数据类型,只要函数内部逻辑可以处理即可。
为了保证函数的正常运行,有时候需要对函数入参进行类型的校验,Python提供isinstance()函数,可以判断参数类型,它接收两个参数,第一个是需要判断的参数,第二个是类型。
isinstance(100, int) # ==> True
isinstance(100.0, int) # ==> False
isinstance('3.1415926', str) # ==> True
任务
请实现函数func,当参数类型为list时,返回list中所有数字类型元素的和,当参数类型为tuple时,返回tuple中所有数字类型元素的乘积。
def func(param):
if(isinstance(param,list)):
sum = 0
for i in param:
sum +=i
return sum
elif(isinstance(param,tuple)):
result = 1
for i in param:
result = result * i
return result
else:
return 0
print(func([1,2,3,4])) # 10
print(func((1,2,3,4))) # 24
注意:
在 def 语句中,位于函数名后面的变量通常称为形参,而调用函数时提供的值称为实参
默认参数
定义函数的时候,还可以有默认参数,默认参数的意思是当这个参数没有传递的时候,参数就使用定义时的默认值。
函数的默认参数的作用是简化调用,你只需要把必须的参数传进去。但是在需要的时候,又可以传入额外的参数来覆盖默认参数值。
我们来定义一个计算 x 的N次方的函数:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
假设计算平方的次数最多,我们就可以把 n 的默认值设定为 2:
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
这样一来,计算平方就不需要传入两个参数了:
power(5) # ==> 25
另外需要注意的是,由于函数的参数按从左到右的顺序匹配,所以默认参数只能定义在必需参数的后面,否则将会出现错误。
练习:请定义一个 greet() 函数,它包含一个默认参数,如果没有传入参数,打印 Hello, world.,如果传入参数,打印Hello, 传入的参数内容:
def greet(s='world.'):
print('Hello, '+s)
greet()
greet('libai')
可变参数
除了默认参数,Python函数还接收一种参数叫做可变参数,可变参数即任意个参数的意思,可变参数通常使用*args来表示。
def func(*args):
print('args length = {}, args = {}'.format(len(args), args))
func('a') # ==> args length = 1, args = ('a',)
func('a', 'b') # ==> args length = 2, args = ('a', 'b')
func('a', 'b', 'c') # ==> args length = 3, args = ('a', 'b', 'c')
注意,在使用上,Python会把可变参数定义为一个tuple,所以在函数内部,把可变参数当作tuple来使用就可以了,比如可以通过位置下标取出对应的元素等。
定义可变参数的目的也是为了简化调用。假设我们要计算任意个数的平均值,就可以定义一个可变参数:
def average(*args):
sum = 0
for item in args:
sum += item
avg = sum / len(args)
return avg
这样,在调用的时候,我们就可以这样写:
average(1, 2) # ==> 1.5
average(1, 2, 2, 3, 4) # ==> 2.4
average()
# 报错
# Traceback (most recent call last):
# ZeroDivisionError: division by zero
在执行average()的时候,却报错了,这是因为在使用可变参数时,没有考虑周全导致的,因为可变参数的长度可能是0,当长度为0的时候,就会出现除0错误。因此需要添加保护的逻辑,这是同学在使用过程中需要特别注意的。
def average(*args):
sum = 0
if len(args)==0:
return 0
for item in args:
sum += item
avg = sum / len(args)
return avg
可变关键字参数
可变参数在使用上确实方便,函数会把可变参数当作tuple去处理,tuple在使用上有一定的局限性,比如有时候想找到特定位置的参数,只能通过下标的方式去寻找,如果顺序发生变化得时候,下标就会失效,函数逻辑就得重新修改实现。
Python函数提供可变关键字参数,对于可变关键字参数,可以通过关键字的名字key找到对应的参数值,想想这和我们之前学习过的什么类似?是的没错,dict,Python会把可变关键字参数当作dict去处理;对于可变关键字参数,一般使用**kwargs来表示。
例如,想要打印一个同学的信息,可以这样处理:
def info(**kwargs):
print('name: {}, gender: {}, age: {}'.format(kwargs.get('name'), kwargs.get('gender'), kwargs.get('age')))
info(name = 'Alice', gender = 'girl', age = 16)
对于一个拥有必需参数,默认参数,可变参数,可变关键字参数的函数,定义顺序是这样的:
def func(param1, param2, param3 = None, *args, **kwargs):
print(param1)
print(param2)
print(param3)
print(args)
print(kwargs)
func(100, 200, 300, 400, 500, name = 'Alice', score = 100)
# ==> 100
# ==> 200
# ==> 300
# ==> (400, 500)
# ==> {'name': 'Alice', 'score': 100}
当然,这么多类型的参数,很容易导致出错,在实际使用上,不建议定义这么多的参数。
练习:编写一个函数,它接受关键字参数name,gender,age三个字符串,分别代表同学的名字、性别和年龄,请把同学的名字、性别和年龄打印出来:
def print_student(**stu):
print('name:{},gender:{},age:{}'.format(stu.get('name'),stu.get('gender'),stu.get('age')))
print_student(name='libai',age='20',gender='1')
# name:libai,gender:1,age:20
递归函数
如果在一个函数内部调用其自身,这个函数就是递归函数。
举个例子,我们来计算阶乘 n! = 1 * 2 * 3 * ... * n,用函数 fact(n)表示,可以看出:
fact(n) = n! = 1 * 2 * 3 * ... * (n-1) * n = (n-1)! * n = fact(n-1) * n
所以,fact(n)可以表示为 n * fact(n-1),只有n=1时需要特殊处理。
于是,fact(n)用递归的方式写出来就是:
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
这个fact(n)就是递归函数。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
请分别使用循环和递归的形式定义函数,求出1~100的和:
# coding=utf-8
def sum_b(n):
if n==1:
return n
return sum_b(n-1)+n
def sum_a(n):
sum = 0
for i in range(1,n+1):
sum +=i
return sum
print(sum_a(100))
print(sum_b(100))
函数编程
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
高阶函数
一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数
一个简单的高阶函数:
def handle_add(x,y,f):
return f(x) + f(y)
当我们调用handle_add(-5, 6, abs)时,参数x,y和f分别接收-5,6和abs,根据函数定义,我们可以推导计算过程为:
x = -5
y = 6
f = abs
f(x) + f(y) ==> abs(-5) + abs(6) ==> 11
return 11
常见 Python 内置高级函数
map
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x**2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
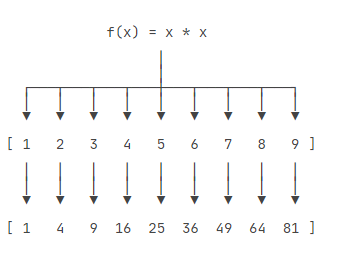
def f(x):
return x*x
my_list = [1,2,3,4,5,6,7,8,9]
r = list(map(f,my_list))
print(r) # [1, 4, 9, 16, 25, 36, 49, 64, 81]
map()传入的第一个参数是f,即函数对象本身。第二个参数是一个可迭代的对象。
由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
print(list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
# ['1', '2', '3', '4', '5', '6', '7', '8', '9']
只需要一行代码。
reduce
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
比方说对一个序列求和,就可以用reduce实现:
from functools import reduce
def add(x,y):
return x+y
my_list = [1,2,3,4,5,6,7,8,9]
r = [reduce(add,my_list)]
print(r) # 45
filter
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
sorted
Python内置的sorted()函数就可以对list进行排序:
>>> sorted([36, 5, -12, 9, -21])
[-21, -12, 5, 9, 36]
此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
print(sorted([36, 5, -12, 9, -21], key=abs))
# [5, 9, -12, -21, 36]
key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。
再比如一个字符串排序的例子:
print(sorted(['bob', 'about', 'Zoo', 'Credit']))
# ['Credit', 'Zoo', 'about', 'bob']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
my_list = ['bob', 'about', 'Zoo', 'Credit']
print(sorted(my_list, key=str.lower))
# ['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
my_list = ['bob', 'about', 'Zoo', 'Credit']
print(sorted(my_list, key=str.lower,reverse=True))
# ['Zoo', 'Credit', 'bob', 'about']
可以看出,高阶函数的抽象能力是非常强大的,而且,核心代码可以保持得非常简洁。
返回函数(闭包)
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum(1, 3, 5, 7, 9)
print(f)
# <function lazy_sum.<locals>.sum at 0x101c6ed90>
print(f())
# 25
在这个例子中,在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为 闭包(Closure) 的程序结构拥有极大的威力。
请再注意一点,当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数:
f1 = lazy_sum(1, 3, 5, 7, 9)
f2 = lazy_sum(1, 3, 5, 7, 9)
print(f1==f2)
# False
f1()和f2()的调用结果互不影响。
注意到返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用,所以,闭包用起来简单,实现起来可不容易。
另一个需要注意的问题是,返回的函数并没有立刻执行,而是直到调用了f()才执行。我们来看一个例子:
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
在上面的例子中,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:
print(f1()) # 9
print(f2()) # 9
print(f3()) # 9
原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
def count():
# 外层创建一个新的函数,来确定绑定的值
def f(j):
def g():
return j*j
return g
fs = []
for i in range(1, 4):
fs.append(f(i)) # f(i)立刻被执行,因此i的当前值被传入f()
return fs
nonlocal
使用闭包,就是内层函数引用了外层函数的局部变量。如果只是读外层变量的值,我们会发现返回的闭包函数调用一切正常:
def inc():
x = 0
def fn():
# 仅读取x的值:
return x + 1
return fn
f = inc()
print(f()) # 1
print(f()) # 1
但是,如果对外层变量赋值,由于Python解释器会把x当作函数fn()的局部变量,它会报错:
def inc():
x = 0
def fn():
# 更新x的值
x = x + 1
return x
return fn
f = inc()
print(f())
print(f())
# x = x + 1
# UnboundLocalError: local variable 'x' referenced before assignment
原因是x作为局部变量并没有初始化,直接计算x+1是不行的。但我们其实是想引用inc()函数内部的x,所以需要在fn()函数内部加一个nonlocal x的声明。加上这个声明后,解释器把fn()的x看作外层函数的局部变量,它已经被初始化了,可以正确计算x+1。
def inc():
x = 0
def fn():
nonlocal x
x = x + 1
return x
return fn
f = inc()
print(f()) # 1
print(f()) # 2
def inc():
func_list = []
x = 0
for i in range(3):
def fn():
nonlocal x
x = x + 1
return x
func_list.append(fn)
return func_list
f1,f2,f3 = inc()
print(f1()) # 1
print(f2()) # 2
print(f3()) # 3
注意
使用闭包时,对外层变量赋值前,需要先使用nonlocal声明该变量不是当前函数的局部变量。
匿名函数 lambda
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
r = [map(lambda x: x * x,my_list)]
print(r)
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数,冒号后面表示函数执行的表达式。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
f = lambda x: x * x
print(f)
# <function <lambda> at 0x000002F3080D3E20>
print(f(5))
# 25
同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y):
return lambda: x * x + y * y
装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
>>> def now():
... print('2015-3-25')
...
>>> f = now
>>> f()
2015-3-25
函数对象有一个__name__属性(注意:是前后各两个下划线),可以拿到函数的名字:
>>> now.__name__
'now'
>>> f.__name__
'now'
现在,假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为 “装饰器”(Decorator)。
在面向对象(OOP)的设计模式中,decorator 被称为装饰模式。OOP 的装饰模式需要通过继承和组合来实现,而 Python 除了能支持 OOP 的 decorator 外,直接从语法层次支持 decorator。Python 的 decorator 可以用函数实现,也可以用类实现。
decorator 可以增强函数的功能,定义起来虽然有点复杂,但使用起来非常灵活和方便。
本质上,decorator 就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的 decorator,可以定义如下:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
观察上面的log,因为它是一个 decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助 Python 的 @语法,把 decorator 置于函数的定义处:
@log
def now():
print('2015-3-25')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
>>> now()
call now():
2015-3-25
把@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
由于log()是一个 decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。
wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。
如果 decorator 本身需要传入参数,那就需要编写一个返回 decorator 的高阶函数,写出来会更复杂。比如,要自定义 log 的文本:
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
这个 3 层嵌套的 decorator 用法如下:
@log('execute')
def now():
print('2015-3-25')
执行结果如下:
>>> now()
execute now():
2015-3-25
和两层嵌套的 decorator 相比,3 层嵌套的效果是这样的:
now = log('execute')(now)
我们来剖析上面的语句,首先执行log('execute'),返回的是decorator函数,再调用返回的函数,参数是now函数,返回值最终是wrapper函数。
以上两种 decorator 的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有__name__等属性,但你去看经过 decorator 装饰之后的函数,它们的__name__已经从原来的'now'变成了'wrapper':
>>> now.__name__
'wrapper'
因为返回的那个wrapper()函数名字就是'wrapper',所以,需要把原始函数的__name__等属性复制到wrapper()函数中,否则,有些依赖函数签名的代码执行就会出错。
不需要编写wrapper.__name__ = func.__name__这样的代码,Python 内置的functools.wraps就是干这个事的,所以,一个完整的 decorator 的写法如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
针对带参数的 decorator:
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
学习
- Python教程-廖雪峰的官方网站 https://www.liaoxuefeng.com/wiki/1016959663602400


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具